Java知识点(2024)
# 一. Java基础
# 为什么Java不支持多继承?
在 Java 语言中,不支持多继承的主要原因是为了简化语言设计和避免潜在的问题(如菱形继承),同时又因为在实际工作中,确实很少用到多继承,所以在 Java 语言中,并不支持多继承。
具体来说,Java 不支持多继承的原因有以下几个:
- 避免菱形继承问题:菱形继承也叫做钻石继承,指的是当一个类从两个不同的父类继承相同的方法,而再次被子类继承时,会导致调用该方法时的二义性。这会造成设计和编译上的困惑和复杂性。
- 简化编程语言:Java 的设计目标之一是简化语言,使其易于学习和使用。多继承在类的设计和使用上增加了复杂性,包括方法解析的问题、命名冲突、继承的混乱等。
- 避免多重继承的层次膨胀:多继承可能导致继承层次的膨胀,如果一个类继承多个父类,再将该类作为基类,子类再继承该类,会造成继承层次的复杂和混乱。
- 避免菱形继承问题:菱形继承也叫做钻石继承,指的是当一个类从两个不同的父类继承相同的方法,而再次被子类继承时,会导致调用该方法时的二义性。这会造成设计和编译上的困惑和复杂性。
# ==和equals有什么区别?
== 任何时候都是基础数据类型都是比较两个值是否相等的,而对于引用类型来说,任何时候都是用来比较两个对象的引用是否相同的,而 equals 对于不同的类来说,它所代表的含义可能是不同的。
例如,对于 Object 来说,== 和 equals 都是一样的,都是用来对比两个对象的引用是否相同的,而 String 或 Integer 等类中,又重写 equals 让其变成了比较值是否相同(而非引用是否相同)。
所以,我们通常会使用 == 来对比两个对象的引用是否相同,而使用 equals 对比两个值是否相同(前提条件是重写了 equals 方法)。
# 返回值不同算方法重载吗?为什么?
返回值不同不算方法重载。
方法重载(Overloading)是指在同一个类中定义了多个同名方法,但它们的参数列表不同,方法重载要求方法:
- 名称相同。
- 参数类型、参数个数或参数顺序,至少有一个不同。
方法重载的目的是提供更多的方法选择,方便程序员根据不同的参数类型或个数来调用合适的方法。
所以,从上面方法的重载要求可以看出,返回值不同是不作为方法重载的依据的。
为什么返回值不同不算方法重载的原因有两个:
- 从程序的执行层面来讲:返回值不同如果作为方法重载,那么会产生歧义;
- 从 JVM 方法签名的角度来讲:返回值并不属于方法签名的一部分,因此无法定位到具体的调用方法。
# String 为什么被设计成不可变的?
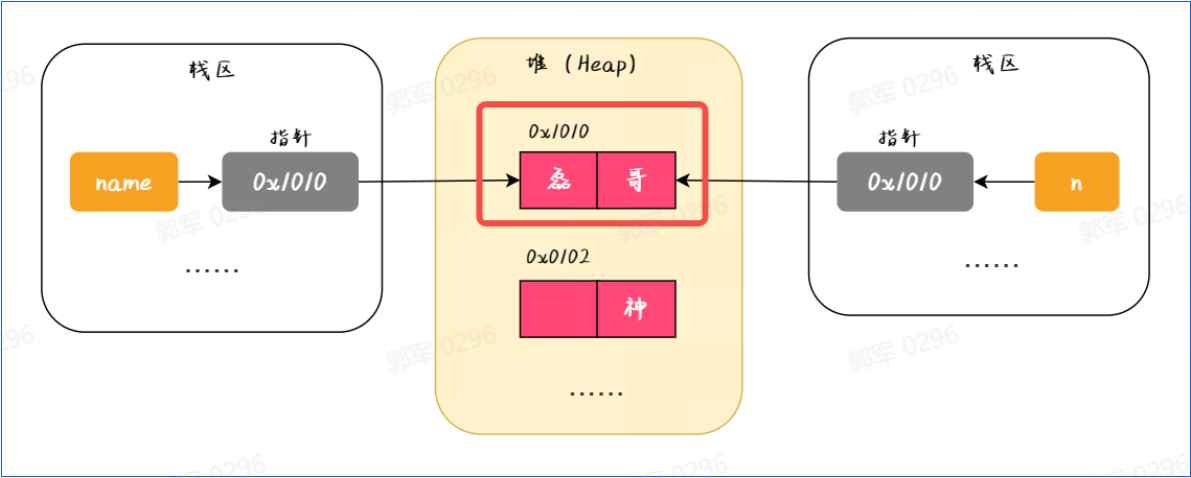
- 安全性:由于 String 是不可变类,即不能被修改,所以使用 final 修饰可以确保 String 类的内部状态不被修改,从而保证了 String 的数据的安全性。例如这幅图中的“0X1010”,系统中只要认定这个指针之后,它就不能被改变了,从而就保证了其安全性。
- 线程安全性:String 是不可变的,因此多个线程可以同时访问和共享 String 对象,而无需进行额外的同步措施。这样可以提高程序的并发性能并减少线程安全问题的出现。线程不安全是由于,多个线程同时修改同一个变量才会导致线程安全问题,而 String 是不可变的,每次操作的都是新对象,那么多个线程操作的就是各自的新对象了,那么也就不会有线程安全问题了。
- 用作键值的准确性:由于 String 的不可变性,它可以安全地用作 HashMap、HashSet 等集合类的键值,这样可以确保散列算法的准确性,避免因修改 String 对象导致哈希值发生变化的情况。
- 性能:String 类在许多地方被广泛使用,使用 final 修饰可以使编译器在编译时对 String 类进行一些优化,从而提高程序的执行效率。
- 安全性:由于 String 是不可变类,即不能被修改,所以使用 final 修饰可以确保 String 类的内部状态不被修改,从而保证了 String 的数据的安全性。例如这幅图中的“0X1010”,系统中只要认定这个指针之后,它就不能被改变了,从而就保证了其安全性。
# String str=new String("javacn.site")创建了几个对象?
创建了一个或两个对象。
- 首先,使用 new 关键字,所以无论如何都会在堆上创建一个对象。
- 之后会判断字符串常量池中是否有“javacn.site”字符串,如果有的话就只创建这一个对象。如果没有的话就会在字符串常量池中创建一个字符串对象,所以就是一个或两个对象。
# 包装类的实际应用场景有哪些?
包装类常用的场景有:
- 用于泛型数据存储
- 用于集合类数据存储
- 方法的参数传递
# 说一下 Integer 高速缓存?
在 Java 中,Integer 类内部实现了一个高速缓存,称为 Integer Cache。这个缓存用于缓存一定范围内的整数对象,以提高性能和减少内存消耗。这个特性在 Java 5 及之后的版本中引入。
Integer 类对于小整数值(默认范围为 -128 到 127)会在初始化时创建缓存,即预先创建这些整数对象并存储在一个数组中。当代码中需要创建一个该范围内的整数对象时,实际上是从缓存中获取已存在的对象,而不是每次都创建一个新的对象。这样做的好处是,对于常用的小整数值,不会产生大量的重复对象,从而节省了内存和提高了性能。
这个缓存的范围可以通过 JVM 参数进行调整。例如,可以通过设置 -XX:AutoBoxCacheMax=<size> 来增加缓存的范围。
值得注意的是,对于超过缓存范围的整数值,每次都会创建一个新的 Integer 对象,而不会从缓存中获取。因此,使用整数时要注意是否处于缓存范围,避免在比较整数对象时产生不符合预期的结果
# 为什么重写 equals 时,一定要重写 hashCode?
equals 和 hashCode 是用来协同判断两个对象是否相等的,如果只重写了 equals 方法,而不重写 hashCode,就会导致某些场景下程序异常。
比如给 Set 中插入两个对象时,因为这两个对象引用地址不同,但属性值都相同,那么正常情况下,因为不能重复插入才对。然而,因为未重写 hashCode,所以导致判断 hashCode 不同,就认为它们是不同的对象,这样就会将两个相同的对象都存储到 Set 集合中,这显然是有问题的,因为使用 Set 集合就是用来去重的,结果还存入了两个相同的对象。
# 什么是类型檫除?它有什么好处?
类型擦除(Type Erasure)也叫做泛型檫除,它是指在 Java 中,泛型的参数类型在编译后,被擦除掉的机制。例如编译器会将“new ArrayList<Integer>()”变为“new ArrayList()”,这就是类型檫除。
类型檫除的好处是可以直接兼容之前的代码、节约内存空间,以及 JVM 层面实现更加简单。
举个类型檫除的具体例子,例如以下代码(编译器会将 List<String> 擦除为 List)。类型檫除有以下几个主要优点:
- 兼容之前代码: JDK 5 之前没有泛型,所以在引入泛型后,需要考虑兼容现有代码,而不是大规模的修改现有代码。
- 节约内存:在运行时,泛型类型的参数信息被擦除,因此泛型类在内存占用方面和非泛型类是一样的。这使得泛型的类型参数对应的内存开销为零,从而节约了内存空间。
- 实现简单:类型擦除只需要在编译时去掉类型即可,无需在 JVM 层面添加泛型支持,所以技术实现比较简单。
# 什么是克隆?深克隆和浅克隆有什么区别?
克隆是指创建一个对象的副本,使副本具有与原始对象相同的属性和状态。在计算机编程中,克隆是一种常见的操作,用于复制数据、对象或数据结构,以便在不影响原始数据的情况下进行操作、修改或分发。
克隆最典型的使用场景是原型模式,原型模式是一种创建型设计模式,用于创建对象的克隆副本,而无需依赖复杂的实例化过程。原型模式通过复制现有对象的原型来创建新的对象,从而避免了通过构造函数创建对象的开销和复杂性。
而克隆又分为深克隆和浅克隆:
- 深克隆(Deep Clone)是将原型对象中的所有类型,无论是值类型还是引用类型,都复制一份给克隆对象,也就是说深克隆会把原型对象和原型对象所引用的对象,都复制一份给克隆对象。
- 浅克隆(Shadow Clone)是把原型对象中成员变量为值类型的属性都复制给克隆对象,把原型对象中成员变量为引用类型的引用地址也复制给克隆对象,也就是原型对象中如果有成员变量为引用对象,则此引用对象的地址是共享给原型对象和克隆对象的。简单来说就是浅克隆只会复制原型对象,但不会复制它所引用的对象。
深克隆和浅克隆的主要区别:深克隆会复制原型对象和它所引用所有对象,而浅克隆只会复制原型对象。
# Java是值传递还是引用传递?
值传递(Pass by value)和引用传递(Pass by reference)是关于参数传递方式的两个概念。
值传递:将传递参数的值,复制一份到方法的参数中。换句话说,值传递的是原始数据的一个副本,而不是原始数据本身。
引用传递:将实际参数的引用(内存地址)传递给方法,这意味着方法内部对参数的修改会影响原始数据本身,也就是说引用传递传递的是原始数据,而非原始数据的副本。
也就是,值传递和引用传递最大的区别是传递的是自身,还是复制的副本,如果传递的是自身则为引用传递,如果传递的是复制的副本则为值传递。
在 Java 语言中,只有值传递,没有引用传递!
# 反射的使用场景有哪些?如何实现反射?
反射(Reflection)是指在程序运行时获取和操作类的一种能力。通过反射机制,可以在运行时动态地创建对象、调用方法、访问和修改属性,以及获取类的信息。
反射的主要目的是使程序能够在编译时不知道类的具体信息的情况下,动态地运行和操作类。它提供了一种机制,可以在运行时检查和操作类的信息。
反射使用场景
使用反射我们可以实现动态代理(扩充程序的功能),可以实现设计更多的类库和框架,例如以下这些:
- Spring AOP 功能:Spring 是一个功能强大的企业级开发框架,它广泛使用反射来实现依赖注入、AOP(面向切面编程)等功能。通过反射,Spring 能够在运行时动态地创建和管理对象,并将依赖关系注入到对象中。
- MyBaits Plus 框架:MyBatis Plus 是一个强大的 ORM(对象关系映射)框架,它是基于 MyBatis 框架的增强框架,MyBatis Plus 中大量使用了反射机制,例如 MyBatis Plus 通过反射来分析实体类的字段和方法,从而动态地生成 SQL 语句和处理数据库操作。通过反射,可以获取实体类的属性、字段名称、数据类型等信息,并将其映射到数据库表的列。
- JUnit 测试框架:JUnit 是用于 Java 单元测试的常用框架,它使用反射来实例化测试类、调用测试方法,并进行断言和校验。通过反射,JUnit 能够在运行时动态地执行测试代码,并获取测试方法的结果。
如何实现反射?
反射的第一步是先获取类,例如使用 Class.forName("xxx") 获取,然后可以通过 getDeclaredFields 方法获取类中的所有字段,以及可以通过 getDeclaredMethods 方法得到类中的所有方法,之后可以使用 getDeclaredConstructor 方法得到构造方法对象 Constructor,然后可以通过构造方法对象 Constructor 提供的 newInstance 得到类对象,然后就可以使用类对象实例了。
# 反射有什么优缺点?为什么反射执行的比较慢?
反射的优点:
- 动态性:反射使得程序在运行时可以动态获取类的信息和操作类或对象,使得代码更加灵活和通用。
- 通用性:反射可以处理不同类的对象,使得代码更加通用和复用。
反射的缺点:
- 性能较低:由于反射需要在运行时动态获取信息和调用方法,会导致性能相对较低,因此在性能要求较高的场景下,应谨慎使用反射。
- 安全性问题:反射可以访问和修改对象的私有字段和方法,这可能导致安全性问题。在使用反射时,需要注意安全性问题,避免滥用反射带来的潜在风险。
为什么反射执行比较慢?
反射执行慢的主要原因是反射涉及到了运行时类型检查、访问权限检查、动态方法调用和一些额外的操作,这些操作都会导致反射的执行比较慢。
具体来说,反射的执行要经历以下过程:
- 运行时类型检查:在使用反射时,需要在运行时进行类型检查,以确保调用的方法、访问的属性等是有效的。这涉及到了额外的运行时判断和类型转换。
- 访问权限检查:Java 的反射机制可以突破访问权限的限制,可以访问私有的方法、属性等。因此,在执行反射操作时,需要进行额外的权限检查和处理,这会带来额外的开销。
- 方法调用的动态性:对于通过反射调用的方法,需要在运行时动态地解析方法的签名,并确定要调用的具体方法。这需要进行方法查找和动态绑定的过程,相对于直接调用方法而言更为耗时。
- 临时对象的创建:反射会导致对象的多次创建和临时对象的产生,这在某些情况下可能会引起额外的开销。反射操作一般不会被 JVM 的即时编译器优化,也没有缓存和重用,所以也会比较慢。
- 禁止的编译器优化:由于反射是在运行时进行的,而不是在编译时,这意味着编译器无法进行静态优化和代码优化。导致反射的执行效率相对较低。
# 动态代理的使用场景有哪些?它和静态代理有什么区别?
动态代理的常见使用场景有以下这些:
- AOP(面向切面编程):动态代理可以用于实现横切逻辑,例如日志记录、性能监控、事务管理等。通过在方法执行前后插入代理逻辑,可以实现对目标方法的增强。
- 远程方法调用(RPC):动态代理可以用于远程方法调用框架,例如使用代理对象作为客户端的远程服务代理,将调用转发给实际的远程服务。
- 动态权限校验:动态代理可以用于动态权限校验,例如在访问某个受限资源时,使用代理对象判断用户是否具有相应的权限。
PS:例如,Spring 中的 AOP、声明式事务、MyBatis/MyBatis Plus 中的分页插件、Dubbo、Openfeign 都是动态代理的典型使用场景。
动态代理 VS 静态代理
动态代理和静态代理的最大的区别是:静态代理是编译期确定的代理类,但是动态代理却是运行期确定的代理类,也就是说:
- 静态代理其实就是事先写好代理类,可以手工编写也可以使用工具生成,但它的缺点是每个业务类都要对应一个代理类,特别不灵活,也不方便。
- 动态代理是在程序运行期,动态的创建目标对象的代理对象,并对目标对象中的方法进行功能性增强的一种技术。
所以,动态代理和静态代理的效果都是一样的,但静态代理使用麻烦,而动态代理使用简单,后者也是现在编程中实现代理的主流方式。
# BIO、NIO、AIO有什么区别?同步非阻塞和异步非阻塞有什么区别?
IO(Input/Output)是指输入/输出,用于描述计算机与外部设备(如文件、网络、键盘、显示器等)之间的数据交换过程。
计算机在运行过程中,需要与外部世界进行数据的输入和输出。例如,从文件中读取数据、将数据写入到网络传输中、从键盘接收用户的输入等都属于 IO 操作。
需要 IO 的主要原因是:
- 数据持久化:将数据从内存写入到磁盘或其他存储介质中,实现数据的持久化和长期存储。
- 数据交互:与外部设备进行数据的输入和输出,在计算机与用户、计算机与计算机之间传输数据。
- 程序与外部设备的交互:程序需要和外部设备(如键盘、鼠标、显示器、网络等)进行交互,接收用户输入,展示输出结果。
IO 操作是计算机系统中的重要组成部分,它通过数据的输入和输出实现了与外部设备的交互和数据的持久化。在计算机软件开发和系统运行中,IO 是不可或缺的一部分。
简单来说,BIO 就是传统 IO 包,它诞生的最早,但它是同步、阻塞的;所以在 JDK 1.4 又有了 NIO, NIO 是对 BIO 的改进提供了多路复用的同步非阻塞 IO,而 AIO 是 NIO 的升级,提供了异步非阻塞 IO。
它们的具体区别如下:
- BIO(Blocking I/O):同步阻塞 IO,传统的 java.io 包,它是基于流模型实现的,交互的方式是同步阻塞方式,也就是说在读入输入流或者输出流时,在读写动作完成之前,线程会一直阻塞在那里,它们之间的调用是可靠的线性顺序。它的优点是代码比较简单、直观;缺点是 IO 的效率和扩展性很低,容易成为应用性能瓶颈。
- NIO(Non-blocking I/O):同步非阻塞 IO,Java 1.4 引入的 java.nio 包,提供了 Channel、Selector、Buffer 等新的抽象,可以构建多路复用的、同步非阻塞 IO 程序,同时提供了更接近操作系统底层高性能的数据操作方式。
- AIO(Asynchronous I/O):异步非阻塞 IO,Java 1.7 之后引入的包,是 NIO 的升级版本,异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
所以,简单来说:BIO 是同步阻塞 IO;NIO 是同步非阻塞 IO;AIO 是异步非阻塞 IO。
同步非阻塞和异步非阻塞有什么区别?
同步非阻塞和异步非阻塞最大的区别是,同步非阻塞通常使用轮询的方式来获取结果,然后再执行下一步操作。而异步非阻塞注册了异步事件之后,就去做其他事去了(无需一直轮询获取结果),当程序执行返回结果后,操作系统或程序会调用异步回调方法继续后续流程的执行。例如 NIO 就是同步非阻塞 IO,而 AIO 则属于异步非阻塞 IO。
# Exception和Error有什么关联和区别?
Exception 和 Error 的关联是,它们都是继承了 Throwable 类(都属于 Throwable 类的子类),在 Java 中只有 Throwable 类型的实例才可以被抛出(throw)或者捕获(catch),它是异常处理机制的基本组成类型。
它们的区别主要有以下几点:
- 级别不同:Exception 是表示可恢复的异常情况,而 Error 表示不可恢复的严重错误。
- 来源不同:Exception 通常由应用程序代码引起,表示可预料的异常情况,如输入错误、文件不存在等。而 Error 通常由 Java 虚拟机(JVM)引起,表示严重的系统层面的错误(如内存溢出、栈溢出等),通常无法通过代码来处理。
- 代码处理不同:Exception 通常需要程序员在代码中明确地捕获并处理,以防止应用程序的崩溃或异常终止。而 Error 通常是无法通过代码处理的,它表示系统出现了严重的问题,无法恢复。
- 程序影响不同:Exception 是一种正常的控制流程,可能会影响应用程序的正常执行,但不会导致应用程序终止。而 Error 是一种严重的问题,可能会导致应用程序的崩溃或终止。
也就是说,Exception 和 Error 的关联是,它们都是继承了 Throwable 类(都属于 Throwable 类的子类),而 Exception 表示可以通过代码处理的可恢复的异常情况,通常由应用程序引起;而 Error 表示不可恢复的严重错误,通常由 Java 虚拟机(JVM)引起,无法通过代码处理。
# 抽象类和接口有什么区别?
接口和抽象类都是用来定义对象公共行为的,二者的主要区别有以下几点不同:
- 类型扩展不同:抽象类是单继承,而接口是多继承(多实现)。
- 方法/属性访问控制符不同:抽象类方法和属性使用访问修饰符无限制,只是抽象类中的抽象方法不能被 private 修饰;而接口有限制,接口默认的是 public 控制符,不能使用其他修饰符。
- 方法实现不同:抽象类中的普通方法必须有实现,抽象方法必须没有实现;而接口中普通方法不能有实现(不考虑 JDK 8 中 defualt 默认方法)。
- 使用目的不同:接口是为了定义规范,而抽象类是为了复用代码。
使用抽象类是用了复用代码,而使用接口是为了定义规范。它和接口的区别主要体现在:类型扩展不同、方法/属性访问控制符不同、方法实现不同,以及使用目的不同。
# 二. 集合模块
# Java中线程安全的容器有哪些?它们分别是怎么保证安全性的?
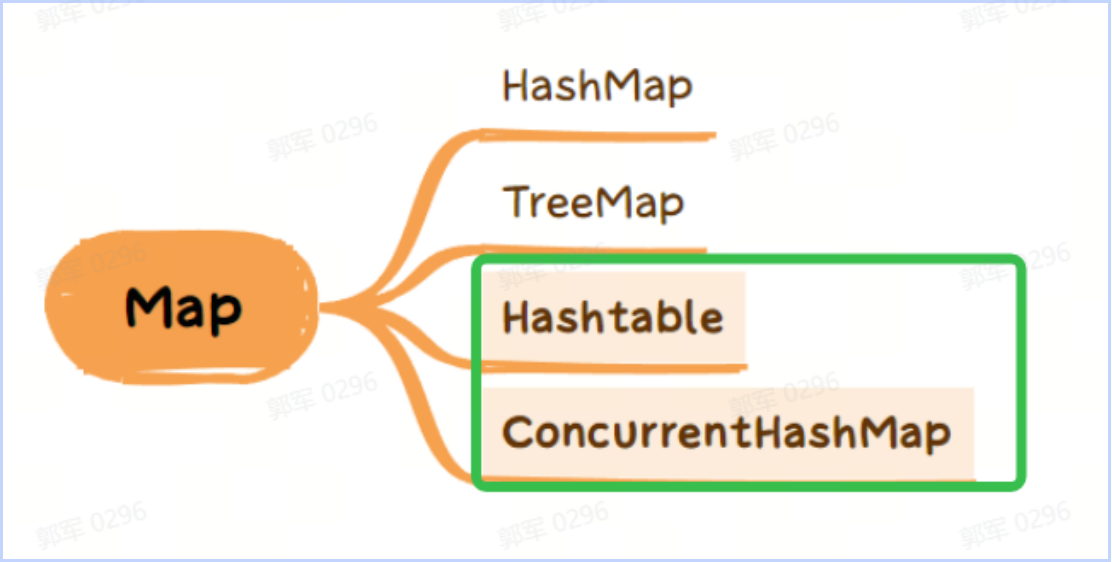
Java 中常见的线程安全的容器有以下这些(绿色勾中的为安全容器,其他为非安全容器):
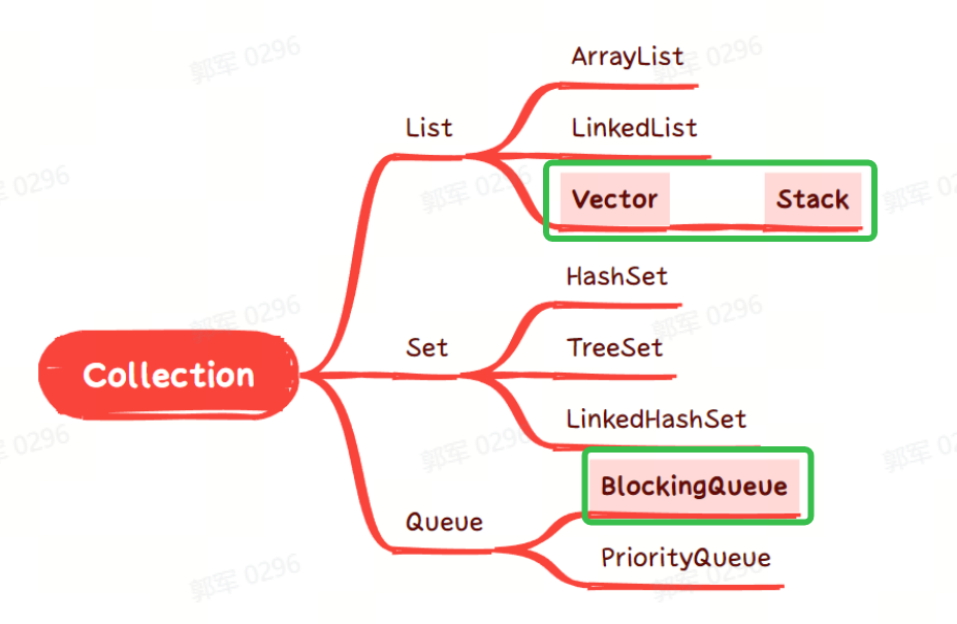
- Vector 和 Stack 是通过 synchronized 加锁写入方法来保证线程安全的。
- BlockingQueue 是通过 ReentrantLock 来保证线程安全的,如下图所示(ArrayBlockQueue 是 BlockingQueue 的子类):
- Hashtable 是通过 synchronized 保证线程安全的。
- ConcurrentHashMap JDK 1.7 是通过分段锁保证线程安全的,之后是通过 synchronized 或 CAS 保证线程安全的。
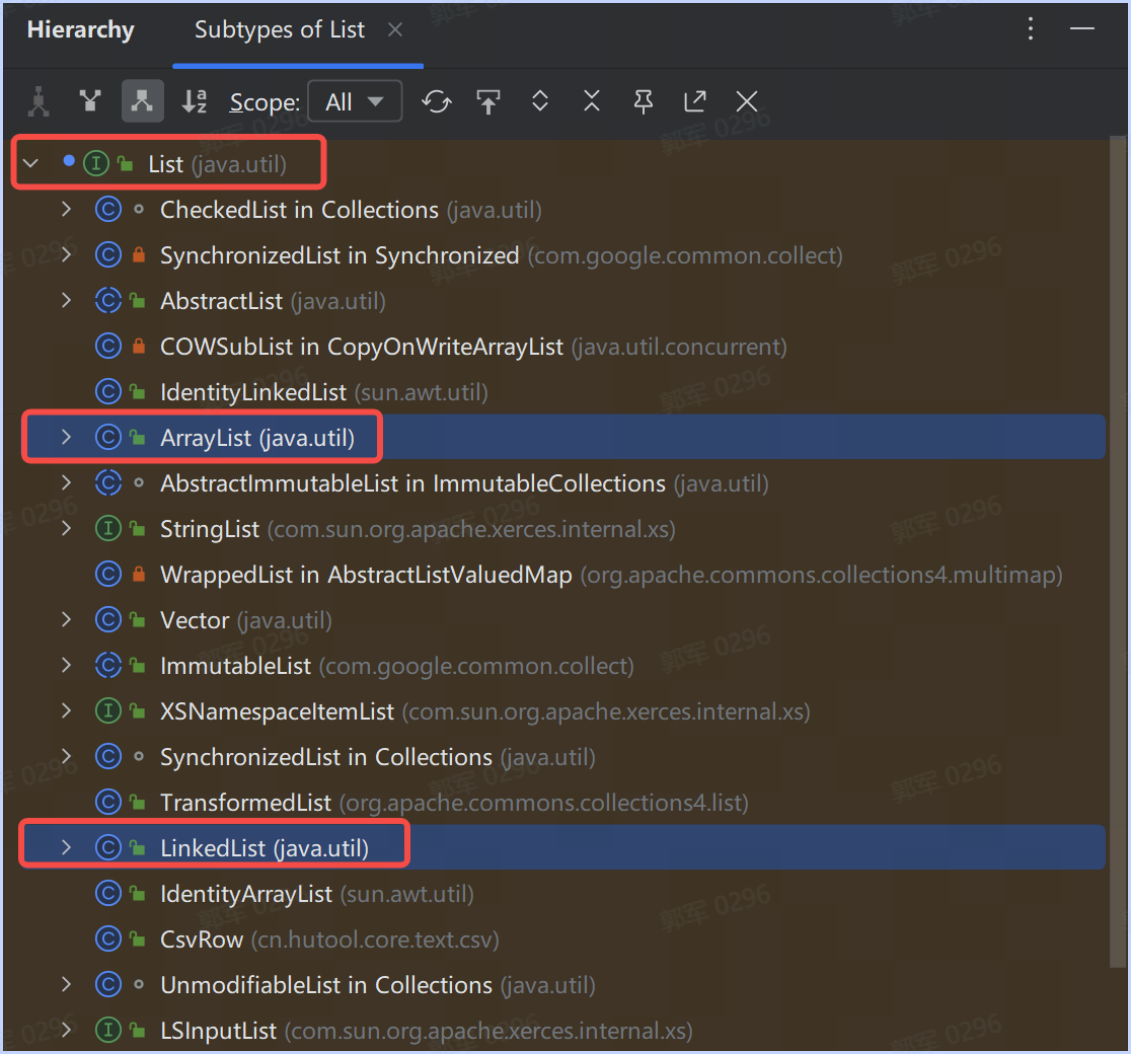
# ArrayList和LinkedList有什么区别?
ArrayList 和 LinkedList 是 Java 中常用的集合类,它们都实现了 List 接口,如下图所示:
但二者有以下几点不同:
底层数据结构实现不同:
- ArrayList 底层使用数组实现,它通过一个可调整大小的数组来存储元素。
- LinkedList 底层使用双向链表实现,它通过链表节点来连接元素。
插入和删除的效率不同:
- ArrayList 对于插入和删除操作的性能相对较低,因为需要进行元素的移动和数组的重新分配,尤其是在 ArrayList 列表最前面插入和删除时,效率最慢。
- LinkedList 对于插入和删除操作会比 ArrayList 更好,因为它只需要修改相邻节点的指针即可。
随机访问效率不同:
- ArrayList 对于随机访问(根据索引获取元素)具有更好的性能,因为可以通过索引直接计算元素在数组中的位置,时间复杂度为 O(1)。
- LinkedList 对于随机访问的性能较差,需要通过链表节点一个个遍历找到对应的索引位置,时间复杂度为 O(n)。
内存要求和占用空间大小不同:
- ArrayList 在内存中需要连续的存储空间,因此在存储大量数据时,需要有大块的连续内存空间,所以对内存要求较高(不能有太多的内存碎片)。
- LinkedList 不要求有连续的内存空间,它的链表是逻辑的先后顺序,每个元素用额外的空间来存储指向前、后的节点指针,所以,LinkedList 相对而言会占用更多的内存空间。
因此,在多查的场景下考虑使用 ArrayList,而在插入和删除比较多的场景下考虑使用 LinkedList。
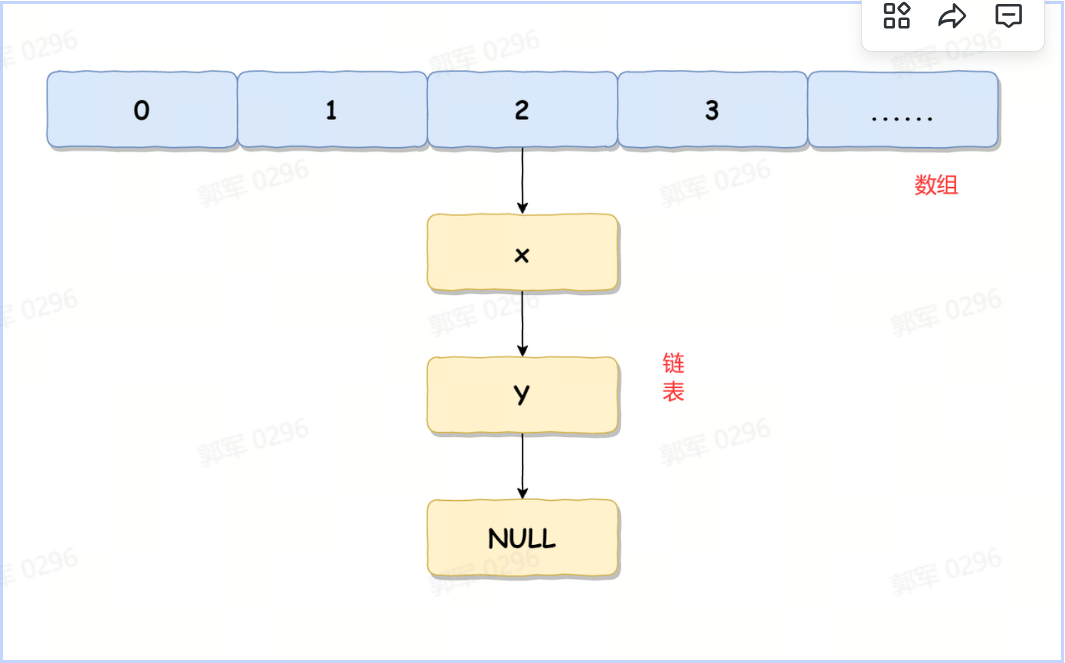
# HashMap底层是如何实现的?
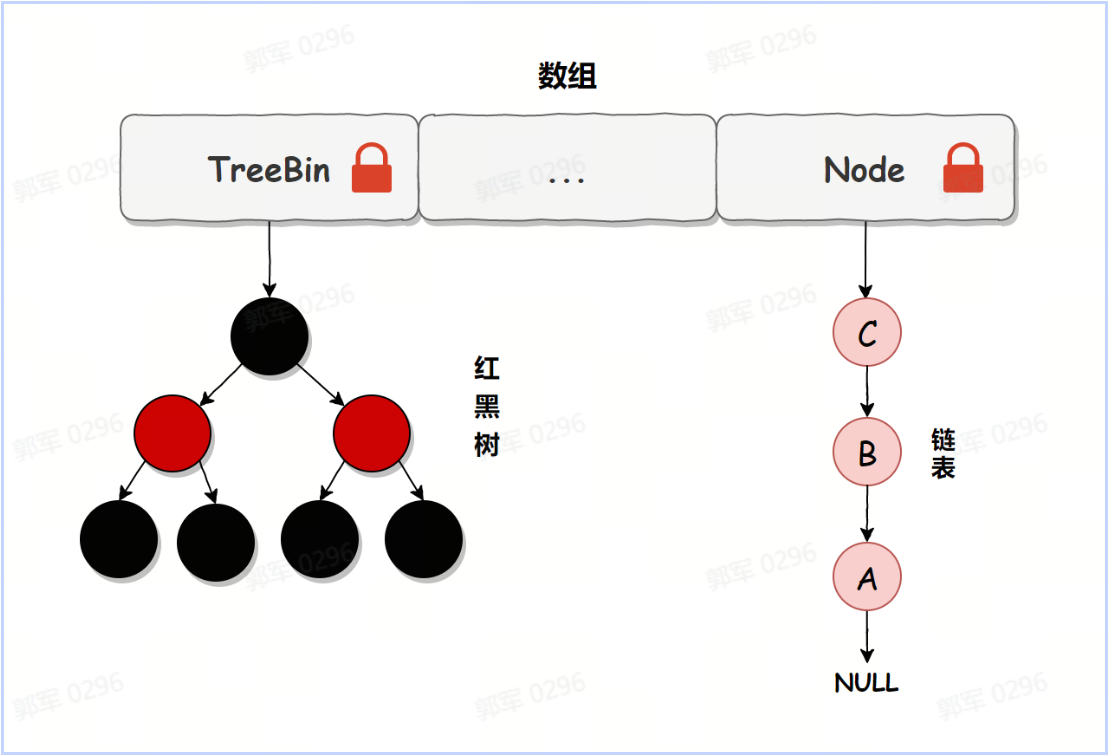
不同的 JDK 版本,HashMap 的底层实现是不一样的,总体来说:在 JDK 1.8 之前(不包含 JDK 1.8),HashMap 使用的是数组 + 链表实现的,而 JDK 1.8 之后(包含 JDK 1.8)使用的是数组 + 链表或红黑树实现的。
HashMap 在 JDK 1.8 以前(不包含 JDK 1.8)的版本中的实现如下图所示:
HashMap 在 JDK 1.8+ 中(包含 JDK 1.8)的实现如下图所示:

HashMap 在 JDK 1.8 之前(不包含 JDK 1.8),使用的是数组 + 链表实现的;而 JDK 1.8 之后(包含 JDK 1.8)使用的是数组 + 链表或红黑树实现的。
# HashMap为什么要使用红黑树而非其他数据结构来存储数据?
HashMap 中之所以使用红黑树,是因为红黑树最合适做 HashMap 多节点的数据存储和查询。因为使用二叉搜索树在某些情况下会退化为链表,所以它的查询效率可能会存在问题;而使用 AVL 树,在添加或删除时,效率又不如红黑树,所以选择使用红黑树是 HashMap 最合适的选择。
为什么要这么说呢?
我们这里采用排除法来帮你理解这个问题,对于 HashMap 而言,我们可以使用以下数据结构来进行数据的存储:
二叉搜索树(Binary Search Tree):是一种特殊的二叉树,每个节点的左子树上的节点值都小于该节点的值,右子树上的节点值都大于该节点的值。但二叉搜索树在极端的情况下会退化成链表结构,所以并不是最适合的存储结构。
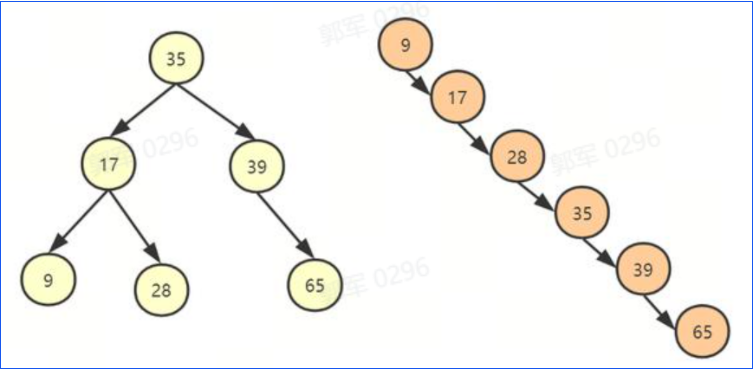
AVL 树(Balanced Binary Tree):在二叉搜索树的基础上,增加了平衡性的要求,保持左右子树的高度差不超过 1,通过旋转操作来保持树的平衡。但是因为 AVL 树插入节点或者删除节点,整体的性能不如红黑树,所以也不是最合适的选择。在 AVL 树中,每个节点的平衡因子是其左子树高度和右子树高度的差值。平衡因子只能为 -1、0、1,任何节点的平衡因子超过这个范围,就需要通过旋转操作进行平衡调整,使得整个树重新平衡。而红黑树的平衡要求相对宽松,插入和删除操作会导致较少的旋转操作,因此在频繁的插入和删除操作场景下,红黑树的性能可能略优于 AVL 树。
红黑树(Red-Black Tree):也是一种具有平衡性质的二叉搜索树。通过约束节点的颜色(红色或黑色)和一些平衡性质来保持树的平衡。红黑树它的查找性能接近于 AVL 树,但增、删节点的效率又优于 AVL 树,因此使用红黑树替代链表是 HashMap 最佳的选择。
所以综合来看,HashMap 因为数据量相对来说比较少,所以使用红黑树是最合适的选择(比二叉搜索树查询快,而 AVL 树插入和删除效率高),数据量也不会像 MySQL 中的表一样有很多的数据,所以用不上结构更复杂的多叉树,那么红黑树就是最好的选择了。
# 什么是负载因子?它的值为什么是0.75?
负载因子(Load Factor)也叫扩容因子,它是一个用于控制 HashMap 何时进行扩容的参数。当 HashMap 中存储的键值对数量,超过了 HashMap 总容量乘以扩容因子时,HashMap 就会进行扩容操作。
例如 HashMap 的总容量为 16,扩容因子为 0.75,那么当 HashMap 中存储的键值对大于 12(16*0.75)时,HashMap 就会进行扩容。
PS:负载因子的值是 0 到 1 之间(大于 0,小于 1)。
为什么负载因子是 0.75?
- 当负载因子比较大的时候,那么扩容就会比较晚,空间利用率就会比较高,但发生哈希冲突的概率就会增大,那么插入的时间就会变长;
- 当负载因子比较小的时候,那么扩容会比较早,发生哈希冲突的概率会变小,插入的时间会变快,但空间利用率就会很低。
因此选择 0.75 是空间和时间效率的一种平衡。
# HashMap是线程安全的吗?说下具体原因?
HashMap 是线程不安全的,原因主要体现在以下两个方面:
HashMap 在 JDK 1.7 之前(包含 JDK 1.7)它线程不安全的原因体现在两个方面:
- HashMap 可能会造成环形链表,导致程序执行死循环。
- 多线程下并发执行,可能会导致数据覆盖。 HashMap 在 JDK 1.8 之后(包含 JDK 1.8)不再有死循环问题,但依旧存在数据覆盖问题。
所以,HashMap 是线程不安全的。
# HashMap会导致CPU 100%?什么场景下会出现这个问题?
HashMap 在极端情况下可能会导致 CPU 100%,这个问题出现在 JDK 1.8 之前,当链表在多线程并发扩容时,可能会导致链表死循环,而死循环会导致 CPU 一直执行,从而慢慢飙升为 100% 的情况,发生这种情况,需要同事满足以下三个条件:
多线程同时执行添加操作。
触发 HashMap 扩容机制。 JDK 1.7 之前(包含 JDK 1.7)采用的是头插法。 以下是 HashMap 发生死循环的具体过程。 在 JDK 1.7 中 HashMap 的底层数据实现是数组 + 链表的方式,如下图所示:
 而 HashMap 在数据添加时使用的是头插入,如下图所示:
而 HashMap 在数据添加时使用的是头插入,如下图所示:
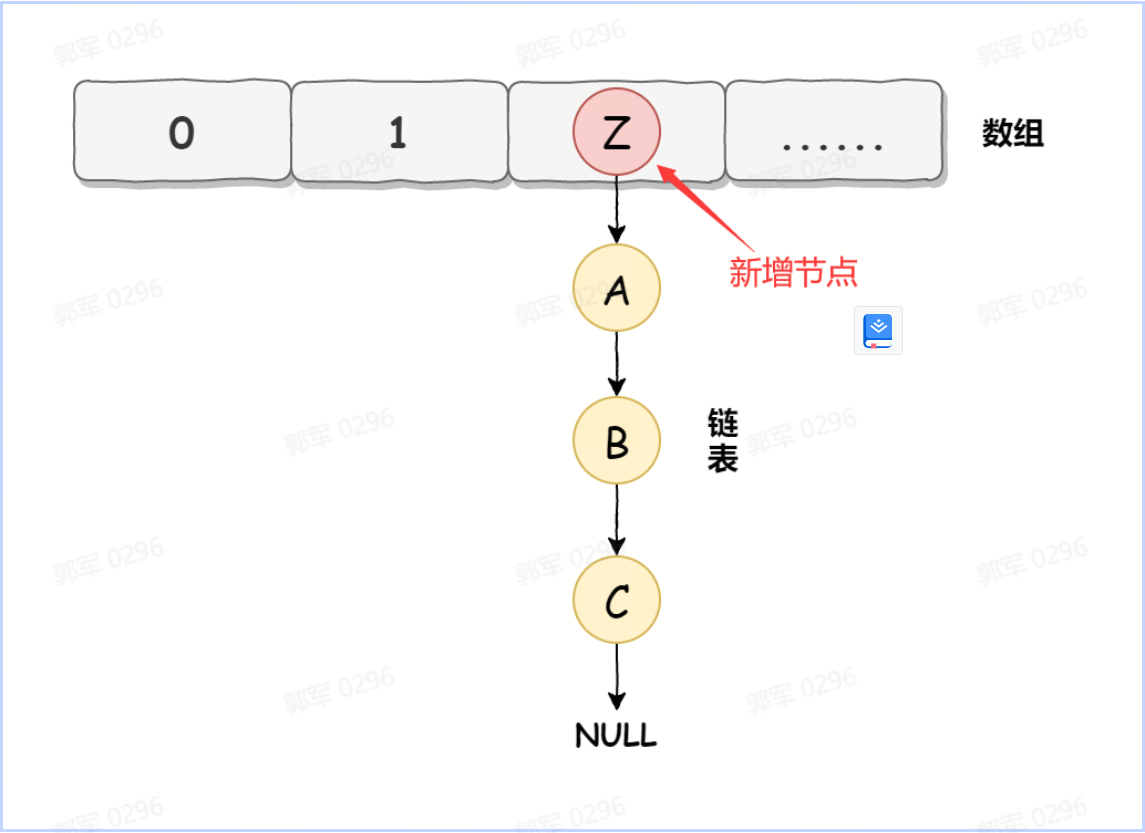 HashMap 正常情况下的扩容实现如下图所示:
HashMap 正常情况下的扩容实现如下图所示:
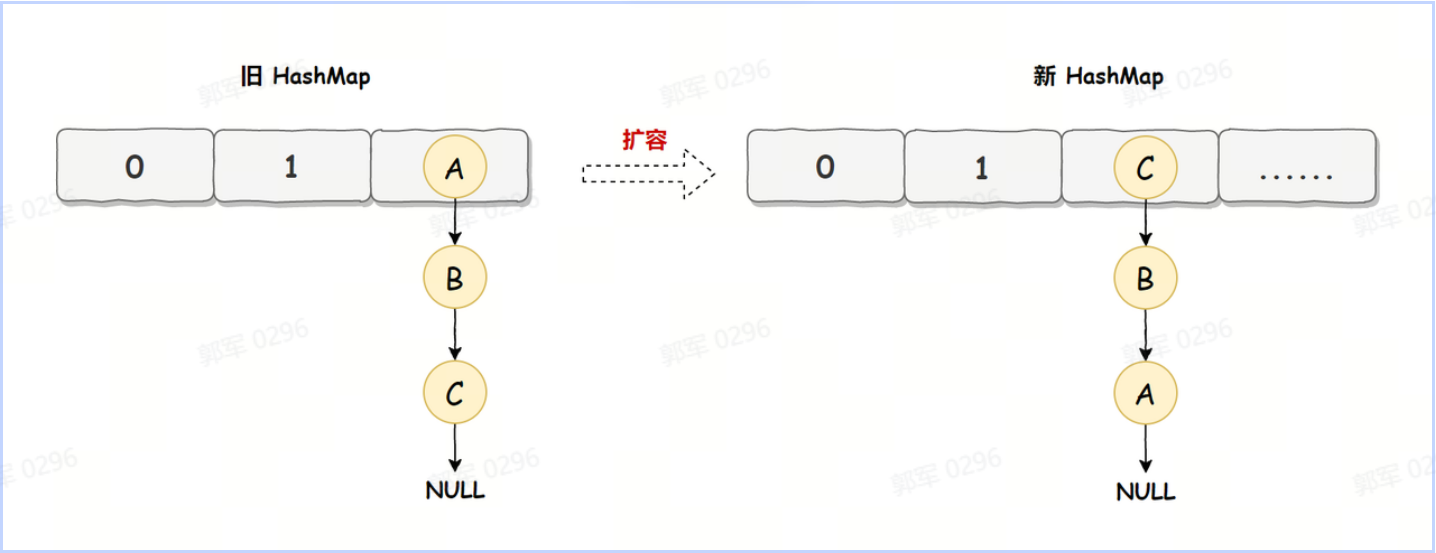 旧 HashMap 的节点会依次转移到新 HashMap 中,旧 HashMap 转移的顺序是 A、B、C,而新 HashMap 使用的是头插法,所以最终在新 HashMap 中的顺序是 C、B、A,也就是上图展示的那样。有了这些前置知识之后,咱们来看死循环是如何诞生的?
旧 HashMap 的节点会依次转移到新 HashMap 中,旧 HashMap 转移的顺序是 A、B、C,而新 HashMap 使用的是头插法,所以最终在新 HashMap 中的顺序是 C、B、A,也就是上图展示的那样。有了这些前置知识之后,咱们来看死循环是如何诞生的?死循环执行步骤1
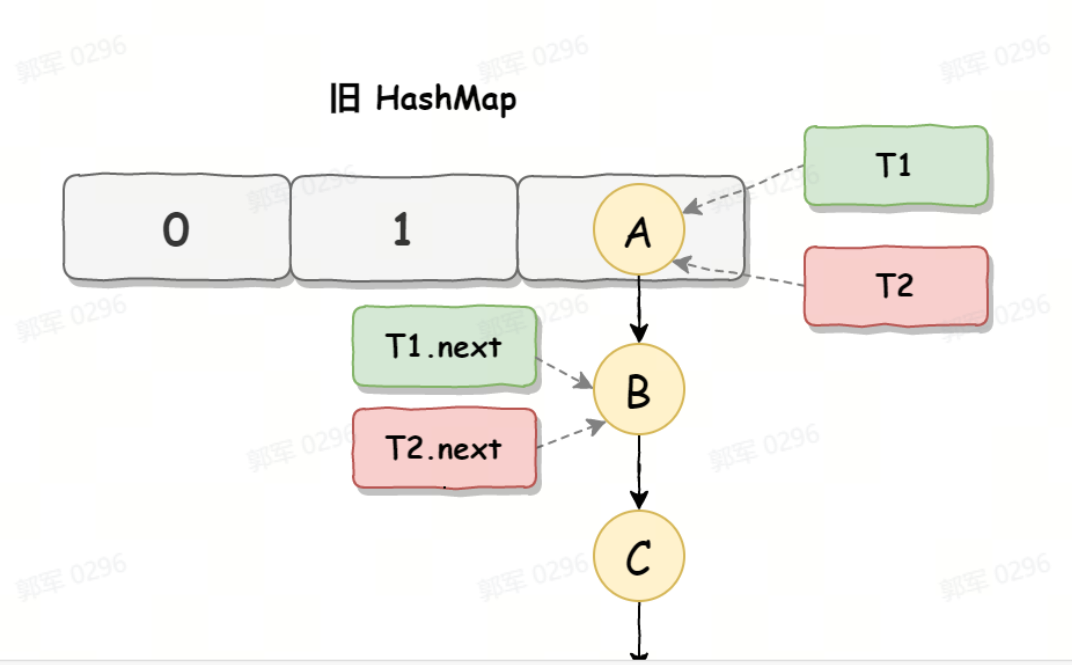
死循环是因为并发 HashMap 扩容导致的,并发扩容的第一步,线程 T1 和线程 T2 要对 HashMap 进行扩容操作,此时 T1 和 T2 指向的是链表的头结点元素 A,而 T1 和 T2 的下一个节点,也就是 T1.next 和 T2.next 指向的是 B 节点,如下图所示:
死循环执行步骤2
死循环的第二步操作是,线程 T2 时间片用完进入休眠状态,而线程 T1 开始执行扩容操作,一直到线程 T1 扩容完成后,线程 T2 才被唤醒,扩容之后的场景如下图所示:
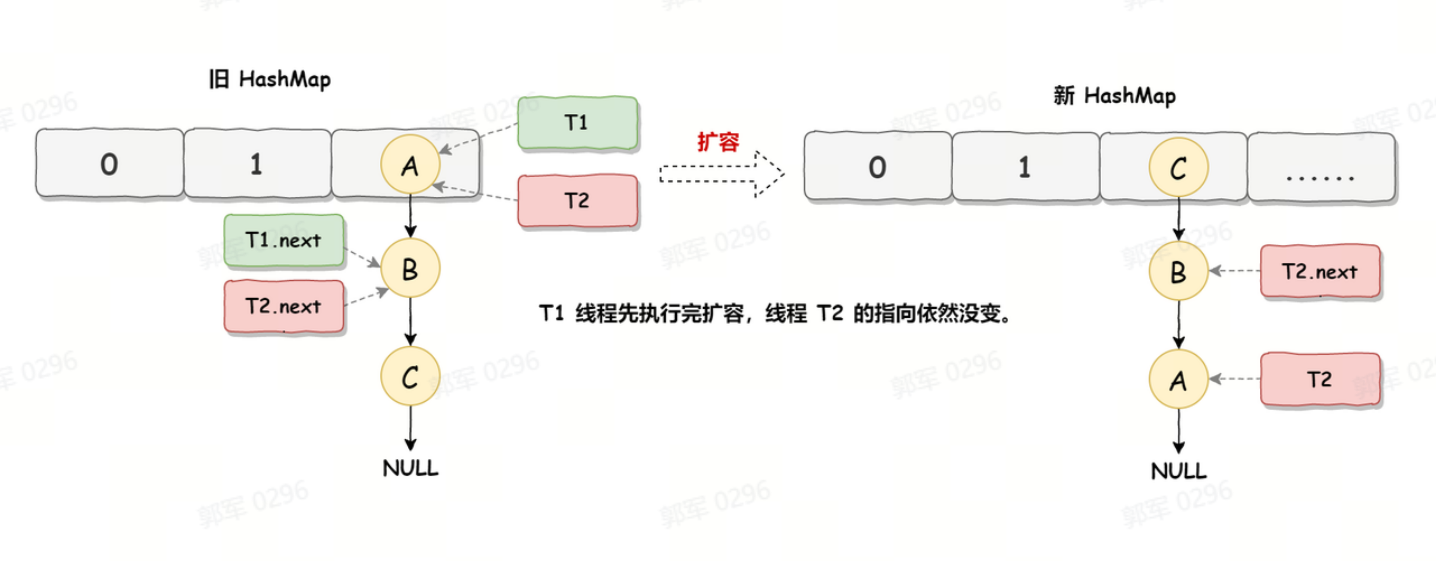 从上图可知线程 T1 执行之后,因为是头插法,所以 HashMap 的顺序已经发生了改变,但线程 T2 对于发生的一切是不可知的,所以它的指向元素依然没变,如上图展示的那样,T2 指向的是 A 元素,T2.next 指向的节点是 B 元素。
从上图可知线程 T1 执行之后,因为是头插法,所以 HashMap 的顺序已经发生了改变,但线程 T2 对于发生的一切是不可知的,所以它的指向元素依然没变,如上图展示的那样,T2 指向的是 A 元素,T2.next 指向的节点是 B 元素。死循环执行步骤3
当线程 T1 执行完,而线程 T2 恢复执行时,死循环就建立了,如下图所示:
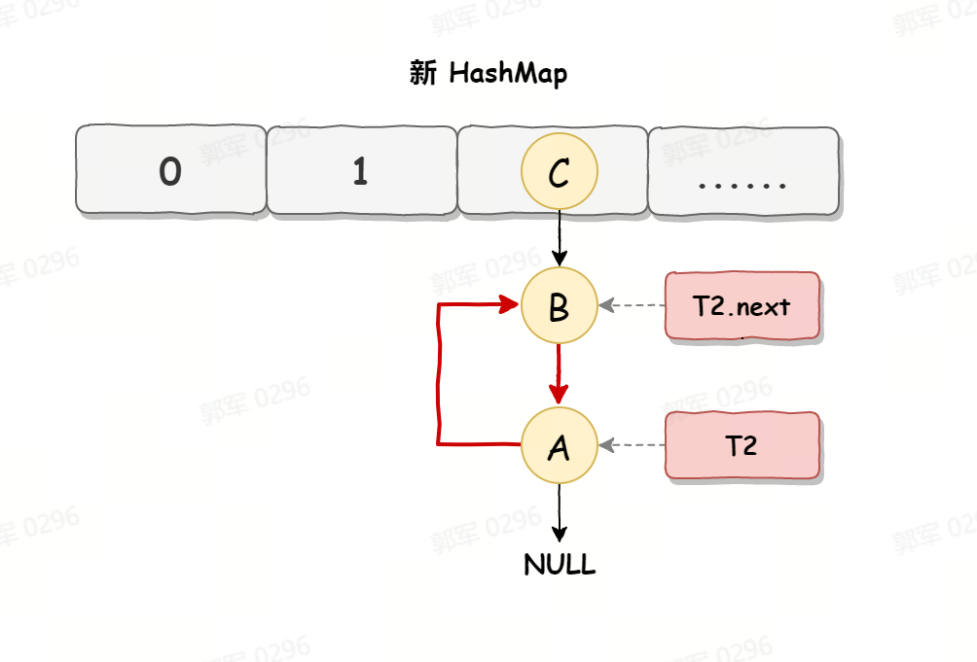
因为 T1 执行完扩容之后 B 节点的下一个节点是 A,而 T2 线程指向的首节点是 A,第二个节点是 B,这个顺序刚好和 T1 扩完容完之后的节点顺序是相反的。T1 执行完之后的顺序是 B 到 A,而 T2 的顺序是 A 到 B,这样 A 节点和 B 节点就形成死循环了,这就是 HashMap 死循环导致的原因。
# 什么是哈希冲突?如何解决哈希冲突?
哈希冲突(Hash Collision)是指不同的输入数据在进行哈希函数计算后,得到相同的哈希值的情况。由于哈希函数是将输入映射到一个有限的哈希表中,而输入的数据量可能是无限的,所以在特定的哈希函数和哈希表大小的限制下,哈希冲突是难以避免的。
解决哈希冲突的常见方法有以下几种:
- 链地址法(Separate Chaining):将哈希表中的每个桶都设置为一个链表,当发生哈希冲突时,将新的元素插入到链表的末尾。这种方法的优点是简单易懂,适用于元素数量较多的情况。缺点是当链表过长时,查询效率会降低。
- 再哈希法(Rehashing):当发生哈希冲突时,使用另一个哈希函数计算出一个新的哈希值,然后将元素插入到对应的桶中。这种方法的优点是简单易懂,适用于元素数量较少的情况。缺点是需要额外的哈希函数,且当哈希函数不够随机时,容易产生聚集现象。
- 开放地址法(Open Addressing):当发生哈希冲突时,就去寻找下一个空的哈希地址,只要哈希表足够大,空的哈希地址总能找到,之后再将数据进行存储。
在 Java 的 HashMap 中,是通过链地址法来解决哈希冲突的。
# 说下HashMap的查询流程?
- 首先,根据要查询元素的键(Key)通过哈希函数计算出哈希值(Hash Value),哈希函数实现源码如下:
 这行源码的主要含义是把哈希码按位异或哈希码右移 16 位的操作,让高位与低位混合,可以更好地分散元素在哈希表中的位置,减少哈希冲突的发生。
这行源码的主要含义是把哈希码按位异或哈希码右移 16 位的操作,让高位与低位混合,可以更好地分散元素在哈希表中的位置,减少哈希冲突的发生。 - 使用哈希值与哈希表的容量进行与操作(hash & (table.length-1)),得到元素在哈希表中的位置,即索引。
- 在该索引位置上,如果没有任何元素,则说明哈希表中不存在该键对应的元素,查询失败。
- 如果该索引位置上存在元素(可能是一个元素或者一个链表/红黑树),则进行以下操作:
- 如果仅有一个元素,则判断该元素的键是否与要查询的键相等。如果相等,则返回该元素的值;否则查询失败。
- 如果存在链表或红黑树,则遍历链表或红黑树,逐个比较键的值,找到与要查询的键相等的元素,并返回对应的值。
- 首先,根据要查询元素的键(Key)通过哈希函数计算出哈希值(Hash Value),哈希函数实现源码如下:
# HashMap和Hashtable有什么区别?
HashMap 和 Hashtable 都实现了 Map 接口,都是用来存储键值对的数据结构。
它们的区别主要有以下几点:
- 线程安全性:HashMap 是非线程安全的,而 Hashtable 是线程安全的。
- null 键和 null 值的支持:HashMap 允许键和值都为 null,即可以插入 null 键和 null 值;而 Hashtable 不允许键或值为 null,如果尝试插入 null 键或 null 值,会抛出NullPointerException。
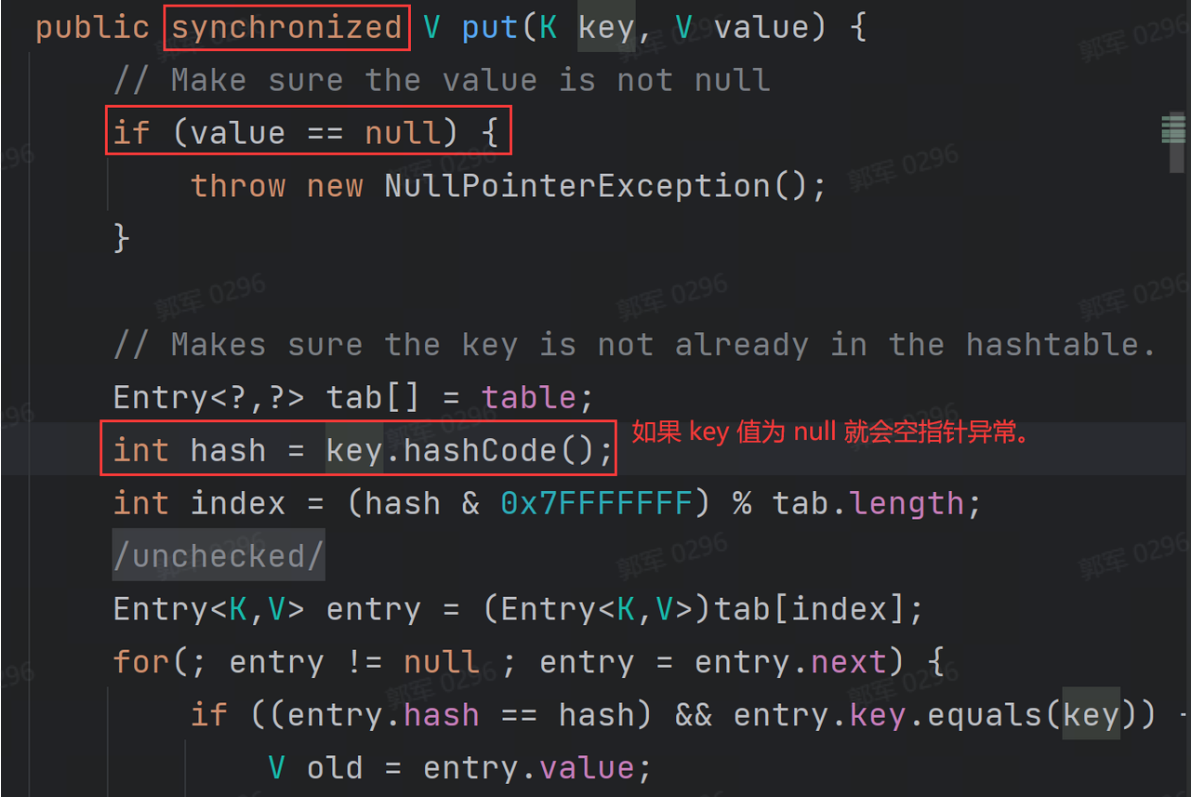
- 性能:由于 HashMap 不是线程安全的,在单线程环境下通常有更好的性能。Hashtable 是线程安全的,但会带来额外的同步开销,因此在单线程环境下性能可能较差。
# 为什么Hashtable不允许插入null?而HashMap却可以?
浅层次的来回答这个问题的答案是,JDK 源码不支持 Hashtable 插入 value 值为 null,如以下 JDK 源码所示:
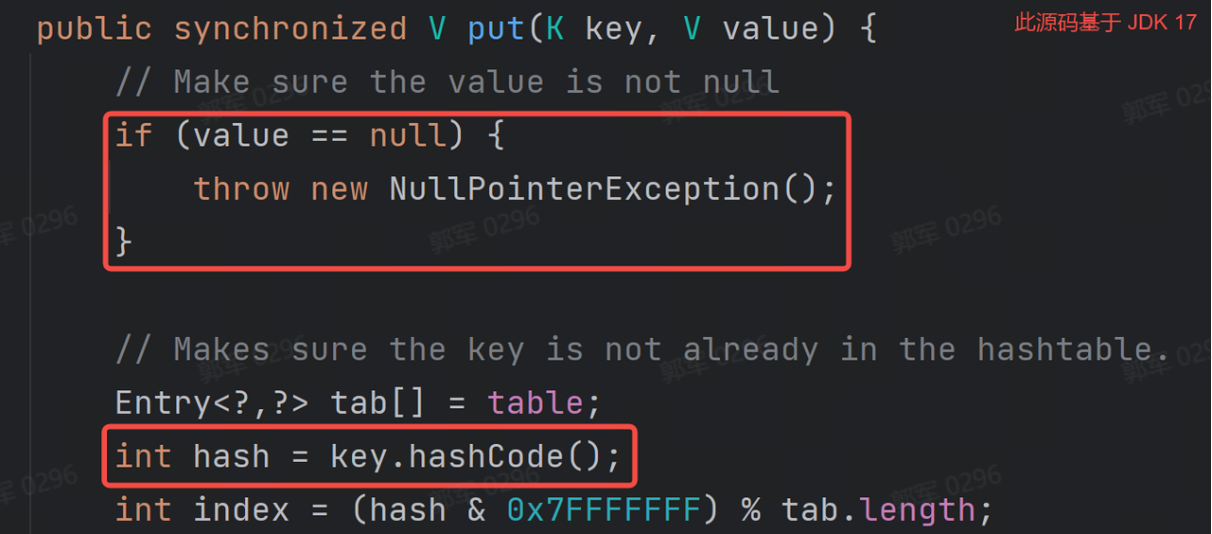 也就是 JDK 源码规定了,如果你给 Hashtable 插入 value 值为 null 就会抛出空指针异常。
并且看上面的 JDK 源码可以得出结论,如果 key 也为 null 的时候,因为 null 没有 hashCode 所以它也会报空指针异常,如下图所示:
也就是 JDK 源码规定了,如果你给 Hashtable 插入 value 值为 null 就会抛出空指针异常。
并且看上面的 JDK 源码可以得出结论,如果 key 也为 null 的时候,因为 null 没有 hashCode 所以它也会报空指针异常,如下图所示:
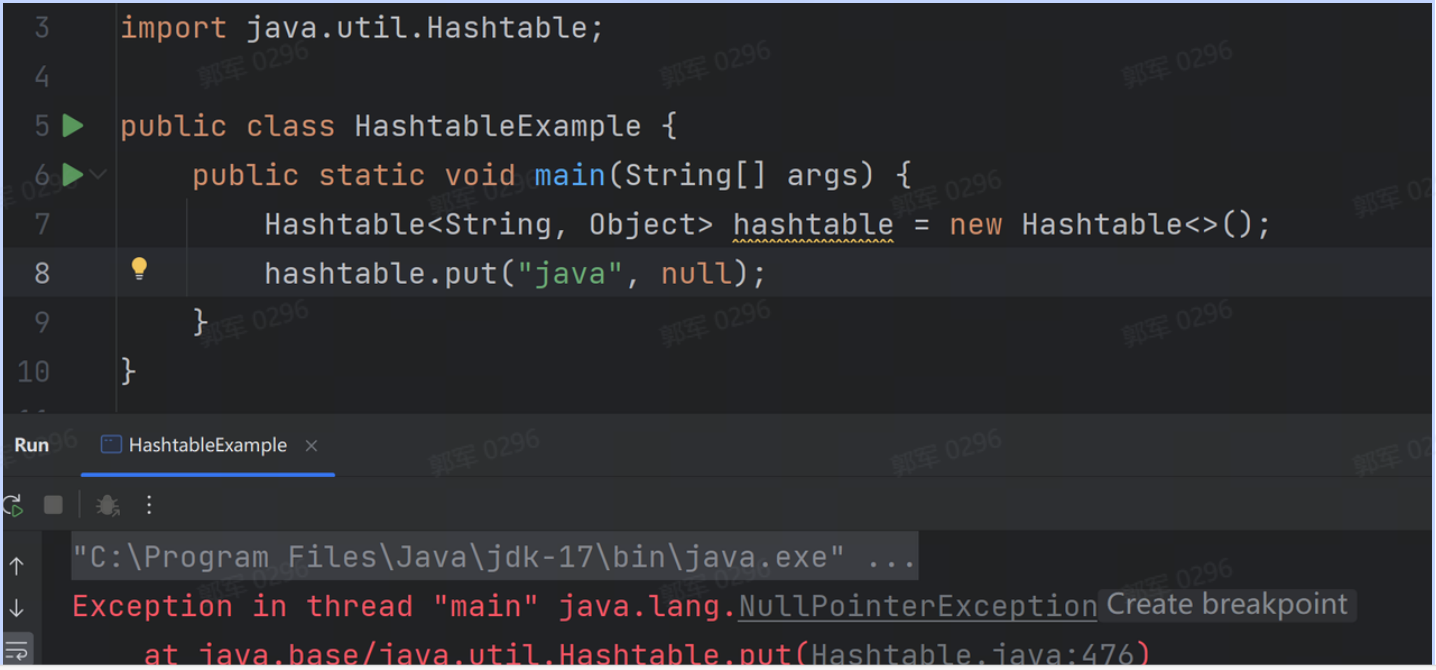
深层次的原因就是,设计的 Hashtable 是在多线程下使用的,而如果 Hashtable 的 key 或 value 允许为 null 的话,那么程序就会存在二义性问题。 如果我们假设 Hashtable 允许插入 null,那么此时它就会有二义性问题,这个 null 值就有两层含义: 这个 key 不存在,所以返回 null。 key 存在,并且值本身就为 null,所以返回的就是 null。 而在多线程下,你没有办法证明真伪,因为你在判断证明的时候,其他线程可能同时做了修改,所以不能被证明的二义性问题需要从源头上杜绝,所以多线程下的 Hashtable 是不允许 key 和 value 插入 null 值的。
ConcurrentHashMap 也是不允许插入 null,原因和 Hashtable 是一样的(因为有二义性问题)。
为什么 HashMap 允许插入 null 值?
因为 HashMap 设计是在单线程下使用的,而单线程可以证明真伪,它在进行查询判断的时候,不用担心有其他线程对这个值同时做修改,所以它不存在二义性问题,所以 HashMap 允许 key 和 value 都为 null。
# ConcurrentHashMap是怎么保证线程安全的?
ConcurrentHashMap 在不同 JDK 版本中,保证线程安全的手段是不同的,它主要分为以下两种情况: JDK 1.7 之前(包含 JDK 1.7),ConcurrentHashMap 主要是通过分段锁(Segment Lock)来保证线程安全的。
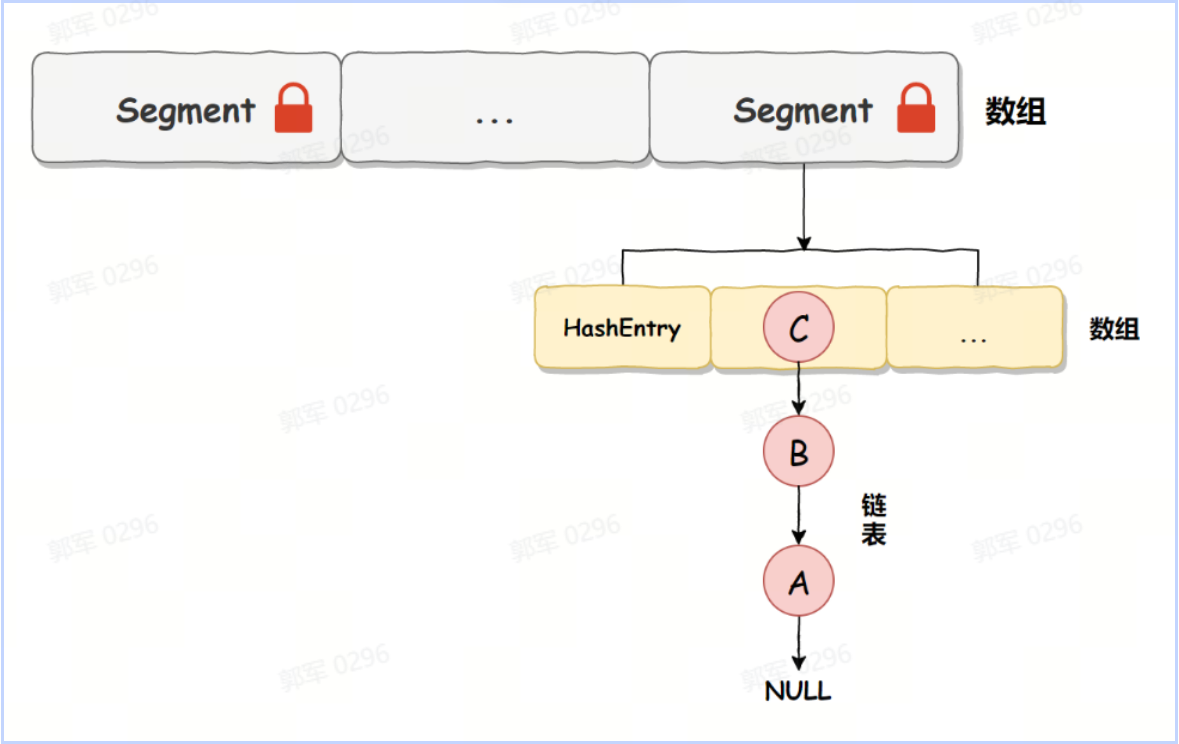
而在 JDK 1.8 之后(包含 JDK 1.8),使用了粒度更小锁,通过在数组的头节点加锁来保证线程安全的,并且加锁的手段也进行了优化,它使用的是 CAS + volatile 或 synchronized 来保证线程安全的。
# 说一下ConcurrentHashMap锁优化?
ConcurrentHashMap 锁优化主要有以下两点:
- 锁粒度优化:JDK 1.7 ConcurrentHashMap 使用的是分段锁(加锁多个数组),而 JDK 1.8 之后是加锁一个数组的头节点。锁粒度更小,意味着在多线程并发环境下执行效率越高。
- 锁实现优化:JDK 1.7 使用的是 ReentrantLock 实现加锁的,而 JDK 1.8 使用的是 CAS 或 synchronized 来实现加锁的,CAS 是乐观锁的实现,相比于 ReentrantLock 和 synchronized 的悲观锁,性能得到了一定的优化。
# 三.并发模块
# 线程中 start() 方法和 run() 方法有什么区别?
start() 方法是用来启动一个新线程的,而 run() 方法是一个普通方法,并不会重启线程,run() 方法中存放的是当前线程要执行的任务代码。 它们的区别主要有以下几点:
- 方法性质不同:run() 是一个普通方法,而 start() 是开启新线程的方法。
- 执行流程不同:调用 run() 方法会立即执行任务,而调用 start() 方法是将当前线程的状态,从新建状态改为就绪状态。此时它会等待操作系统调度器为其分配 CPU 时间片,一旦获得时间片,线程开始执行其 run() 方法中的代码了。
- 多次调用次数不同:run() 方法可以被重复多次调用,而 start() 方法只能被调用一次,如果被多次调用会抛出 IllegalThreadStateException 异常。
- 并发执行不同:调用 start() 方法会重启新线程,并发运行;而调用 run() 方法是在当前的主线程中执行,它依然是单线程执行的。
为什么 start() 方法不能被重复调用?
这个问题的浅层次原因是 JVM 不允许,当多次调用 start() 方法的时候程序会提示 IllegalThreadStateException 的异常,但为什么 JVM 会提示这个异常?
更深层次的原因是,线程生命周期管理的需要,因为在调用 start() 方法时,此线程的状态会从新建状态(NEW)变为就绪状态(RUNNABLE),JVM 会会为此线程分配必要的系统资源,如内存、程序计数器、线程栈等,此时如果允许多次调用 start() 方法的话,将会导致线程生命周期的混乱,也会让线程进入无
# 线程是如何通讯的?它的通讯方法有哪些?(说出你知道的所有通讯方法)
线程通信是指多个线程之间通过某种机制进行协调和交互,例如,线程等待和通知机制就是线程通讯的主要手段之一。 在 Java 中,线程通讯的实现方法主要有以下几种:
- Object 类下的 wait()、notify() 和 notifyAll() 方法。
- Condition 类下的 await()、signal() 和 signalAll() 方法。
- LockSupport 类下的 park() 和 unpark() 方法。
为什么一个线程通信机制需要这么多的实现方式呢?
我们先看每种通讯方式的使用,再讲原因。
① Object 类下的 wait()、notify() 和 notifyAll() 方法
- wait():让当前线程处于等待状态,并释放当前拥有的锁;
- notify():随机唤醒等待该锁的其他线程,重新获取锁,并执行后续的流程,只能唤醒一个线程;
- notifyAll():唤醒所有等待该锁的线程(锁只有一把,虽然所有线程被唤醒,但所有线程需要排队执行)。
② Condition 类下的 await()、signal() 和 signalAll() 方法
- await():对应 Object 的 wait() 方法,线程等待;
- signal():对应 Object 的 notify() 方法,随机唤醒一个线程;
- signalAll():对应 Object 的 notifyAll() 方法,唤醒所有线程。
③ LockSupport 下的 park() 和 unpark() 方法
- LockSupport.park():休眠当前线程。
- LockSupport.unpark(线程对象):唤醒某一个指定的线程。
PS:LockSupport 无需配锁(synchronized 或 Lock)一起使用。
为什么一个线程等待和唤醒的功能需要这么多的实现呢?
LockSupport 存在的必要性:前两种方法 notify 方法以及 signal 方法都是随机唤醒,如果存在多个等待线程的话,可能会唤醒不应该唤醒的线程,因此有 LockSupport 类下的 park 和 unpark 方法指定唤醒线程是非常有必要的。
Condition 存在的必要性:Condition 相比于 Object 类的 wait 和 notify/notifyAll
方法,前者可以创建多个等待集,例如,我们可以创建一个生产者等待唤醒对象,和一个消费者等待唤醒对象,这样我们就能实现生产者只能唤醒消费者,而消费者只能唤醒生产者的业务逻辑了,如下代码所示:
也就是 Condition 是 Object 等待唤醒模型的升级,Object 类可以实现的功能它都能实现,但 Condition 能实现的功能,Object 却不能实现,这就是 Condition 类存在的必要性。 那问题来了,为什么还有会 Object 的 wait 和 notify 方法呢? 因为 Object 类诞生的比较早,也就是说 Condition 和 LockSupport 都是 JDK 后期版本才出现的功能,所以就有了现在这么多线程唤醒和等待的方法了。
# 说一下线程的生命周期?
Java 线程的生命周期有以下 6 种:
- NEW(初始化状态)
- RUNNABLE(可运行/运行状态)
- BLOCKED(阻塞状态)
- WAITING(无时限等待状态)
- TIMED_WAITING(有时限等待状态)
- TERMINATED(终止状态)
PS:Java 线程状态可能和操作系统的状态叫法和分类是不同。
线程状态的转换如下图所示:
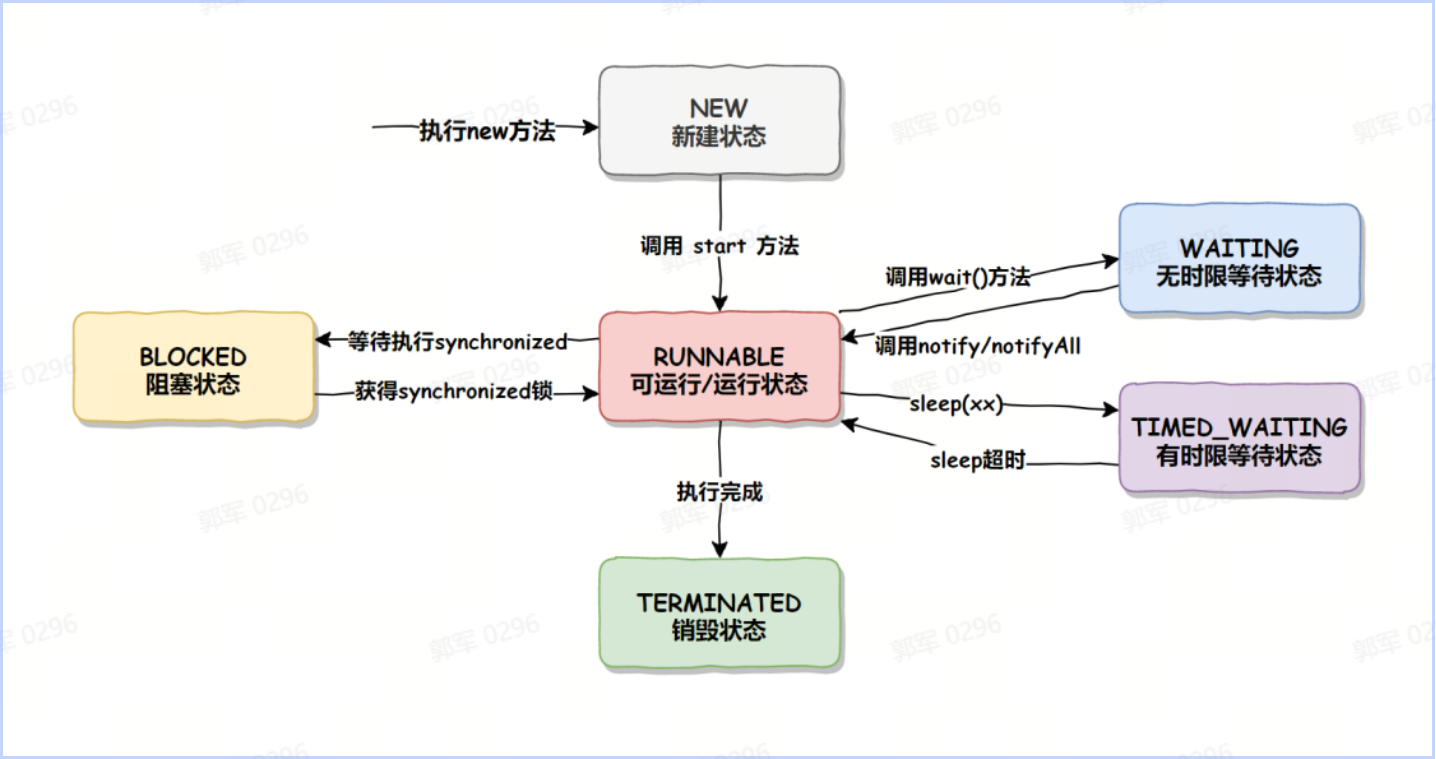
- NEW(新建状态):new Thread() 时线程的状态。
- RUNNABLE(可运行/运行状态):调用 start() 方法后的状态。
- BLOCKED(阻塞状态):调用了 synchronized 加锁之后的状态。获得锁之后就从 BLOCKED 状态变成了 RUNNABLE 状态。
- WAITING(无时限等待状态):调用了 wait() 方法之后会进入此状态。
- TIMED_WAITING(有时限等待状态):调用了 sleep(long millis) 方法之后会进入此状态。
- TERMINATED(终止状态):线程任务执行完成之后就变成此状态。
# 如何停止线程?
在 Java 中,停止线程是一个相对复杂的问题,因为线程的终止需要考虑多线程的同步和资源的正确释放。 而在 Java 中,停止线程的手段主要有以下三种:
- 使用自定义标识停止线程。
- 使用 interrupt() 方法停止线程。
- 使用 stop() 方法停止线程。
# wait() 方法和 sleep() 方法有什么区别?
wait() 方法和 sleep() 方法都是用于暂停线程执行的,但它们有以下几个主要区别:
所属类不同:
- wait() 方法是 java.lang.Object 类的一个方法,所有对象都可以调用。
- sleep() 方法是 java.lang.Thread 类的一个静态方法,直接作用于线程。
锁操作不同:
- wait() 方法必须在 synchronized 代码块或方法中调用,因为它会释放当前线程持有的对象监视器(锁),使得其他等待该锁的线程有机会继续执行。
- sleep() 方法不需要获取任何锁,它只是使当前线程休眠指定的时间,不会释放任何锁。
唤醒方式不同:
- wait() 方法的执行通常与 notify() 或 notifyAll() 方法配合使用。当一个线程调用 wait() 方法后,它将进入等待状态,直到被其他线程通过调用 notify() 或 notifyAll() 方法唤醒。
- sleep() 方法在指定的休眠时间结束后会自动唤醒线程,无需其他线程的干预。
使用场景不同:
- wait() 方法主要用于线程间的协作和通信,例如在生产者-消费者模式、条件队列等场景中。
- sleep() 方法通常用于简单的延时操作或者防止线程过于频繁地执行某些操作的场景。
总体来说,wait() 方法主要用于线程间的同步和协作,而 sleep() 方法主要用于控制线程的执行延迟。
# 线程池相比于线程有什么优点?
线程池是一种管理和复用线程的机制,它预先创建了一组线程,并维护一个任务队列,当任务来的时候,会从线程池中选择线程去执行任务,而不是直接创建线程去执行。
线程池的主要目的是提高多线程应用程序的性能,通过避免线程频繁创建和销毁带来的性能开销,提高了资源利用率、响应速度和系统的稳定性。
线程池是一种管理和复用线程的机制,它相比于线程来说主要具备以下优点:
- 线程重用(降低资源消耗):线程池可以重复利用已经创建的线程,避免了频繁创建和销毁线程的开销。通过线程池,可以有效地管理和控制线程的数量,避免线程过多导致资源消耗过大。
- 提高响应速度:线程池中的线程是预先创建好的,当有任务到达时,可以立即分配线程来处理任务,提高了任务的响应速度。相比于每次都创建新线程的方式,线程池可以减少线程创建的时间开销。
- 提供更强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。例如线程池中的任务队列,使用任务队列可以存储更多的待执行任务,还有延时定时线程池 ScheduledThreadPoolExecutor 允许任务延期执行或定期以某种频率执行。
- 提高系统稳定性:线程池可以限制并发线程的数量,避免系统因为线程过多而导致资源耗尽或系统崩溃。通过合理配置线程池的参数,可以控制系统的负载,提高系统的稳定性。
# 说下线程池创建参数都有哪些?它们都有哪些含义?
线程池 ThreadPoolExecutor 最多支持 7 个参数的设置,如下代码所示:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { if (corePoolSize < 0 || // maximumPoolSize 必须大于 0,且必须大于 corePoolSize maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0) throw new IllegalArgumentException(); if (workQueue == null || threadFactory == null || handler == null) throw new NullPointerException(); this.acc = System.getSecurityManager() == null ? null : AccessController.getContext(); this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.workQueue = workQueue; this.keepAliveTime = unit.toNanos(keepAliveTime); this.threadFactory = threadFactory; this.handler = handler; }这 7 个参数的含义如下:
- corePoolSize:核心线程数,表示线程池的常驻核心线程数。如果设置为 0,则表示在没有任何任务时,销毁线程池;如果大于 0,即使没有任务时也会保证线程池的线程数量等于此值。但需要注意,此值如果设置的比较小,则会频繁的创建和销毁线程(创建和销毁的原因会在本课时的下半部分讲到);如果设置的比较大,则会浪费系统资源,所以开发者需要根据自己的实际业务来调整此值。
- maximumPoolSize:最大线程数,表示线程池在任务最多时,最大可以创建的线程数。官方规定此值必须大于 0,也必须大于等于 corePoolSize,此值只有在任务比较多,且不能存放在任务队列时,才会用到。
- keepAliveTime:表示临时线程的存活时间(最大线程数-核心线程数)。当线程池空闲时并且超过了此时间,多余的线程就会销毁,直到线程池中的线程数量销毁的等于 corePoolSize 为止,如果 maximumPoolSize 等于 corePoolSize,那么线程池在空闲的时候也不会销毁任何线程。
- unit:表示临时线程的存活时间单位。它是配合 keepAliveTime 参数三共同使用的。
- workQueue:表示线程池执行的任务队列,当线程池的所有线程都在处理任务时,如果来了新任务就会缓存到此任务队列中排队等待执行。
- threadFactory:表示线程的创建工厂,此参数一般用的比较少,我们通常在创建线程池时不指定此参数,它会使用默认的线程创建工厂的方法来创建线程。
- RejectedExecutionHandler:表示指定线程池的拒绝策略,当线程池的任务已经在缓存队列 workQueue 中存储满了之后,并且不能创建新的线程来执行此任务时,就会用到此拒绝策略,它属于一种限流保护的机制。
# 线程工厂有什么用?不设置线程工厂会怎样?
线程池中的线程工厂可以设置线程池的名称格式、线程的优先级、线程分组、以及线程类型(用户线程或守护线程)等信息,如下代码所示:不设置线程工厂会怎样? 当线程池中不设置线程工厂时,会使用默认的线程工厂,具体源码如下:public static void main(String[] args) { // 创建一个线程组 ThreadGroup threadGroup = new ThreadGroup("MyThreadGroup"); // 创建线程工厂 ThreadFactory threadFactory = new ThreadFactory() { @Override public Thread newThread(Runnable r) { // 创建线程池中的线程(设置线程组和任务) Thread thread = new Thread(threadGroup, r); // 设置线程名称 thread.setName("Thread-" + r.hashCode()); // 设置线程优先级(最大值:10) thread.setPriority(Thread.MAX_PRIORITY); //... return thread; } }; // 创建线程池 ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(10, 10, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<>(), threadFactory); // 使用自定义的线程工厂 threadPoolExecutor.submit(new Runnable() { @Override public void run() { Thread thread = Thread.currentThread(); System.out.println(String.format("线程:%s,线程优先级:%d", thread.getName(), thread.getPriority())); } }); }
# 线程的优先级有什么用?如何设置线程池的优先级?
线程的优先级用整数表示,范围从 1 到 10,数字越大表示优先级也越高,线程的默认优先级为 5。
需要注意的是,线程的优先级越高,表示它在竞争 CPU 资源时更有可能被调度执行。然而,线程优先级的具体行为在不同的操作系统和 Java 虚拟机实现中可能会有所不同。所以,线程优先级仅仅是给操作系统一个提示,告诉它应该优先调度哪个线程,但操作系统可能不会严格按照优先级来调度线程。
Java 中,线程的优先级由 Thread 类的 setPriority() 和 getPriority() 方法来设置和获取线程的优先级。
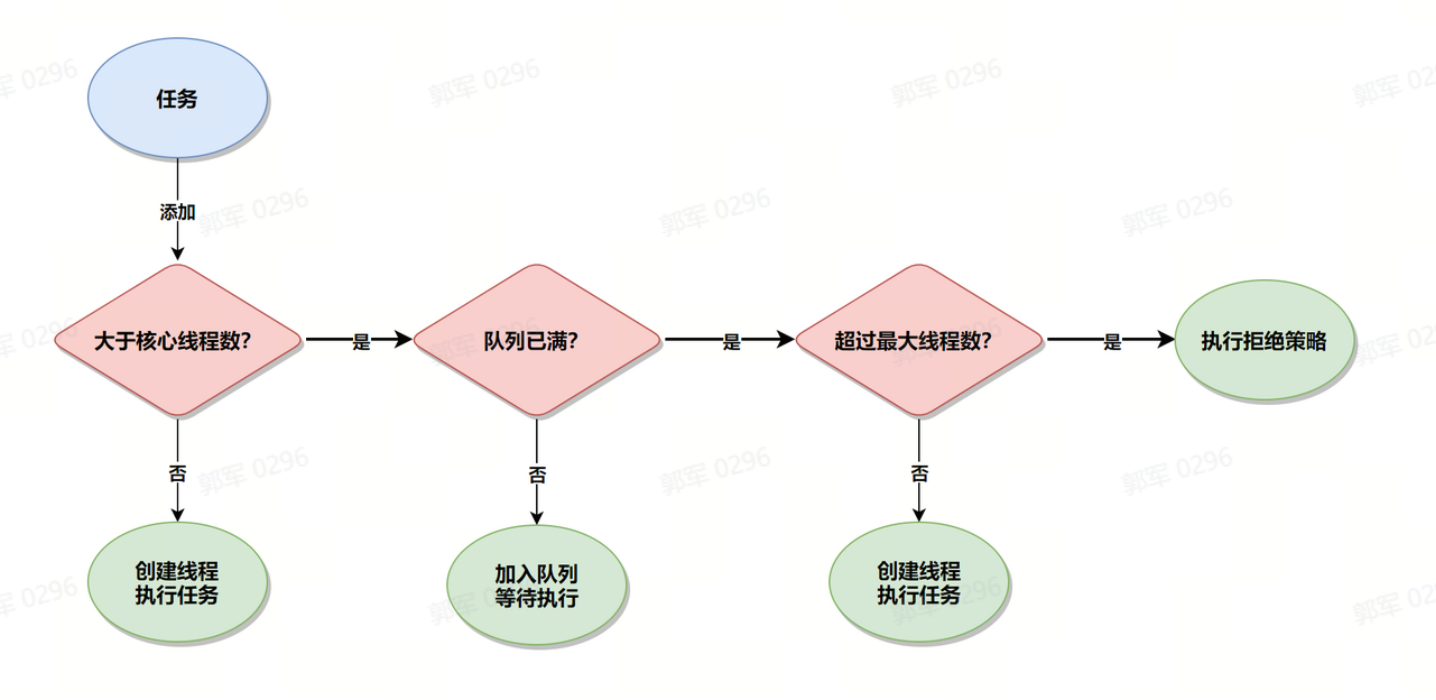
# 说一下线程池的执行流程?
当有任务来了之后,线程池的执行流程是这样的:
- 先判断当前线程数是否大于核心线程数,如果结果为 false,则新建线程并执行任务。
- 如果大于核心线程数,则判断任务队列是否已满?如果结果为 false,则把任务添加到任务队列中等待线程执行。
- 如果任务队列已满,则判断当前线程数量是否超过最大线程数?如果结果为 false,则新建线程执行此任务。
- 如果超过最大线程数,则将执行线程池的拒绝策略。
# 说一下线程池的拒绝策略有哪些?实际工作中会使用哪种拒绝策略?为什么?
JDK 自带了四种拒绝策略加上一种自定义拒绝策略,所以总共有五种拒绝策略,这些拒绝策略分别是:
- AbortPolicy(默认):抛出一个 RejectedExecutionException 异常,阻止任务的提交。
- CallerRunsPolicy:使用调用线程来执行该任务。意味着将任务返回给任务提交者进行执行,而不是在线程池中处理。
- DiscardPolicy:默默地丢弃无法接受的任务,不提供任何错误日志或其他通知。
- DiscardOldestPolicy:丢弃队列中最旧的任务,然后尝试重新提交被拒绝的任务。通过这种方式,可以让新提交的任务有机会得到执行。
- 自定义拒绝策略通过 new RejectedExecutionHandler 实现,并重写 rejectedExecution 方法来实现
实际开发中会使用哪种拒绝策略?为什么?
实际开发中会使用自定义拒绝策略,因为自定义拒绝策略灵活好控制,可以在自定义拒绝策略中发送一条通知给消息中心,让消息中心发送告警信息给开发者,这样就能实时监控线程池的运行状况,并能及时发现和排查问题了。
# 如何判断线程池中的任务是否执行完成?
判断线程池中的任务是否执行完成的方法主要有以下两个:
- 使用 getCompletedTaskCount() 统计已经执行完的任务,和 getTaskCount() 线程池的总任务进行对比,如果相等则说明线程池的任务执行完了,否则既未执行完。
- 使用 FutureTask 等待所有任务执行完,线程池的任务就执行完了。
# 导致线程安全问题的因素有哪些?
线程安全问题指的是在多线程环境下,多个线程同时操作共享资源时,导致程序执行结果与预期不符的问题。
线程安全问题可能导致数据的不一致、程序崩溃、死锁等问题。
导致线程安全问题的因素主要有以下几点:
- 多线程同时执行:多个线程同时执行是造车并发问题的根本原因。
- 操作共享数据:当多个线程访问和修改同一块共享数据时,可能会导致数据覆盖,数据可见性等问题。
- 非原子操作:某些操作虽然看起来是单个语句,但在计算机内部可能被分解为多个步骤。如果这些操作在多线程环境中没有得到适当同步,就可能导致线程安全问题。
- 指令重排序:编译器和处理器为了优化性能,可能会对代码进行重新排序。这种重排序在单线程环境下通常是安全的,但在多线程环境下可能会导致意料之外的结果。
- 内存可见性问题:在多线程环境中,一个线程对共享变量的修改可能不会立即对其他线程可见。这是因为每个线程都有自己的本地缓存,而且编译器和处理器可能会进行各种优化。
# 解决线程安全问题的手段有哪些?
解决线程安全问题主要是通过加锁(让多线程执行变成多线程排队执行,每个时刻只有一个线程在执行)或每个线程操作自己的私有变量,这样也不会存在线程安全问题,因为大家各改各的,互不影响。
总结来说,在 Java 中解决线程安全问题的主要手段有以下 3 种:
- 通过锁机制处理:多线程排队执行,每个时刻只有一个线程在执行,如 Lock 或 synchronized。
- 使用线程安全的容器:如 ConcurrentHashMap、CopyOnWriteArrayList 等。
- 使用 ThreadLocal:线程局部变量,每个线程操作自己的变量,也不会导致线程安全问题。
PS:使用线程安全的容器底层还是通过锁机制来保证线程安全的。
# synchronized 底层是如何实现的?
synchronized 是通过 JVM 内置的 Monitor 监视器实现的,而监视器又是依赖操作系统的互斥锁 Mutex 实现的。
当我们给程序加了 synchronized 之后,那么在编译成字节码时,就会给相应的代码块添加 monitor.
# 说一下 synchronized 锁升级的流程?
synchronized 锁升级的流程如下:
- 无锁
- 偏向锁
- 轻量级锁
- 重量级锁
synchronized 会按照上述先后顺序依次升级,我们把这个升级的过程称之为“锁膨胀”。
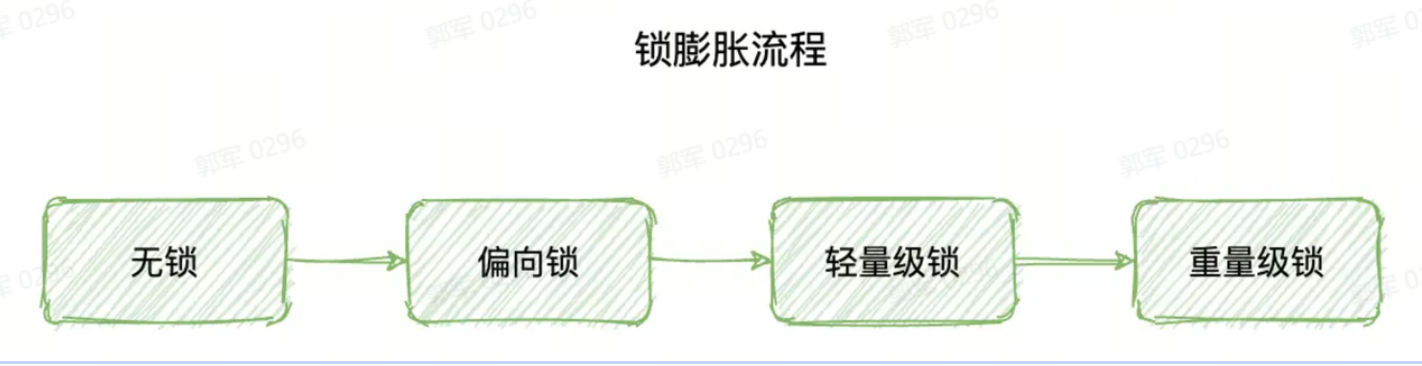
synchronized 锁升级的流程如下:
- 刚开始程序先是无锁状态,没有线程使用。
- 当一个线程访问同步代码块并获取锁时,会在对象头的 Mark Word 里存储锁偏向的线程 ID,此时就是偏向锁。
- 如果 Mark Word 中的线程 ID 和访问的线程 ID 一致,则可以直接进入同步块进行代码执行,如果线程 ID 不同,则使用 CAS 尝试获取锁,如果获取成功则进入同步块执行代码,否则会将锁的状态升级为轻量级锁。
- 轻量级锁之后会通过自旋来获取锁,自旋执行一定次数之后还未成功获取到锁,此时就会升级为重量级锁,并且进入阻塞状态。
# synchronized 是固定自旋次数吗?
synchronized 是自适应自旋锁,不是固定自旋次数。
自适应自旋锁是指,线程自旋的次数不再是固定的值,而是一个动态改变的值。这个值会根据前一次自旋获取锁的状态来决定此次自旋的次数。
例如,上一次通过自旋成功获取到了锁,那么这次通过自旋也有可能会获取到锁,所以这次自旋的次数就会增多一些,而如果上一次通过自旋没有成功获取到锁,那么这次自旋可能也获取不到锁,所以为了避免资源的浪费,就会少循环或者不循环,以提高程序的执行效率。简单来说,如果线程自旋成功了,则下次自旋的次数会增多,如果失败,下次自旋的次数会减少。
# synchronized 和 ReentrantLock 有什么区别?
synchronized 和 ReentrantLock 都提供了锁的功能,都是 Java 中保证线程安全的主要手段,但它们有很大的区别。
- synchronized 属于独占式悲观锁,是通过 JVM 隐式实现的,synchronized 只允许同一时刻只有一个线程操作资源。
- ReentrantLock 是 Lock 的默认实现方式之一,它是基于 AQS(Abstract Queued Synchronizer,队列同步器)实现的,它默认是通过非公平锁实现的,在它的内部有一个 state 的状态字段用于表示锁是否被占用,如果是 0 则表示锁未被占用,此时线程就可以把 state 改为 1,并成功获得锁,而其他未获得锁的线程只能去排队等待获取锁资源。
在 JDK 1.5 中 synchronized 的性能远远低于 ReentrantLock,但在 JDK 1.6 之后 synchronized 的性能和 ReentrantLock 的性能差别不大。
主要区别详情
- ReentrantLock 只能修饰代码块,而 synchronized 可以用于修饰方法、修饰代码块等。
- ReentrantLock 需要手动加锁和释放锁,如果忘记释放锁,则会造成资源被永久占用,而 synchronized 无需手动释放锁。
- ReentrantLock 使用时更加灵活,比如 ReentrantLock 可以知道是否成功获得了锁,而 synchronized 却不行。
- ReentrantLock 可设置为公平锁,而 synchronized 却不行。
- 二者的底层实现不同,synchronized 是 JVM 层面通过监视器(Monitor)实现的,而 ReentrantLock 是通过 AQS(AbstractQueuedSynchronizer)程序级别的 API 实现。
# volatile 能保证线程安全吗?为什么?
volatile 不能保证线程执行安全,volatile 主要作用有两个:保证内存的可见性和禁止指令重排序。
也就说使用 volatile 可以保证多个线程在操作同一个变量时,始终可以读取到最新的数据;并且使用 volatile 可以禁止指令重排序,从而关闭掉系统优化所给程序代码执行结果不一致的风险。
但是 volatile 不能保证原子性,而原子性也是导致线程不安全的因素之一,所以 volatile 不能保证线程安全。
# volatile 在实际工作中,有那些使用场景?
volatile 在实际工作中,常用的场景有以下几个:
- 单例模式(双重检查锁定,Double-checked locking):在单例模式等场景下,volatile 可以配合使用双重检查锁定来确保只有一个实例被创建。在获取实例时,通过对实例对象进行 volatile 检查,确保其他线程能够正确读取已创建的实例,如下代码所示:
public class Singleton { private Singleton() {} private static volatile Singleton instance = null; public static Singleton getInstance() { if (instance == null) { // ① synchronized (Singleton.class) { if (instance == null) { instance = new Singleton(); // ② } } } return instance; } }- 定时任务控制标志:在一些定时任务中,可能需要用到标志位来控制任务的启停。通过将标志位声明为 volatile,确保在修改标志位时能够立即对其他线程可见,并及时停止或启动相关任务。例如以下代码:如下代码所示:
public class MyThread extends Thread { private volatile boolean flag = true; public void stopThread() { flag = false; } @Override public void run() { while (flag) { // 线程执行的代码 } } }如果不加的话,那么编译器可能将上面的代码优化为以下代码:
public class MyThread extends Thread { private boolean flag = true; public void stopThread() { flag = false; } @Override public void run() { while (false) { // 线程执行的代码 } } }那么,定时任务就失控了,永远停不下来了。
- 线程间消息通知:当一个线程需要向另一个线程发送通知时,可以使用 volatile 作为信号量。当一个线程修改了 volatile 变量的值时,其他线程能够立即看到该变化,从而得知有新的消息到达。
# 什么是乐观锁?乐观锁底层是如何实现的?
乐观锁认为并发访问不会导致冲突,因此在读取数据时不立即加锁,而是在更新数据时检查自上次读取以来数据是否已经被其他人修改过。
乐观锁底层是通过 CAS(Compare And Swap,比较并替换)机制实现的,CAS 机制包含三个组件:内存地址 V、预期值 A 和新值 B。
CAS 的操作过程如下:
- 比较内存地址 V 中的值与预期值 A 是否相等。
- 如果相等,将内存地址 V 的值修改为新值 B。
- 如果不相等,表示预期值 A 与实际值不匹配,操作失败。
CAS 的操作是原子性的,即整个操作过程是不可中断的,要么成功执行并修改值,要么不执行修改。如果由于竞争或并发导致操作失败(预期值不匹配),则可以通过循环重新尝试操作,直到成功或达到最大尝试次数操作失败。
# 什么是ABA问题?如何解决ABA问题?
ABA 问题是在使用 CAS 时可能出现的一种并发问题。在多线程环境下,如果一个变量的值先被线程 A 修改为 B,然后又被线程 B 修改回 A,那么在使用 CAS 进行比较和交换操作时,尽管变量的当前值与预期值相同(都是 A),但实际上这个变量的值已经被修改过,这就是 ABA 问题。
解决 ABA 问题的常见方案是加版本号,通过版本号 + 旧值共同来决定变量是否有变动。
# ReentrantLock底层是如何实现的?
ReentrantLock(可重入锁)是 Java 并发包 java.util.concurrent.locks 中提供的一个互斥同步器,其底层实现基于 AbstractQueuedSynchronizer(AQS)框架。AQS 是一个实现了阻塞式锁和相关同步器(信号量、事件等)的框架,提供了基于 FIFO 等待队列的线程调度机制。
ReentrantLock 底层实现和主要特性:
状态变量(state):ReentrantLock 内部维护了一个 volatile int 类 型的成员变量 state,用来表示锁的持有者数量以及当前锁的状态(是否被锁定)。当 state 为 0 时代表锁未被任何线程持有;大于 0 则表示被某个线程持有,并且 state 值也代表了重入次数。
公平与非公平锁:ReentrantLock 通过两个内部类 FairSync 和 NonfairSync 来分别实现公平锁和非公平锁。公平锁在获取锁时会遵循 FIFO 原则,而非公平锁则允许“插队”,即不管线程等待队列顺序,有机会就尝试获取锁。
获取锁过程:
- lock() 方法首先会尝试 CAS 操作(compareAndSetState())去获取锁,如果当前没有其他线程持有锁或者锁已经被当前线程持有,则增加 state 计数并成功获得锁。
- 当 CAS 操作失败时,表明有其他线程持有锁或锁正被竞争。此时,当前线程会被封装成一个节点(Node)加入到 AQS 的等待队列中。如果是公平锁,新节点会排在队尾;如果是非公平锁,则可能尝试直接获取锁或插入队列头部。
解锁过程:unlock() 方法会递减 state 计数,当 state 减少至 0 时,表明所有锁都被释放,此时如果有等待线程,则唤醒等待队列中的第一个节点的线程继续尝试获取锁。
可重入性:可重入体现在同一个线程可以对已经持有的锁再次调用 lock() 方法而不被阻塞,此时只是简单地增加 state 计数,而不是将自己放入等待队列。
超时获取锁:ReentrantLock 还提供了带超时限制的 tryLock(long timeout, TimeUnit unit) 方法,它会在指定时间内尝试获取锁,若无法获取则返回 false,避免线程无休止地等待。
ReentrantLock 通过 AQS 提供的底层支持,结合 CAS 原子操作、自旋、线程挂起和恢复等技术手段,高效地实现了可重入、公平/非公平、可中断等复杂功能的锁机制。
# 手写一个死锁代码?产生死锁的因素有哪些?
以下是实现死锁的代码:
public class DeadlockDemo { private static Object lock1 = new Object(); private static Object lock2 = new Object(); public static void main(String[] args) { Thread thread1 = new Thread(() -> { synchronized (lock1) { System.out.println("Thread 1 acquired lock1"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } synchronized (lock2) { System.out.println("Thread 1 acquired lock2"); } } }); Thread thread2 = new Thread(() -> { synchronized (lock2) { System.out.println("Thread 2 acquired lock2"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } synchronized (lock1) { System.out.println("Thread 2 acquired lock1"); } } }); thread1.start(); thread2.start(); } }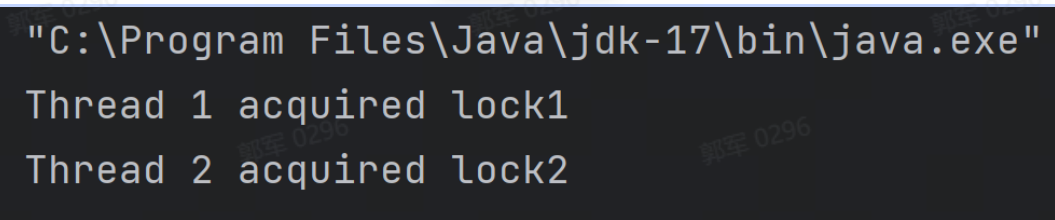
产生死锁的条件有以下 4 个:
- 互斥条件:指运算单元(进程、线程或协程)对所分配到的资源具有排它性,也就是说在一段时间内某个锁资源只能被一个运算单元所占用。
- 请求和保持条件:指运算单元已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它运算单元占有,此时请求运算单元阻塞,但又对自己已获得的其它资源保持不放。
- 不可剥夺条件:指运算单元已获得的资源,在未使用完之前,不能被剥夺。
- 环路等待条件:指在发生死锁时,必然存在运算单元和资源的环形链,即运算单元正在等待另一个运算单元占用的资源,而对方又在等待自己占用的资源,从而造成环路等待的情况。
# 如何排查死锁? 如何解决死锁?
- jstack:可以查看 Java 应用程序的线程状态和调用堆栈,可用于发现死锁线程的状态。
- jconsole 和 JVisualVM:这些是 Java 自带的监视工具,可以用于监视线程、内存、CPU 使用率等信息,从而帮助排查死锁问题。
- Thread Dump Analyzer(TDA):是一个开源的线程转储分析器,可用于分析和诊断 Java 应用程序中的死锁问题。
- Eclipse TPTP:是一个开源的性能测试工具平台,其中包含了一个名为 Thread Profiler 的工具,可以用于跟踪线程运行时的信息,从而诊断死锁问题。
如何解决死锁?
我们可以通过顺序锁或轮询锁来解决死锁的问题。
- 顺序锁: 所谓的顺序锁指的是通过有顺序的获取锁,从而避免产生环路等待条件,从而解决死锁问题的。
- 轮询锁: 是通过打破“请求和保持条件”来避免造成死锁的,它的实现思路简单来说就是通过轮询来尝试获取锁,如果有一个锁获取失败,则释放当前线程拥有的所有锁,等待下一轮再尝试获取锁。
# Java 中乐观锁的实现类有哪些?悲观锁的实现类有哪些?
Java 乐观锁的实现有以下几个:
- java.util.concurrent.atomic 包下的原子类如 AtomicInteger、AtomicLong、AtomicReference 等。
- ReentrantLock 其底层是使用 AQS 中的乐观锁 CAS 实现的,但其本身(的业务属性)为悲观锁(底层实现依靠的是乐观锁 CAS)。
Java 悲观锁的实现有以下几个:
- synchronized:使用 synchronized 关键字可以将代码块或方法进行同步,保证在同一时间只有一个线程可以访问。它是内置的关键字,可以用于实现对对象的悲观锁。
- ReentrantLock:ReentrantLock 是 JDK 提供的一个可重入锁的实现,通过它可以实现对临界区的加锁和解锁操作。它提供了更多的灵活性和功能,例如可设置超时、可中断、公平性等特性。它的底层是通过乐观锁 CAS 实现的,但其本身为悲观锁。
- ReadWriteLock:ReadWriteLock 是 JDK 提供的读写锁的实现,通过它可以在读多写少的情况下提供更高的并发性。它允许多个线程同时读取数据,但只允许一个线程进行写入。
# Java 中除了乐观锁和悲观锁外还有哪些锁?
除了乐观锁和悲观锁之外,其他的常用锁策略还有以下几个:
- 公平锁:公平锁是指多个线程按照申请锁的顺序来获取锁。
- 非公平锁:非公平锁是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁。
- 独占锁:独占锁是指任何时候都只有一个线程能执行资源操作。
- 共享锁:共享锁指定是可以同时被多个线程读取,但只能被一个线程修改。比如 Java 中的 ReentrantReadWriteLock 就是共享锁的实现方式,它允许一个线程进行写操作,允许多个线程读操作。
- 可重入锁:可重入锁指的是该线程获取了该锁之后,可以无限次的进入该锁锁住的代码。
- 自旋锁:自旋锁是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗 CPU。
Java 中的所有锁默认都是非公平锁,因为非公平锁的效率高,但有很小的几率非公平锁会产生线程饥饿的问题,指的是某个线程竞争了很多次、等待了很长时间但依然没有获得锁资源。
我们可以使用 ReentrantLock 来创建公平锁,实现代码为“ReentrantLock lock = new ReentrantLock(true);”其中参数 true 表示创建公平锁,默认值为 false 非公平锁。
# AtomicInteger 是线程安全的吗?它属于哪种锁类型?它存在 ABA 问题吗?如何解决这些问题?
AtomicInteger 底层是通过 CAS 乐观锁实现的,所以它也属于乐观锁实现的线程安全的容器。
AtomicInteger 存在 ABA 的问题,想要解决此问题,可以使用它的兄弟类 AtomicStampedReference 类来实现,AtomicStampedReference 类通过设置版本号和累计版本号的方式解决了 ABA 问题,它的使用代码如下:
import java.util.concurrent.atomic.AtomicStampedReference; public class AtomicStampedReferenceExample { public static void main(String[] args) { // 创建一个初始值为100,初始版本号为0的AtomicStampedReference对象 AtomicStampedReference<Integer> atomicStampedRef = new AtomicStampedReference<>(100, 0); // 获取当前值和版本号 int currentValue = atomicStampedRef.getReference(); int currentStamp = atomicStampedRef.getStamp(); System.out.println("当前值:" + currentValue + ",当前版本号:" + currentStamp); // 尝试将值从100更新为200,版本号加1 int newStamp = currentStamp + 1; boolean success = atomicStampedRef.compareAndSet(currentValue, 200, currentStamp, newStamp); System.out.println("更新结果:" + success); // 获取更新后的值和版本号 int updatedValue = atomicStampedRef.getReference(); int updatedStamp = atomicStampedRef.getStamp(); System.out.println("更新后的值:" + updatedValue + ",更新后的版本号:" + updatedStamp); }# 什么是Semaphore?它有什么用?它的底层是如何实现的?
Semaphore(信号量)是一种同步工具,可以用来限制并发访问的数量,或者作为一种许可机制来管理资源的使用。
Semaphore 就好比停车场的门卫,可以控制车位的使用资源。比如来了 5 辆车,只有 2 个车位,门卫可以先放两辆车进去,等有车出来之后,再让后面的车进入,它的实现代码如下
import java.time.LocalTime; import java.util.concurrent.Semaphore; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.TimeUnit; import java.util.concurrent.LinkedBlockingQueue; public class SemaphoreDemo { public static void main(String[] args) { // 同时只允许两个线程访问 Semaphore semaphore = new Semaphore(2); ThreadPoolExecutor semaphoreThread = new ThreadPoolExecutor(10, 50, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<>()); for (int i = 0; i < 5; i++) { semaphoreThread.execute(() -> { try { // 堵塞获取许可 semaphore.acquire(); System.out.println("Thread:" + Thread.currentThread().getName() + " 时间:" + LocalTime.now()); TimeUnit.SECONDS.sleep(2); // 释放许可 semaphore.release(); } catch (InterruptedException e) { e.printStackTrace(); } }); } } }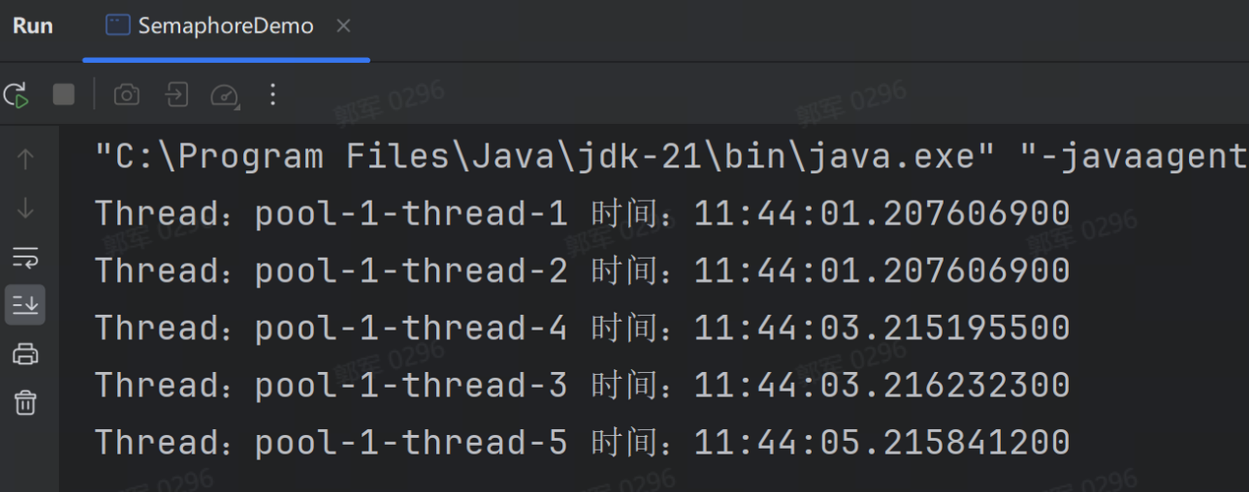
执行流程如下图:

Semaphore 底层实现主要依赖于 AQS(AbstractQueuedSynchronizer)框架,它使用一个同步队列来管理等待许可的线程。Semaphore 内部维护了一个计数器,记录着可用的许可数量。每次线程调用 acquire() 方法时,Semaphore 会将计数器减一,如果计数器小于等于 0,则线程会被加入到同步队列中阻塞等待。当线程调用 release() 方法释放许可时,Semaphore 会将计数器加一,并唤醒一个等待的线程。
# CountDownLatch 和 CyclicBarrier 有什么区别?
CountDownLatch 和 CyclicBarrier 都是 JUC(java.util.concurrent)下的包,但它们的使用场景略有不同。
CountDownLatch 侧重于单向等待执行(只能使用一次),用于一个或多个线程等待其他线程完成之后再进行后续操作,而 CyclicBarrier 则更适用于多线程之间的协作和同步,可以重复使用多次。
①. CountDownLatch
CountDownLatch(闭锁)可以看作一个只能做减法的计数器,可以让一个或多个线程等待执行。
CountDownLatch 有两个重要的方法:
countDown():使计数器减 1;
await():当计数器不为 0 时,则调用该方法的线程阻塞,当计数器为 0 时,可以唤醒等待的一个或者全部线程。
CountDownLatch 使用场景:
以生活中的情景为例,比如去医院体检,通常人们会提前去医院排队,但只有等到医生开始上班,才能正式开始体检,医生也要给所有人体检完才能下班,这种情况就要使用 CountDownLatch,流程为:患者排队 → 医生上班 → 体检完成 → 医生下班。
CountDownLatch 使用代码如下:
public static void main(String[] args) throws InterruptedException { // 创建 CountDownLatch CountDownLatch countDownLatch = new CountDownLatch(2); // 创建固定线程数的线程池 ExecutorService executorService = Executors.newFixedThreadPool(2); // 任务一 executorService.submit(new Runnable() { @Override public void run() { // do something try { // 让此任务执行 1.2s Thread.sleep(1200); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("我是任务一"); countDownLatch.countDown(); } }); // 任务二 executorService.submit(new Runnable() { @Override public void run() { // do something try { // 让此任务执行 1.2s Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("我是任务二"); countDownLatch.countDown(); } }); // 等待任务执行完成 countDownLatch.await(); System.out.println("程序执行完成~"); }②. CyclicBarrier
CyclicBarrier(循环屏障)通过它可以实现让一组线程等待满足某个条件后同时执行。 CyclicBarrier 经典使用场景是公交发车,为了简化理解我们这里定义,每辆公交车只要上满 4 个人就发车,后面来的人都会排队依次遵循相应的标准。 CyclicBarrier 使用代码如下:
import java.util.Date; import java.util.Random; import java.util.concurrent.*; public class CyclicBarrierExample { public static void main(String[] args) { // 创建 CyclicBarrier final CyclicBarrier cyclicBarrier = new CyclicBarrier(2, new Runnable() { @Override public void run() { System.out.println("人满了,准备发车:" + new Date()); } }); // 线程调用的任务 Runnable runnable = new Runnable() { @Override public void run() { // 生成随机数 1-3 int randomNumber = new Random().nextInt(3) + 1; // 进入任务 System.out.println(String.format("我是:%s 再走:%d 秒就到车站了,现在时间:%s", Thread.currentThread().getName(), randomNumber, new Date())); try { // 模拟执行 TimeUnit.SECONDS.sleep(randomNumber); // 调用 CyclicBarrier cyclicBarrier.await(); // 任务执行 System.out.println(String.format("线程:%s 上车,时间:%s", Thread.currentThread().getName(), new Date())); } catch (InterruptedException e) { e.printStackTrace(); } catch (BrokenBarrierException e) { e.printStackTrace(); } } }; // 创建线程池 ExecutorService threadPool = Executors.newFixedThreadPool(10); // 执行任务 1 threadPool.submit(runnable); // 执行任务 2 threadPool.submit(runnable); // 执行任务 3 threadPool.submit(runnable); // 执行任务 4 threadPool.submit(runnable); // 等待所有任务执行完终止线程池 threadPool.shutdown(); } }CountDownLatch 和 CyclicBarrier 内部都是使用计时器实现的,但 CountDownLatch 的计数器只能使用一次,而 CyclicBarrier 的计数器可以循环使用,这就是二者最大的区别。
# 四.MySql模块
# 用自己的话说一下什么是三范式?为什么要遵循三范式?实际开发中一定要严格遵循三范式吗?为什么?
数据库三范式的具体内容如下:
第一范式(1NF:First Normal Form):第一范式规定表中的每个列都应该是不可分割的最小单元。
- 含义说明:也就说,一个属性不能包含多个值,例如,不能将地址中的省、市、区存储在一个字段中,而是要分成多个字段分别进行存储。
第二范式(2NF:Second Normal Form):在满足第一范式的基础上,第二范式要求数据库表中的每个非主键列都必须完全依赖于整个主键,而不能只依赖于主键的一部分。
- 含义说明:这意味着如果一个表有两个或更多的独立字段组成联合主键,那么其他非主键列的值必须与整个主键相关,而不能只与联合主键的一部分相关。
第三范式(3NF:Third Normal Form):在满足第二范式的基础上,第三范式进一步要求数据库表中的每个非主键列都必须直接依赖于主键,而不能依赖于其他非主键列。
- 含义说明:这样可以消除传递依赖,避免数据冗余和更新异常。
用自己的话说一下什么是三范式?
- 第一范式是将列分割成最小单元。
- 第二范式是每个字段都必须和所有主键完全相关。
- 第三范式是每个字段不能和主键间接相关。
为什么要遵循三范式?
遵循数据库三范式是主要用于减少数据冗余和方便后续的维护和更新。
实际开发中一定要严格遵循三范式吗?为什么?
实际开发中,并不会严格遵循三范式,因为在实际工作中除了要考虑设计规范三范式之外,还要考虑查询的性能。
例如,某些场景如果要严格遵循三范式,那么可能需要将多个字段存储到多张表中进行查询,而多张表的联查效率是非常低的,这样情况下为了满足性能的需求,我们通常会涉及成冗余字段存放到更少的表中,以减少联表查询的性能开销,这就是使用空间换时间的做法。
# 关系型数据库和非关系数据库有什么区别?它们对应的使用场景分别有哪些?
关系型数据库介绍
关系型数据库(RDBMS)是基于关系模型的数据库,使用表格结构来组织和存储数据,数据是以行和列的形式存储,并且可以通过定义主键和外键来建立表之间的关系。
关系型数据库的特点主要有以下几个:
- 统一数据结构:数据以表格的形式存储,表格由行和列组成,每个列都有对应的数据类型,提供了规范和结构化的数据存储方式。
- 强一致性:关系型数据库遵循 ACID(原子性、一致性、隔离性、持久性)原则,保证数据的一致性和事务的完整性。
- 数据完整性:关系型数据库支持定义表之间的关联关系,通过主键和外键进行数据的完整性约束。
- 丰富的查询功能:通过 SQL 查询语言,可以进行复杂的关系查询和连接操作,支持多表查询、条件查询、聚合查询等。
关系型数据库的典型代表有:OracleDB、MySQL、SQL Server(Microsoft)、PostgreSQL、DB2(IBM)等。
非关系型数据库介绍
非关系型数据库,或称为 NoSQL(Not Only SQL)数据库,是一种不同于传统关系型数据库的数据库系统。它们不依赖于表格和关系模型,而是采用各种不同的数据模型(如键值对、文档、列族、图等)来存储和管理数据,并且放宽了对数据一致性的要求。
非关系型数据库的特点主要有以下几个:
- 灵活的数据模型:非关系型数据库可以根据应用的需求选择和定制适合的数据模型,例如键值对、文档、列族、图等,以满足不同场景和数据结构的存储需求。
- 高可扩展性:非关系型数据库天生支持分布式计算和存储,可以方便地进行横向扩展,以应对大规模数据和高并发访问的需求。
- 高性能和可用性:由于非关系型数据库放宽了对一致性的要求,可以进行异步写入和读写分离等优化,从而获得较好的性能和可用性。
非关系型数据库的典型代表有:MongoDB、Redis、HBase、Neo4j 等。
关系型数据库 VS 非关系型数据库
它们的区别主要体现在以下几点:
数据模型不同:
- 关系型数据库:基于关系模型,数据以表格的形式存储,每个表都有预定义的列和数据类型。表与表之间通过外键建立关系,形成一个相互关联的数据集合。
- 非关系型数据库:不采用表格和关系模型,数据可以以各种形式存储,如键值对、文档、图形等。
数据结构不同:
- 关系型数据库:数据结构严格,需要预先定义好表结构和字段类型,数据修改通常需要遵循一定的规范和约束。
- 非关系型数据库:数据结构灵活,无需预先定义严格的模式,可以根据需要随时添加或修改数据结构。
查询语言不同:
- 关系型数据库:通常使用 SQL(Structured Query Language)进行查询,支持复杂的查询条件、联接操作和聚合函数。
- 非关系型数据库:查询语言因数据库类型而异,有些支持类似 SQL 的查询语法(如 MongoDB 的 MongoDB Query Language),有些则使用特定的 API 或 DSL(领域特定语言)。
事务支持不同:
- 关系型数据库:通常支持 ACID(Atomicity, Consistency, Isolation, Durability)事务特性,保证数据的一致性和完整性。
- 非关系型数据库:事务支持程度因数据库类型而异,只有少量的 NoSQL 数据库可能只提供部分 ACID 特性,或者采用不同的一致性模型(如最终一致性)。
扩展性与性能不同:
- 关系型数据库:传统的关系型数据库在水平扩展方面可能存在挑战,通常通过垂直扩展(增加单台服务器的硬件资源)来提高性能。
- 非关系型数据库:设计上通常更易于水平扩展,通过添加更多服务器来分散数据和负载,以应对大规模数据和高并发访问。
应用场景
- 关系型数据库:适用于需要高度一致性和复杂查询的场景,如金融交易、企业级应用和内容管理系统等。
- 非关系型数据库:适用于海量数据存储、日志系统、大数据分析、实时处理、Web 应用和移动应用等领域,尤其在处理半结构化和非结构化数据时具有优势。
# MySQL 常用引擎有哪些?
MySQL 常用的存储引擎有以下几个:
InnoDB:MySQL(5.5+)的默认存储引擎,支持事务处理、行级锁定和物理外键约束。
- 特性:提供良好的数据一致性、崩溃恢复和高并发性能。
- 使用场景:适用于需要事务支持和多用户读写操作的应用场景。
MyISAM:MySQL 早期的默认存储引擎,不支持事务和行级锁定。
- 特性:提供快速的读取速度和较小的数据存储文件。
- 使用场景:适用于只读或读多写少的应用场景,不需要事务的场景。
MEMORY:将表的数据存储在内存中,提供极快的访问速度。
- 特性:数据在服务器重启后会丢失。
- 使用场景:适用于临时表、缓存表或者需要快速查询的小型表。
# InnoDB 和 MyISAM 有什么区别?
InnoDB 和 MyISAM 是 MySQL 中两种常用的存储引擎,它的区别主要体现在以下几点:
- 事务支持不同:InnoDB 支持事务,MyISAM 不支持事务。
- 锁粒度不同:InnoDB 支持最小的锁粒度为行级锁,而 MyISAM 支持最小的锁粒度是表级锁。
- 外键支持不同:InnoDB 支持物理外键,而 MyISAM 不支持物理外键。
- 索引存储方式不同:InnoDB 索引叶子节点存储的是当前行的数据,而 MyISAM 索引叶子节点存储的是地址,根据地址才能获取当前行的数据。
# 为什么阿里巴巴《Java开发手册》不建议使用物理外键?使用物理外键会带了什么问题?
阿里巴巴《Java开发手册》对于外键的规定如下:
【强制】不得使用外键与级联,一切外键概念必须在应用层解决。 说明:(概念解释)学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学 生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。 外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度。
也就是说使用物理外键会带来问题:
- 性能问题:插入之前会先去主键中查询,性能较慢。
- 可能会带来数据库更新风暴问题:数据库更新风暴是指在一个较短的时间内,大量并发的数据库更新操作集中发生,导致数据库服务器在处理这些请求时面临巨大压力,可能引发性能瓶颈、延迟增大甚至系统崩溃的现象。这种情况通常发生在高并发场景下。
# 物理删除和逻辑删除有什么区别?日常开发中会使用哪种删除方式?为什么?
物理删除和逻辑删除的定义如下:
- 物理删除:物理删除是指直接从数据库中永久删除数据记录。物理删除会直接删除相应的数据库行,并释放相关的存储空间。被删除的数据将无法恢复,且不再对应原有的唯一标识。
- 逻辑删除:逻辑删除是指在程序中实现“删除功能”,通常是通过添加一个标记字段或者状态字段来标记该数据为已删除状态。逻辑删除不会直接删除数据记录,而是将数据状态字段标记为已删除状态,表示该数据不再有效。 逻辑删除可以在业务逻辑上使数据不可见,但数据仍然存在于数据库中。逻辑删除可以通过修改查询条件来筛选出未删除或已删除状态的数据。
在日常开发中,使用哪种删除方式会取决于具体需求和业务场景。
- 大部分情况下,对重要的数据,在数据库空间和性能满足的情况下,会采用逻辑删除。这样的好处是可以保留历史数据,方便后续数据恢复和保证数据的完整性。
- 但是如果数据不重要,例如具有时效性的一些日志数据,且数据库对性能和空间有要求的场景下,会使用物理删除来节约系统空间,和提高查询性能。
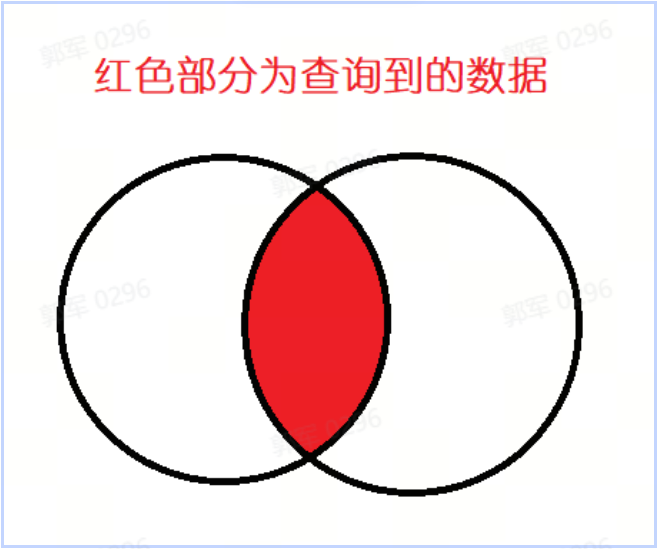
# 内连接和外连接有什么区别?什么是自连接?举例说明一下?
内连接(INNER JOIN):返回两个表中存在匹配记录的行组合。结果集只包含两个表中键值相等的行。
外连接(OUTER JOIN):外连接分为左外连接(LEFT JOIN 或 LEFT OUTER JOIN)、右外连接(RIGHT JOIN 或 RIGHT OUTER JOIN)和全外连接(FULL JOIN 或 FULL OUTER JOIN)。
- 左外连接:返回所有左表的记录,以及与右表匹配的记录。如果右表没有匹配的记录,则结果集中对应的右表字段为 NULL。
- 右外连接:返回所有右表的记录,以及与左表匹配的记录。如果左表没有匹配的记录,则结果集中对应的左表字段为 NULL。
- 全外连接:返回所有左表和右表的记录,以及两表之间的匹配记录。如果一方没有匹配的记录,则另一方的对应字段为 NULL。
它们的区别是:内连接会查询并返回两个表中的都存在的数据,如下图所示:
而左外连接是左表的所有数据和右表匹配到的数据,如下图所示:
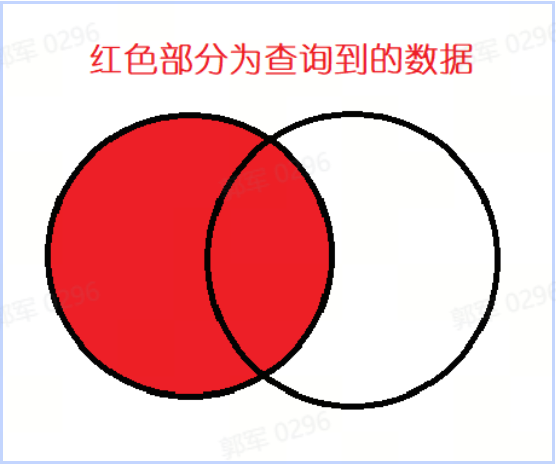
右外连接查询的数据如下图所示:
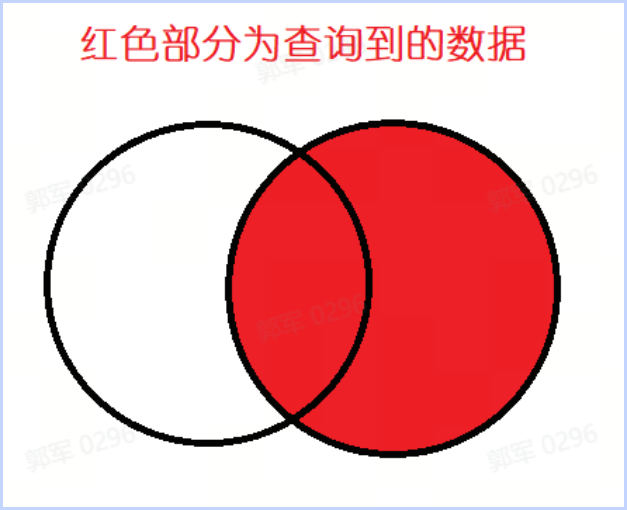
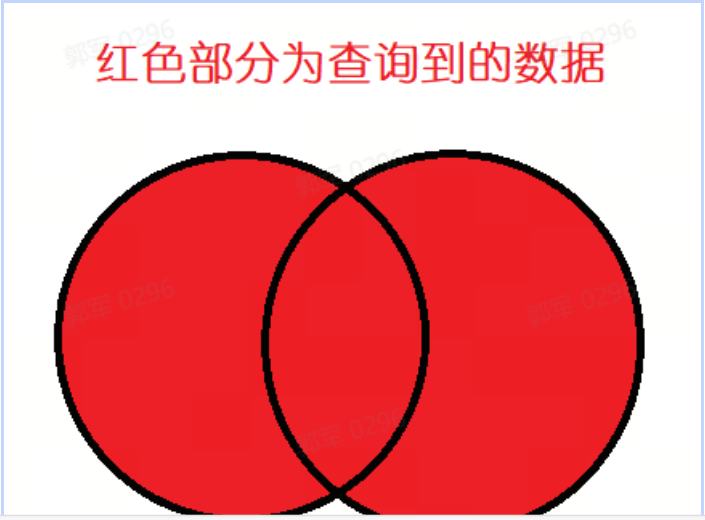
全外查询到的数据如下图所示:
什么是自连接?举例说明
自连接(SELF JOIN):一种特殊的内连接或外连接,用于在同一个表中关联不同的行。通常通过给表别名来实现。
SELECT u1.name AS u_name, u2.name AS manager_name FROM users u1 LEFT JOIN users u2 ON u1.manager_id = u2.id;# 创建索引时会锁表吗?为什么?
在 MySQL 5.6 之前,创建索引时会锁表,所以,在早期 MySQL 版本中一定要在线上慎用,因为创建索引时会导致其他会话阻塞(select 查询命令除外)。
但这个问题,在 MySQL 5.6.7 版本中得到了改变(不再锁表了),因为在 MySQL 5.6.7 中引入了 Online DDL 技术(在线 DDL 技术),它允许在创建索引时,不阻塞其他会话,也就是不再锁表了(所有的 DML 操作都可以一起并发执行)。
Online DDL(Online Data Definition Language,在线数据定义语言)是指在数据库运行期间执行对表结构或其他数据库对象的更改操作,而不需要中断或阻塞其他正在进行的事务和查询。
# 聚簇索引和非聚簇索引有什么区别?
聚簇索引的叶子节点(最底层节点)存储的是数据本身(行数据),而非叶子节点(非最底层节点)存储的是索引键(通常是主键),如下图所示:
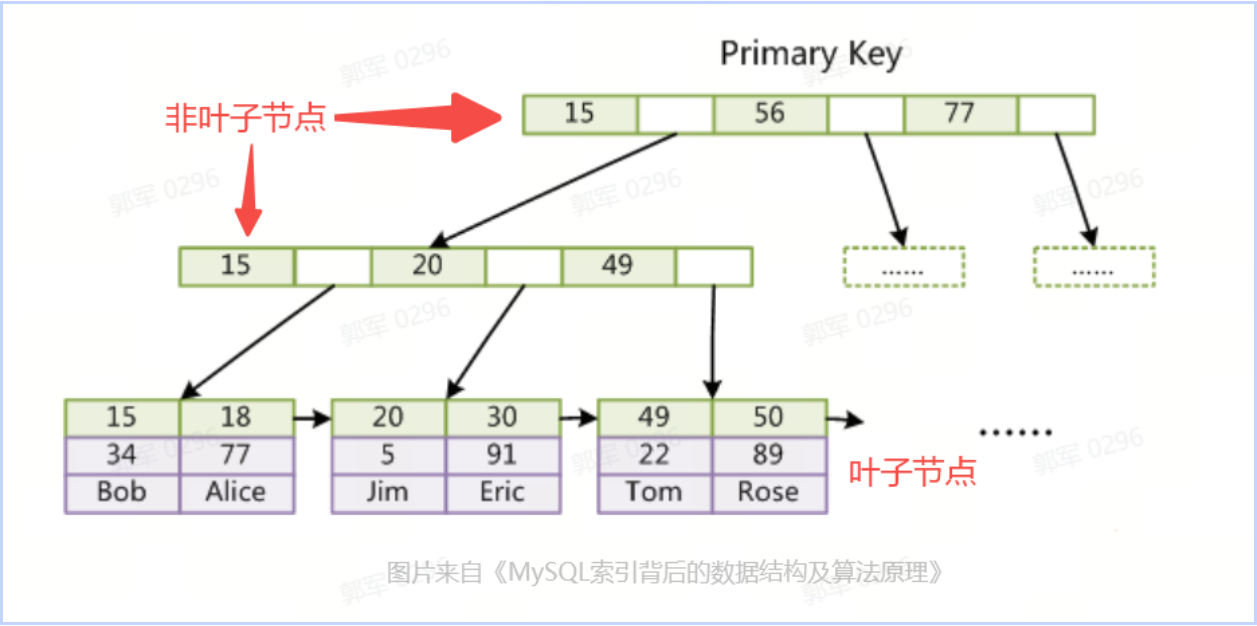
叶子节点(Leaf Node)是指没有子节点的节点。它是树的末端节点,也被称为终端节点或终端叶子节点。
非聚簇索引的叶子节点存储的是聚簇索引键(通常是主键),而非数据本身,如下图所示:
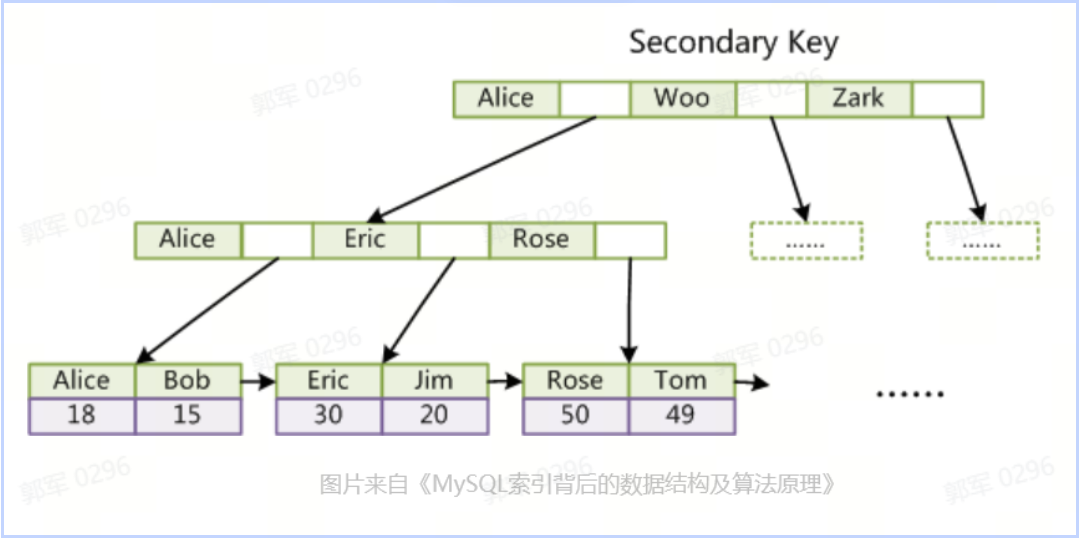
# 聚簇索引等于主键索引吗?聚簇索引的生成规则是啥?
聚簇索引大多数情况下等于主键索引(如果主键索引存在的情况下),但如果表中没有主键索引的情况下,聚簇索引就等于其他索引类型了。
聚簇索引的生成规则
如果有主键索引时,那么聚簇索引就等于主键索引,如果没有主键索引,那么聚簇索引的诞生流程依次如下:
- 无主键索引,则使用非空唯一索引:如果表中没有主键索引,那么 InnoDB 会使用第一个唯一索引(unique),且此唯一索引设置了非空约束(not null),我们就使用它作为聚簇索引。
- 无任何满足索引,则生成隐藏聚簇索引:如果一张表既没有主键索引,又没有符合条件的唯一索引,那么 InnoDB 会生成一个名为 GEN_CLUST_INDEX 的隐藏聚簇索引,这个隐藏的索引为 6 字节的长整数类型。
# 索引底层是如何实现的?
MySQL 索引的底层实现取决于存储引擎,但大部分的存储引擎的底层是通过 B+ 树实现的,以默认的存储引擎 InnoDB 为例,其底层是通过 B+ 树实现的,如下图所示:
 B+ 树是一种自平衡的、多路搜索树,它的主要特征包含以下几点:
B+ 树是一种自平衡的、多路搜索树,它的主要特征包含以下几点:- 非叶子节点只存储键值和指向子节点的指针。
- 所有叶子节点(最底层的节点)都在同一个级别,并且包含所有的键值和对应的数据行指针或行数据。
- 所有叶子节点在同一层上,并通过双向链表连接,便于范围查询。
# InnoDB索引、MyISAM索引和MEMORY索引底层实现一样吗?
InnoDB 索引、MyISAM 索引和 MEMORY 索引底层实现都不太一样,其中:
- InnoDB 索引底层是通过 B+ 树实现的,并且其叶子节点为整行数据。
- MyISAM 索引底层也是通过 B+ 树实现的,但其叶子节点存储的是内存地址,要根据内存地址寻址才能找到这行数据。
- Memory 索引底层不是通过树实现的,因为其主要为内存引擎,并且适合存储键值数据,所以它使用的是哈希结构实现的索引。
# 索引为什么要使用B+树,其他数据类型不行吗? 为什么?
既然是做索引,那么查询性能就是第一优先考虑条件,而树结构比其他数据类型,例如:链表、队列、栈等查询效率都高,所以首先一定大方向是使用树结构。
哈希索引的查询效率也很高,但没办法进行范围查询,所以也不合适作为大部分存储引擎的底层数据结构。
而树又分为二叉树搜索树和多叉搜索树,而二叉搜索树的每个节点只有一个或两个子节点,这意味着查找一个元素可能需要多次 I/O 操作,而多路搜索树(如 B 树和 B+ 树)的每个节点可以有多个子节点,这使得每个层级可以包含更多的数据,从而减少了查询过程中所需的 I/O 次数。而 I/O 次数是查询中最慢的操作,所以使用多叉搜索树比二叉树更适合做索引。
在多叉树 B+ 树相比于 B 树有以下几点主要优势,所以它更适合做索引:
- IO 次数更少(查询效率更高):B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比即存储索引又存储数据的 B 树来说,B+ 树的非叶子节点可以存放更多的索引,因此在查询时 I/O 次数更少,查询效率更高。
- 范围查询性能更高:B+ 树叶子节点之间用链表连接了起来,有利于范围查询;而 B 树要实现范围查询,因此只能通过树的遍历来完成范围查询,这会涉及多个节点的磁盘 I/O 操作,范围查询效率不如 B+ 树。
- 插入和删除性能更好:B+ 树有大量的冗余节点(所有非叶子节点都是冗余索引),这些冗余索引让 B+ 树在插入、删除的效率都更高,比如删除根节点的时候,不会像 B 树那样会发生复杂的树的变化。
# 索引的类型有哪些?
在 MySQL 中索引有很多种分类方法,按照不同的维度,其分类也是不同的。
例如,可以按照字段特性分类、物理存储结构分类或索引的数量等维度进行分类,具体内容如下。
①字段特性分类
- 主键索引:一张表只能有一个主键索引,不允许重复、不允许为 NULL。
- 唯一索引:数据列不允许重复,允许为 NULL 值,一张表可有多个唯一索引,但是一个唯一索引只能包含一列,比如身份证号码、卡号等都可以作为唯一索引。
- 普通索引:一张表可以创建多个普通索引,一个普通索引可以包含多个字段,允许数据重复,允许 NULL 值插入。
- 全文索引:让搜索关键词更高效的一种索引。
②物理存储结构分类
- 聚簇索引(聚集索引):一般是表中的主键索引,如果表中没有显示指定主键,则会选择表中的第一个不允许为 NULL 的唯一索引,如果还是没有的话,就采用 Innodb 存储引擎为每行数据内置的 6 字节 ROWID 作为聚簇索引或聚集索引。每张表只有一个聚集索引,因为聚集索引的键值的逻辑顺序决定了表中相应行的物理顺序。聚集索引在精确查找和范围查找方面有良好的性能表现(相比于普通索引和全表扫描),聚集索引就显得弥足珍贵,聚集索引选择还是要慎重的(一般不会让没有语义的自增 id 充当聚集索引)。
- 非聚簇索引:也叫做二级索引或辅助索引,该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同(非主键的那一列),一个表中可以拥有多个非聚簇索引。
③ 索引数量分类
- 单列索引:是指对表中的单个列创建的索引。它可以根据该列的值快速定位到对应的记录。单列索引适用于对单个列进行频繁的查询、排序和过滤操作的场景。例如,对于一个用户表,可以为用户 ID 列创建单列索引,以便快速根据用户 ID 进行查询。
- 联合索引(也称为复合索引或组合索引):是指对表中的多个列创建的索引。它可以根据多个列的值进行排序和搜索。组合索引适用于需要同时根据多个列进行查询、排序和过滤操作的场景。例如,对于一个订单表,可以为订单日期和订单状态两列创建组合索引,以便快速根据日期和状态进行查询和排序。
# 什么是最左匹配原则? 为什么要遵循最左匹配原则?
最左匹配原则是指在使用多列联合索引时,索引可以从左到右按顺序匹配查询条件,并提供有效的索引访问。最左匹配原则要求,查询中的条件必须按照联合索引的顺序,从最左边的列开始出现,并且不能跳过任何中间的列。
需要注意的是,在最左匹配的过程中如果遇到范围查询(>、<、between、like)就会停止匹配,其中范围列可以用到索引,但是范围列后面的列无法用到索引,即索引最多用于一个范围列。
为什么一定要遵循最左匹配原则?
因为对于联合索引来说,它在构造 B+ 树的时候,会先按照左边的 key 进行排序,左边的 key 相同时,再依次按照右边的 key 排序,如下图所示:
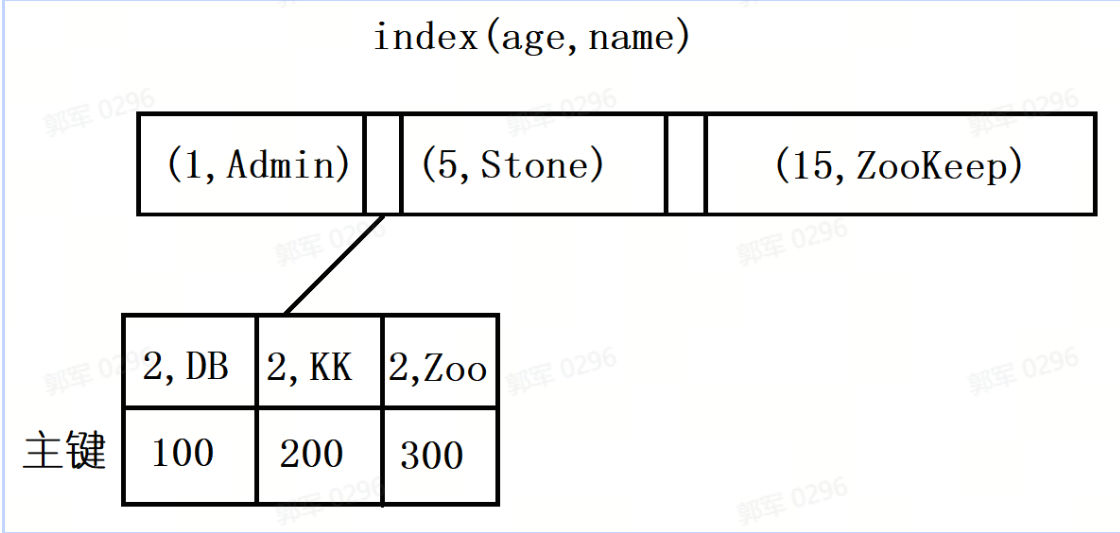
因此,在进行联合查询的时候,必须要遵守最左匹配原则,也就是需要从联合索引的最左边开始进行匹配,才能够准确的进行匹配。 16. #### 日常工作中,如何排查某个SQL是否正确使用了索引? 在日常工作中,可以使用 SQL 查询计划,也就是 explain 来排查某个 SQL 是否使用了索引,以此来实现索引失效排查的问题。 explain 查询计划如下图所示:
 查询结果中的字段有很多,我们关注的字段主要有以下两个:
查询结果中的字段有很多,我们关注的字段主要有以下两个:- type:表示查询时使用的访问方法或策略,描述了 MySQL 在执行查询时如何访问数据。常见的 type 值包括:
- ALL:全表扫描,表示 MySQL 将扫描整个表来找到匹配的行。
- index:索引扫描,表示 MySQL 将通过索引进行扫描,但可能需要回表访问数据行。
- range:范围扫描,表示 MySQL 将使用索引的范围条件来定位匹配的行。
- ref:使用非唯一索引进行查找,返回匹配某个值的所有行。
- eq_ref:使用唯一索引进行查找,返回匹配某个值的单个行。
- const:使用常量值进行查找,通常是通过主键或唯一索引进行精确匹配。
- NULL:无效或未知的访问类型。
- key:- 表示查询时使用的索引。如果查询使用了索引,key 字段将显示使用的索引名称;如果查询没有使用索引,key 字段将显示 NULL。
也就说,当 explain 查询计划中的 key 不等于 NULL,并且 type 等于 index、range、ref、eq_ref、const 等时都表示此语句执行了索引查询,也就是索引并未失效。
- type:表示查询时使用的访问方法或策略,描述了 MySQL 在执行查询时如何访问数据。常见的 type 值包括:
# 索引失效的场景有哪些?
索引失效的场景有以下几种:
- 联合索引非最左匹配:当使用联合索引时,未遵循最左匹配原则,则不能正常使用索引,也就是索引失效了。
- 不当模糊查询:模糊查询 like 的常见用法有 3 种(只有第 1 种的会走索引,其他都会导致索引失效):
- 模糊匹配后面任意字符:like '张%'。
- 模糊匹配前面任意字符:like '%张'。
- 模糊匹配前后任意字符:like '%张%'。
- 使用列运算:如果索引列使用了运算,那么索引也会失效。
- 使用函数:查询列如果使用任意 MySQL 提供的函数就会导致索引失效。
- 类型转换:如果索引列存在类型转换,那么也不会走索引,比如某列为字符串类型,而查询的时候设置了 int 类型的值就会导致索引失效。
- 使用 is not null:当在查询中使用了 is not null 也会导致索引失效,而 is null 则会正常触发索引的。
- 使用 or 操作符:当查询条件包含 or 连接的条件,索引也会失效。
# 索引和MySQL中的约束有什么关系?
在 MySQL 中,索引和约束是完全不同的两个概念,其中:
- 索引:一种用于提高查询性能的数据结构,用于加快数据库表的数据检索速度。索引可以通过在列或多个列上创建索引来建立,并且可以使用 B+ 树的数据结构来维护索引的有序性。索引可以加速数据检索,减少磁盘 IO,提高查询效率。在 MySQL 中,可以对表中的列或列组合创建索引,以加速对这些列的查询。
- 约束:一种用于保证数据完整性和一致性的规则。约束可以定义在表和列级别,用于限制表中的数据、列的取值范围以及列之间的关系。常见的约束包括主键约束(PRIMARY KEY)、唯一约束(UNIQUE KEY)、非空约束(NOT NULL)和外键约束(FOREIGN KEY)等。约束可以作为数据的规则进行强制检查,以确保数据的一致性和完整性。
然而,在某些场景下,创建约束时为了加速查询性能所以会自动生成索引,例如以下这些:
- 主键约束(PRIMARY KEY):主键约束定义了表中的一列或多列的唯一性,并且 MySQL 会自动为主键创建一个唯一索引。这意味着当你声明一个字段为 PRIMARY KEY 时,数据库不仅确保该字段的值在全表内是唯一的,还会建立一个用于高效查找行记录的索引。
- 唯一约束(UNIQUE):唯一约束也要求指定列的值必须是唯一的,与主键类似,MySQL 也会为带有 UNIQUE 约束的列创建一个唯一索引,以支持高效的唯一性检查和查询。
- 外键约束(FOREIGN KEY):虽然外键约束本身并不直接创建索引,但在实践中,为了保证对外键引用效率,通常会在外键列上创建索引,以便快速定位到被引用的数据行。
但是,并不是所有的约束都会自动生成索引,例如非空约束就不会自动生成索引。
# 什么是索引覆盖?它给我们提供了什么启示?
索引覆盖(Index Covering)是指查询语句可以完全通过索引来满足,而无需进一步访问表的数据。当一个查询仅需要从索引中获取所需的数据列,而不需要访问表的实际数据行时,就称为索引覆盖。通过索引覆盖,可以减少对磁盘和内存的读取,提高查询的性能。
例如,select id from table where age between 18 and 22,其中 id 为主键,而 age 为二级索引,这时的 SQL 只需要查询主键 id 的值,而 id 的值已经在 age 索引树上了,因此可以直接提供查询结果,不需要回表,这就叫做覆盖索引。
索引覆盖给我们的启示是,在实际工作中,能不使用 select * 就不要使用 select *,因为 select * 一定会进行回表查询,降低查询的效率,并且因为其包含的信息较多,所以也会增加网络带宽的负担,传输效率被拖慢等问题。
# 什么是索引下推?为什么要有索引下推?
索引下推(Index Condition Pushdown,简称 ICP)是指在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数就叫索引下推。
索引下推是 MySQL 5.6 版本中引入的功能。
例如,以市民表的联合索引(name, age)为例,如果现在有一个需求:检索出表中“名字第一个字是张,而且年龄是 10 岁的男孩”,SQL 语句是这么写的:
select * from tuser where name like '张%' and age=10 and ismale=1;这个语句在搜索索引树的时候,只能用 “张”,找到第一个满足条件的记录 ID3,如下图所示:
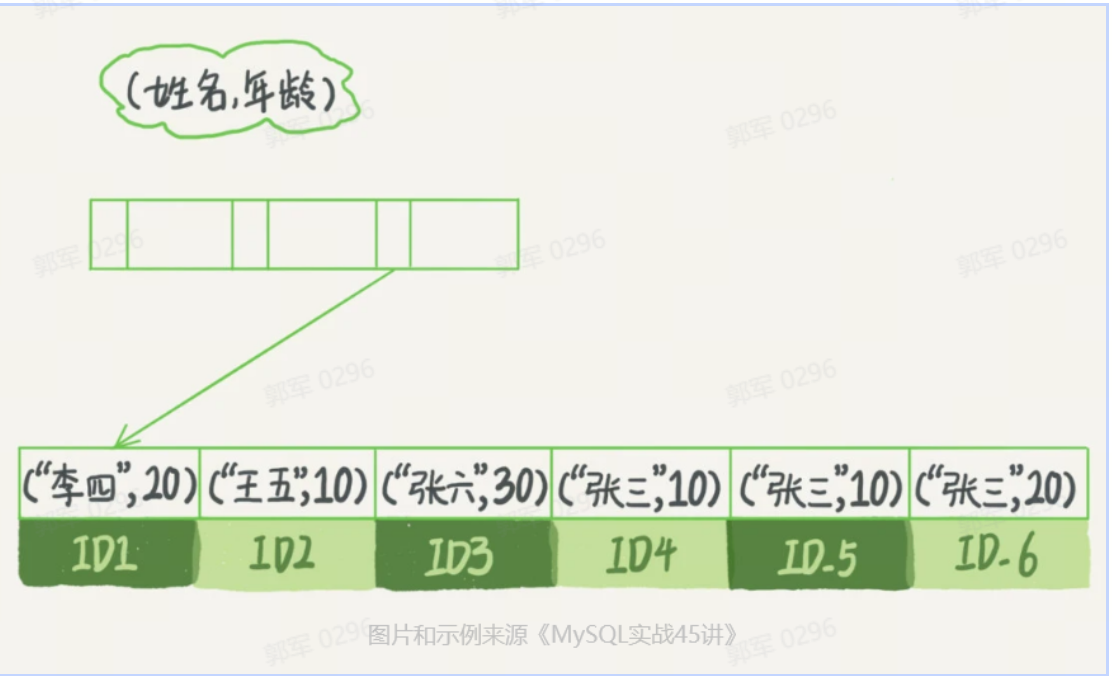
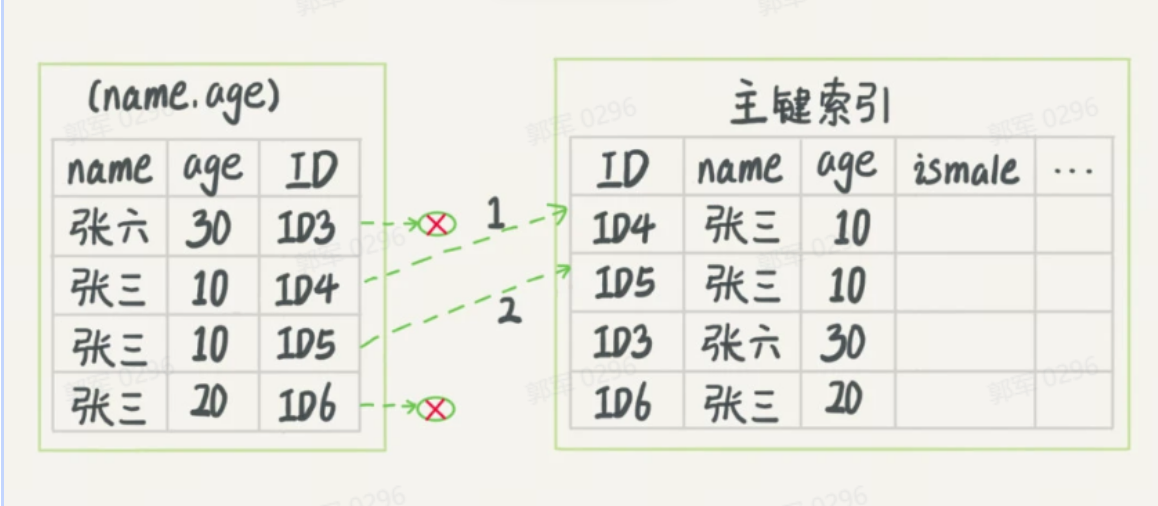
在 MySQL 5.6 之前,查询流程如下图所示,只能根据 name 查询到结果,然后开始回表匹配 age 和 ismale,如下图所示:

而到了 MySQL 5.6 之后,因为有了索引下推技术,它会对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,然后再进行回表查询,所以它的执行流程是这样的:
# 什么是事务?为什么需要事务?
事务(Transaction)是保证数据库可靠性和稳定性的一种机制。它是指数据库中的一组操作,要么全部成功执行,要么全部不执行,不存在中间状态。
为什么需要事务?
事务提供了一种逻辑上的一致性和数据完整性的机制,以确保对数据库的更改是可靠性和可恢复性。
# 事务有哪些特性?举例说明一下
事务具有以下四个特性(ACID 特性):
- 原子性(Atomicity):事务中的所有操作要么全部执行成功,要么全部失败回滚,不能只执行其中一部分操作。
- 一致性(Consistency):事务执行前后,数据库的完整性约束没有被破坏,数据总是从一个一致性状态转移到另一个一致性状态。例如,如果一个事务要求将某个账户的金额从 A 转移到 B,那么无论事务是否成功,最终账户 A 和账户 B 的总金额应该保持不变。
- 隔离性(Isolation):事务之间是相互隔离的,每个事务对其他事务的操作是透明的,一个事务的中间结果对其他事务是不可见的。隔离性可以防止并发执行的事务之间产生脏读、不可重复读和幻读等问题。
- 持久性(Durability):事务完成后,对数据库的修改将永久保存在数据库中,即使系统故障也不会丢失。
事务四大特性是为了保证数据库的数据一致性和可靠性的,使得数据库在并发访问和故障恢复等复杂环境下,仍能保持数据的完整性。
# MySQL如何保证事务四大特性?
以默认数据引擎 InnoDB 为例,它保证事务四大特性的手段分别是:
- 原子性是通过 Undo Log(回滚日志) 来保证的。InnoDB 使用日志(Undo Log)来记录事务的操作,包括事务开始、修改数据和事务提交等。如果事务执行失败或回滚,InnoDB 可以使用日志来撤销已经执行的操作,确保事务的原子性。
- 持久性是通过 Redo Log (重做日志) 来保证的。在事务提交之前,InnoDB 会将事务的修改操作先写入事务日志(Redo Log),然后再将数据写入磁盘。即使在系统崩溃或断电的情况下,InnoDB 可以通过重放事务日志来恢复数据,确保事务的持久性。
- 隔离性是通过 MVCC(多版本并发控制) 和锁机制来保证的。
- 一致性是通过各种约束,如主键、外键、唯一性约束等,加上事务的持久性、原子性和隔离性来保证的。
# 在日常开发中哪些功能会使用到事务?举例说明一下
在日常开发中只要涉及到多张表要一起执行的场景,要么一起成功、要么一起失败的情况,都会使用到事务。例如以下这些场景:
- 银行转账业务:需要给一个账号减钱、然后再给另一个账户加钱,这样使用到事务。
- 电商下单业务:在电商系统中的下单业务也需要事务,需要将账户余额扣减、库存扣减、添加订单等操作,这些都需要放到一个事务里。
- 用户中心完善资料业务:当涉及一个系统中有用户完善资料的场景中通常也需要使用事务,因为这个操作通常至少要修改两个表,一个是修改用户主表信息,然后再给用户积分表添加完善资料的积分操作,所以这种场景需要使用到事务。
类似的场景还有很多,大家可以根据自己业务系统的特点,找几个事务的使用场景。
# 在开发中是怎样使用事务的?
在日常开发中,会用到以下事务:
- 本地事务
- 编程式事务
- 声明式事务
- 分布式事务
具体使用如下。
①本地事务
编程式事务
编程式事务有两种实现方式:
- 使用 TransactionTemplate 对象实现编程式事务。
- 使用更加底层的 TransactionManager 对象实现编程式事务。
a.TransactionTemplate 编程式事务
要使用 TransactionTemplate 对象需要先将 TransactionTemplate 注入到当前类中 ,然后再使用它提供的 execute 方法执行事务并返回相应的执行结果,如果程序在执行途中出现了异常,那么就可以使用代码手动回滚事务,具体实现代码如下:
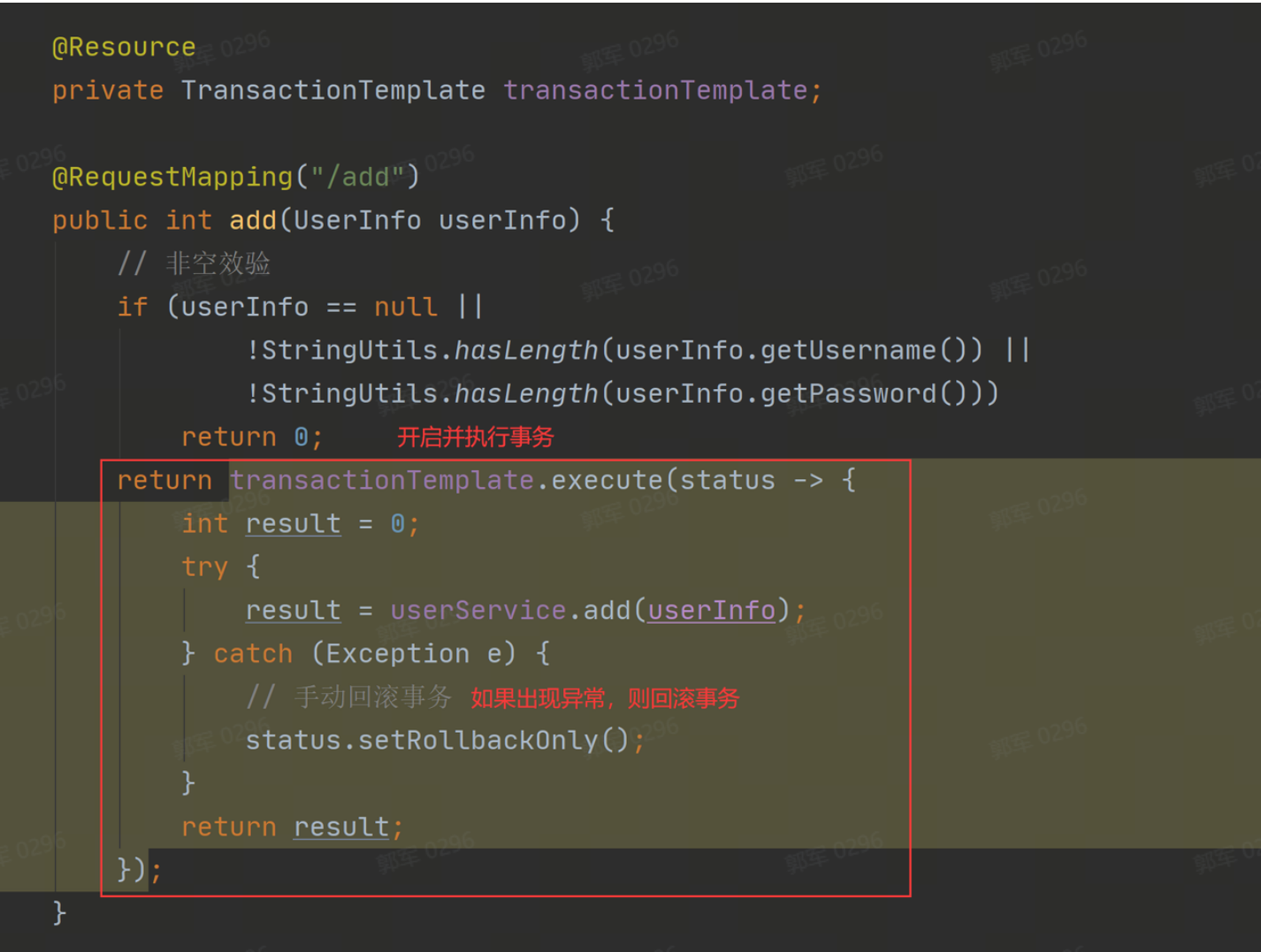
b.TransactionManager 编程式事务
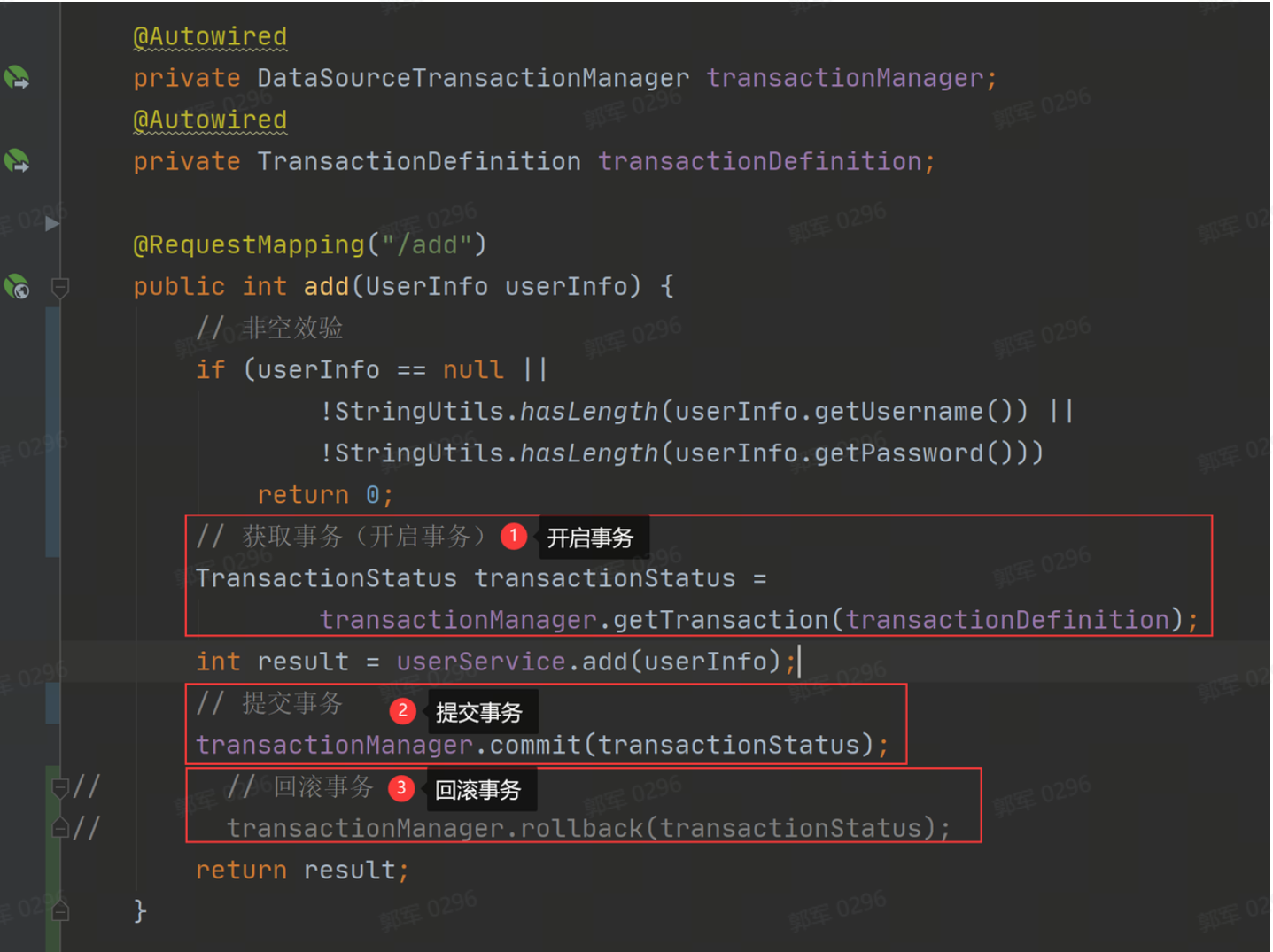
TransactionManager 实现编程式事务相对麻烦一点,它需要使用两个对象:TransactionManager 的子类,加上 TransactionDefinition 事务定义对象,再通过调用 TransactionManager 的 getTransaction 获取并开启事务,然后调用 TransactionManager 提供的 commit 方法提交事务,或使用它的另一个方法 rollback 回滚事务,它的具体实现代码如下:
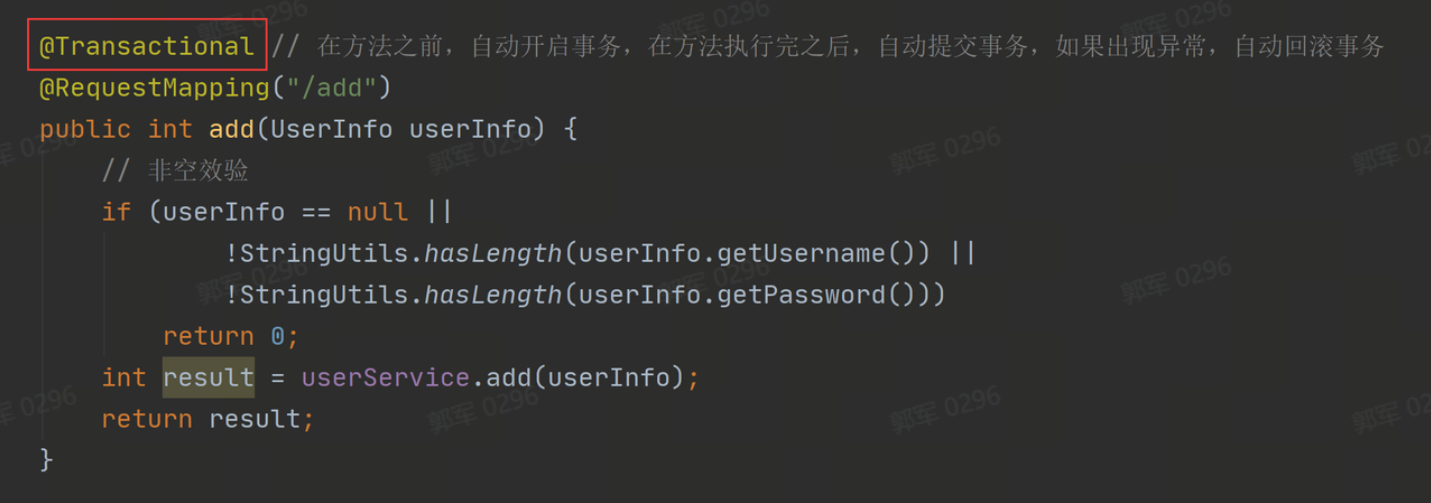
声明式事务
声明式事务的实现比较简单,只需要在方法上或类上添加 @Transactional 注解即可,当加入了 @Transactional 注解就可以实现在方法执行前,自动开启事务;在方法成功执行完,自动提交事务;如果方法在执行期间,出现了异常,那么它会自动回滚事务。
它的具体使用如下:
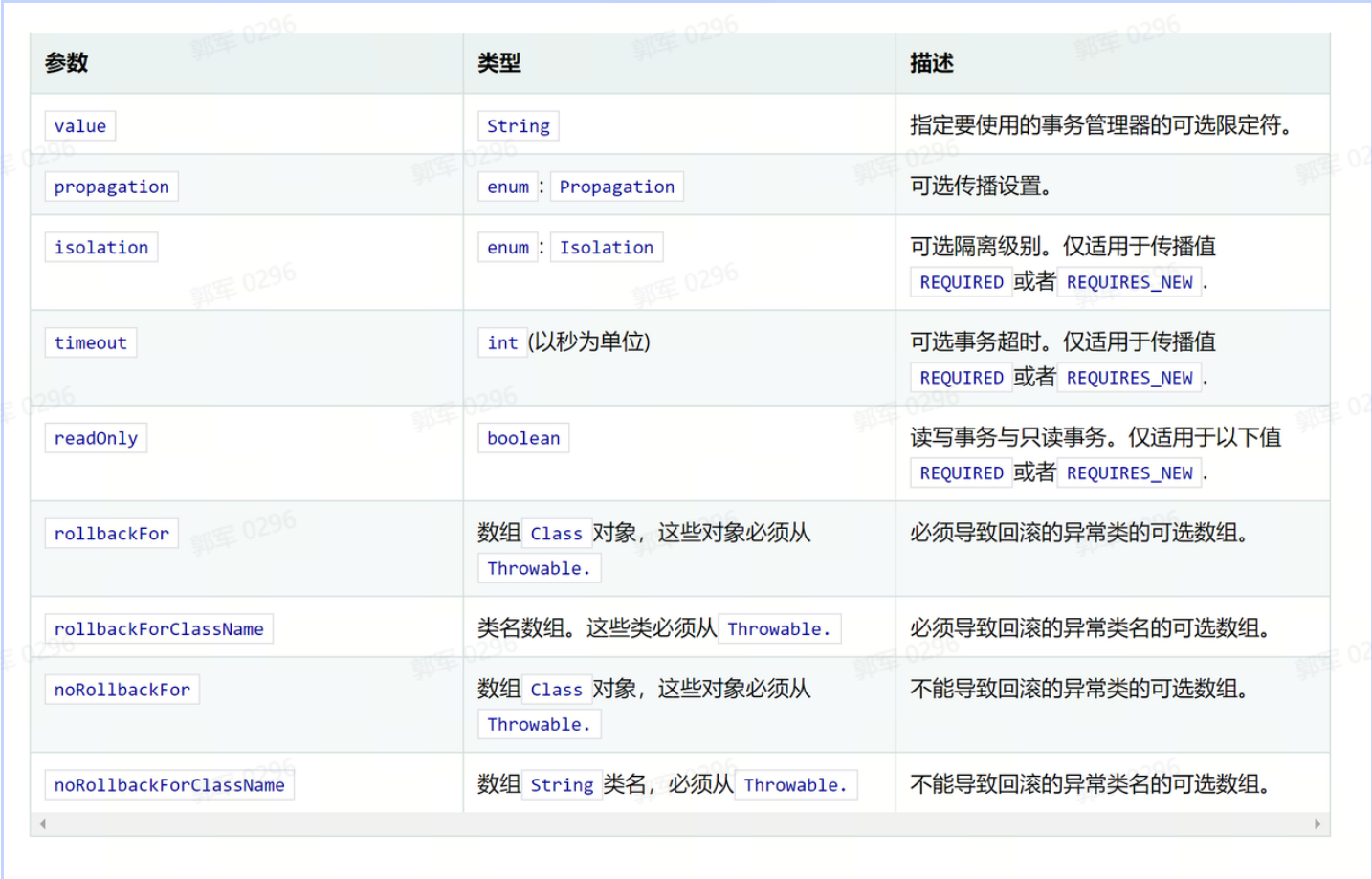
当然,@Transactional 支持很多参数的设置,它的参数设置列表如下:
参数的设置方法如下:
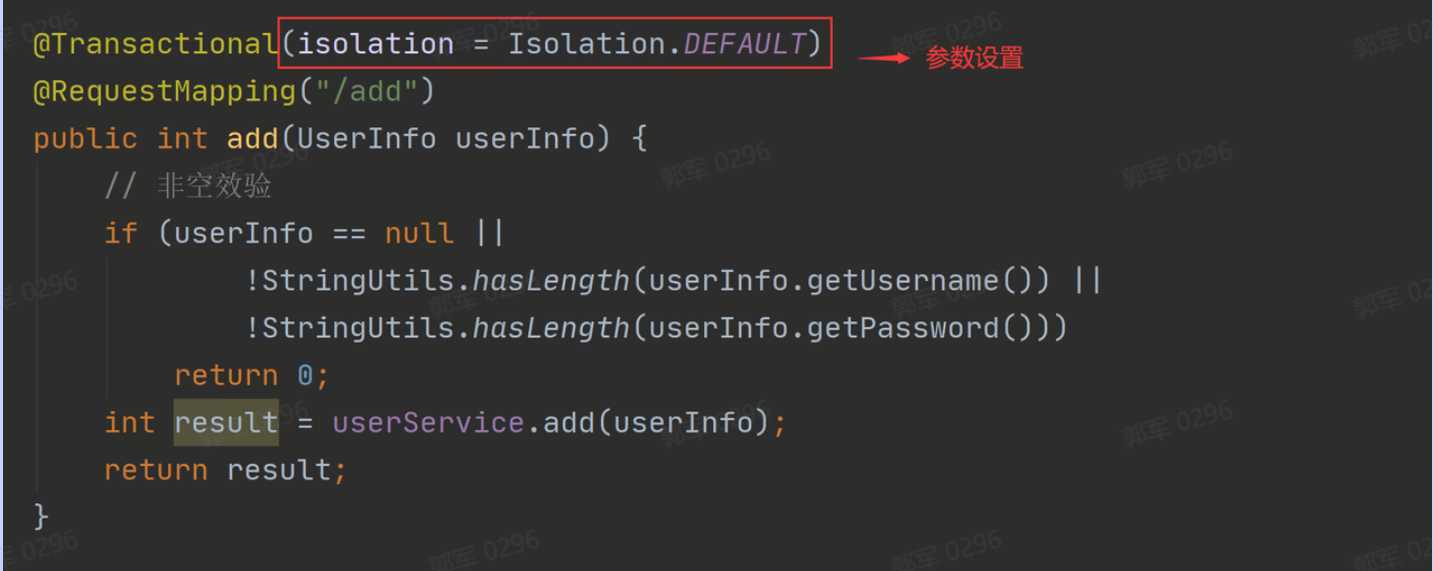
②分布式事务
分布式事务比较常用的是 Spring Cloud Alibaba Seata,通常会采用 Seata 中的 AT 模式来实现,这需要首先部署 Seata 服务,然后再在程序中配置 Seata 服务器信息,之后再通过注解 @GlobalTransactional 就可以使用分布式事务了。 分布式事务的执行流程如下:

- 本地事务
# MySQL中有哪些事务隔离级别?
MySQL 中有事务隔离级别总共有以下 4 种:
读未提交(Read Uncommitted) :最低的隔离级别,事务中未提交的修改数据,可以被其他事务读取到。
- 优点:并发性能最好,读取到的数据最新。
- 缺点:存在脏读(Dirty Read)问题,即读取到未提交的数据,可能导致数据不一致性。
读已提交(Read Committed):事务中未提交的修改数据,不会被其他事务读取到,此隔离级别看到的数据,都是其他事务已经提交的数据。
- 优点:避免了脏读的问题。
- 缺点:存在不可重复读(Non-Repeatable Read)问题,即同一个事务中,不同时间读取到的数据可能不一样。
可重复读(Repeatable Read):是指在一个事务中,多次执行相同的查询语句可能会得到不同的结果,因为其他并发事务在该事务正在进行时修改了数据。
- 优点:避免了不可重复读的问题。
- 缺点:存在幻读(Phantom Read)问题,即在一个事务中,两次查询同一个范围的记录,但第二次查询却发现了新的记录。
串行化(Serializable):最高的隔离级别,将所有的事务串行执行(一个执行完,另一个再执行),保证了数据的完全隔离。
- 优点:避免了幻读的问题。
- 缺点:并发性能最差,可能导致大量的锁等待和死锁。
MySQL 中的事务隔离级别就是为了解决脏读、不可重复读和幻读等问题的,这 4 种隔离级别与这 3 个问题之间的对应关系如下:

# 不可重复读和幻读有什么区别?
不可重复读(Non-Repeatable Read) 是指在一个事务中,多次执行相同的查询语句可能会得到不同的结果,因为其他并发事务在该事务正在进行时修改了数据。
幻读(Phantom Read) 是指在一个事务中,多次执行相同的查询语句可能会返回不同的结果集,因为其他并发事务在该事务正在进行时插入了新的数据行。
不可重复读 VS 幻读
不可重复读和幻读都是并发事务引起的读一致性问题,但两者关注的侧重点和解决方案不同。
侧重点不同:
- 不可重复读关注的是一行数据的变化,它是指在同一个事务中,多次读取同一行数据的结果不一致。这是由于其他并发事务对同一行数据做了修改(例如更新操作),导致两次读取之间数据发生了变化。
- 幻读关注的是范围数据的变化,它是指在同一个事务中,多次查询同一个范围的数据时,结果集的行数发生变化。这是由于其他并发事务在查询范围内插入了新的数据或者从中删除了数据,导致两次查询之间结果集中的行数发生了变化。
解决方案不同:
- 不可重复读通常使用行锁来解决,因为它关注的是一行数据。
- 幻读通常使用间隙锁来解决,因为它关注的是范围数据。
# 如何解决不可重复读和幻读的问题?
不可重复读和幻读都可以通过设置事务的隔离级别来解决,例如将事务隔离级别设置为串行化,那么不可重复读和幻读问题都没有了。但是串行化的执行效率比较低,所以在日常工作中我们是这样解决不可重复读和幻读问题的:
- 解决不可重复读问题:将数据库的隔离级别设置为可重复读 RR 级别(它是 MySQL 默认事务隔离级别)就可以解决不可重复读了。
- 解决幻读问题:通过 MVCC + MySQL 中的锁机制可以解决幻读问题。
# 什么是MVCC机制?它能解决幻读问题吗?为什么?
MVCC(Multi-Version Concurrency Control)是一种并发控制机制,用于解决数据库并发访问中,数据一致性问题。
所谓的一致性问题,就是在并发事务执行时,应该看到哪些数据和不应该看到哪些数据。
在 MVCC 机制中,每个事务的读操作都能看到事务开始之前的一致性数据快照,而不受其他并发事务的修改的影响。核心思想是通过创建多个数据版本,保持事务的一致性和隔离性。
使用 MVCC 机制解决了 RR 隔离级别中,部分幻读问题,但又没把全部幻读问题都解决。
- MVCC 解决了 RR 隔离级别中,快照读的幻读问题。多次查询快照读时,因为 RR 级别是复用 Read View(读视图),所以没有幻读问题。
- 但 MVCC 解决不了 RR 隔离级别中,如果遇到快照读和当前读(读取当前最新的数据)中间发生过添加操作,那么 Read View 不能复用,就出现了幻读的问题。
 所以说 MVCC 可以解决 RR 级别中快照读的幻读问题,但解决不了 RR 级别中的当前读的幻读问题,因为当前读是读取最新数据,此时 MVCC 机制也解决不了幻读问题了,但可以使用锁(Next-Lock)配合 MVCC 彻底解决幻读问题。
所以说 MVCC 可以解决 RR 级别中快照读的幻读问题,但解决不了 RR 级别中的当前读的幻读问题,因为当前读是读取最新数据,此时 MVCC 机制也解决不了幻读问题了,但可以使用锁(Next-Lock)配合 MVCC 彻底解决幻读问题。
# MySQL 有哪些重要的日志?
MySQL 中的重要日志有以下这些:
- 慢查询日志(Slow Query Log):记录执行时间超过指定阈值的查询语句。慢查询日志可以帮助识别性能较差的查询语句,以便进行优化。此日志默认关闭,需要手动开启。
- 二进制日志(Binary Log):记录对数据库进行更改的所有操作,包括 INSERT、UPDATE、DELETE 等。二进制日志可以用于数据恢复、主从复制和数据同步等场景。
- 回滚日志(Undo Log):InnoDB 引擎中的日志,主要用于事务回滚和 MVCC 机制。
- 重做日志(Redo Log):InnoDB 引擎中的日志,主要用于掉电或其他故障恢复的持久化日志。
# 五. Redis模块
# Redis为什么执行这么快?
Redis 运行比较快的原因主要有以下几点:
- 纯内存操作:Redis 将所有数据存储在内存中,这意味着对数据的读写操作直接在内存中进行,而内存的访问速度远远高于磁盘。这种设计使得 Redis 能够以接近硬件极限的速度处理数据读写。
- 单线程模型:Redis 使用单线程模型来处理客户端请求。这可能听起来似乎效率不高,但实际上,这种设计避免了多线程频繁切换和过度竞争所带来的性能开销。Redis 每个请求的执行时间都很短,因此在单线程下,也能够处理大量的并发请求。
- I/O多路复用:Redis 使用了 I/O 多路复用技术,可以在单个线程中同时监听多个客户端连接,只有当有网络事件发生时才会进行实际的 I/O 操作。这样有效地利用了 CPU 资源,减少了无谓的等待和上下文切换。
- 高效数据结构:Redis 提供了多种高效的数据结构,如哈希表、有序集合等。这些数据结构的实现都经过了优化,使得 Redis 在处理这些数据结构的操作时非常高效。
# Redis是单线程执行还是多线程执行?它有线程安全问题吗?为什么吗?
在 Redis 的早期版本中(Redis 6.0 之前)确实是单线程运行的,所有客户端的请求处理、命令执行以及数据读写操作都是在一个主线程中完成。这种设计最初的目的就是为了避免,多线程环境下的锁竞争和上下文切换所带来的性能开销,从而保证高并发场景下的性能。 然而,在 Redis 6.0 版本中,开始引入了对多线程的支持,但这仅限于网络 I/O 层面,即在网络请求阶段使用工作线程进行处理,以提高网络吞吐量。
也就是说,在 Redis 6.0 之后,采用了多个 IO 线程来处理网络请求,网络的请求和解析由这些 IO 多线程来完成的,但解析完成之后,会把解析的结果交由主线程来执行。
所以,即使在 Redis 6.0 当中,也是没有多线程的并发问题的,因为多线程只负责解析网络请求,之后的读写操作都是统一由 Redis 的主线程(单线程)统一来执行的。
# 在实际工作中,使用Redis实现了哪些业务场景?
Redis 在实际工作当中,实现的常见功能有以下几个:
- 缓存服务:Redis 常被用作数据库查询结果或动态生成内容的缓存服务,能够显著提高应用程序的性能。
- 分布式锁:在分布式系统单机锁(synchronized、ReentrantLock)就失去作用了,此时就可以使用 Redis 来实现分布式锁,因为 Redis 天然就是分布式系统,所以使用它来实现分布锁也很方便。
- 存储会话信息:一些小型公司可能会使用 Redis 来存储用户会话信息,还有一些中型公司会使用 Redis 配合 JWT(JSON Web Token,一种登录的认证方式)来实现会话的自动续期功能。
- 布隆过滤器: Redis 4.0 之后,可以根据此版本中提供的 modules (扩展模块) 的方式,非常方便的引入布隆过滤器(插件)的功能了,使用它可以实现大数据下的高性能数据筛查。布隆过滤器的特点是:它说没有的值一定没有,它说有的值有可能没有。
# Redis常用数据类型有哪些?
在 Redis 中,常用的数据类型有以下这些:
- String(字符串):常见使用场景是存储 Session 信息、存储缓存信息(如详情页的缓存)、存储整数信息,可使用 incr 实现整数+1,和使用 decr 实现整数 -1。
- List(列表类型):常见使用场景是实现简单的消息队列、存储某项列表数据。
- Hash(哈希表):常见使用场景是存储 Session 信息、存储商品的购物车,购物车非常适合用哈希字典表示,使用人员唯一编号作为字典的 key,value 值可以存储商品的 id 和数量等信息、存储详情页信息。
- Set(集合):一个无序并唯一的键值集合,它的常见使用场景是实现关注功能,比如关注我的人和我关注的人,使用集合存储,可以保证人员不会重复。
- Sorted Set(有序集合):相比于 Set 集合类型多了一个排序属性 score(分值),它的常见使用场景是可以用来存储排名信息、关注列表功能,这样就可以根据关注实现排序展示了。
PS:有序集合 Sorted Set 也被称为 ZSet,原因是有序列表的底层数据库实现是 ziplist 或 zskiplist,所以也被称之为 ZSet。
# 存储Session信息你会使用哪种数据类型?为什么?
在实际工作中,小型项目会使用 Redis 存储 Session 信息,但不同的业务场景存储 Session 信息的类型也是不同的,具体来说:
- 存储数据简单(不涉及局部更新):使用 String 类型存储 Session,这样做的优缺点如下:
优点:
- 存取操作简单直观,只需要对单个键执行操作即可。
- 对于小型 Session,存储开销相对较小。 缺点:
- 如果 Session 数据复杂或者需要频繁更新其中的部分字段,则每次更新都需要重新序列化整个 Session 对象。
- 不利于查询 Session 内的特定字段值。
- 存储数据复杂(涉及局部更新):如果 Session 数据结构复杂且需要频繁更新或查询其中的个别字段,通常建议使用哈希表来存储 Session。每个 Session 视为一个独立的哈希表(Hash),Session ID 作为 key,Session 内的各个字段作为
field-value 对存储在该哈希表内。示例:HSET session:123 userId 123 username user1,这样做的优缺点如下:
优点:
- 可以方便地进行字段级别的读写操作,例如 HGET session:123 userId 和 HSET session:123 lastAccessTime now。
- 更新部分字段时无需修改整个 Session 内容。 缺点:
- 相对于简单的字符串存储,哈希表占用的空间可能更大,尤其是当 Session 数据包含许多字段时。
小结:如果 Session 数据结构复杂且需要频繁更新或查询其中的个别字段,通常建议使用哈希表来存储 Session;而在 Session 数据较为简单、不涉及局部更新的情况下,使用字符串存储也是可行的选择。
- 存储数据简单(不涉及局部更新):使用 String 类型存储 Session,这样做的优缺点如下:
优点:
# 有序集合底层是如何实现的?
有序列表在 Redis 7 之前底层是使用 ziplist(压缩列表)+ skiplist(跳跃表),其中:
- 当数据列表元素个数要小于 128 个,并且所有元素成员的长度都必须小于 64 字节时,会使用压缩列表来存储。
- 否则,则使用跳跃表 skiplist 来存储。
但是,到了 Redis 7 之后,就开始使用紧凑列表 listpack 替代了压缩列表 ziplist 来实现了。
所以说:
- Redis 7 之前(不含 Redis 7):有序列表使用的是 ziplist(压缩列表)+ skiplist(跳跃表)实现的。
- Redis 7 及之后:有序列表使用的是 listpack(紧凑列表)+ skiplist(跳跃表)实现的。
# 什么是跳表?为什么要用跳表?
跳跃表 SkipList,也称之为跳表,是一种数据结构,用于在有序元素的集合中进行高效的查找操作。它通过添加多层链表的方式,提供了一种以空间换时间的方式来加速查找。
跳跃表由一个带有多层节点的链表组成,每一层都是原始链表的一个子集。最底层是一个完整的有序链表,包含所有元素。每个更高层级都是下层级的子集,通过添加额外的指针来跳过一些元素。这些额外的指针称为“跳跃指针”,它们允许快速访问更远的节点,从而减少了查找所需的比较次数。
跳跃表的平均查找时间复杂度为 O(log n),其中 n 是元素的数量,这使得它比普通的有序链表具有更快的查找性能,并且与平衡二叉搜索树(如红黑树)相比,实现起来更为简单。
简单的跳跃表如下图所示:
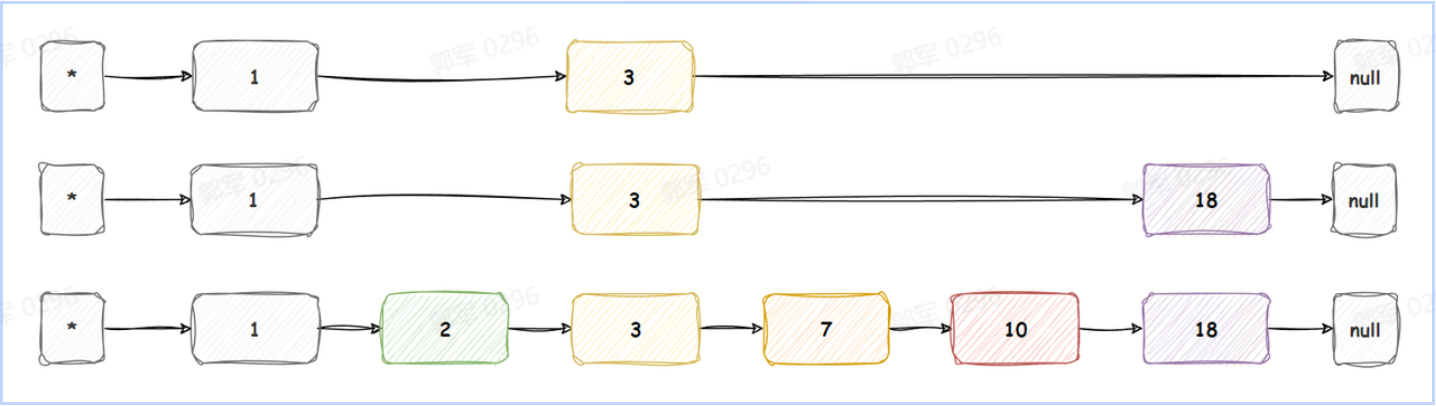
所以说,之所以使用跳表的原因是因为它可以提高有序列表的查询速度,查询性能从链表 O(n) 复杂度提升到了 O(log n) 时间复杂度,是一种以空间换时间的解决方案。
# 说一下跳表的查询流程?
跳表的查询流程如下:
- 起始搜索:查询操作从跳表的顶层开始,跳表的顶层包含一个或多个节点,从最顶层的头节点开始,将当前节点设为头节点。
- 检查下一个节点:检查当前节点的下一个节点,如果节点的分值小于目标分值,则右移检查下一个节点,然后重复此步骤,直到找到一个大于目标分值的节点,或为最后一个节点。
- 逐层下探:如果当前下一个节点的值大于目标分值,或为最后一个节点,则将当前指针向下一层级进行搜索,重复上述步骤。
- 终止并返回:在查找的过程中,如果找到了和目标分值相同的值,或者遍历完所有层级仍然未找到对应节点,则说明要查找的元素不存在于跳表中,则终止查找并返回查询到的内容或 NULL 值。
例如,以下跳跃表,查询分值为 18 的元素,查询流程如下:
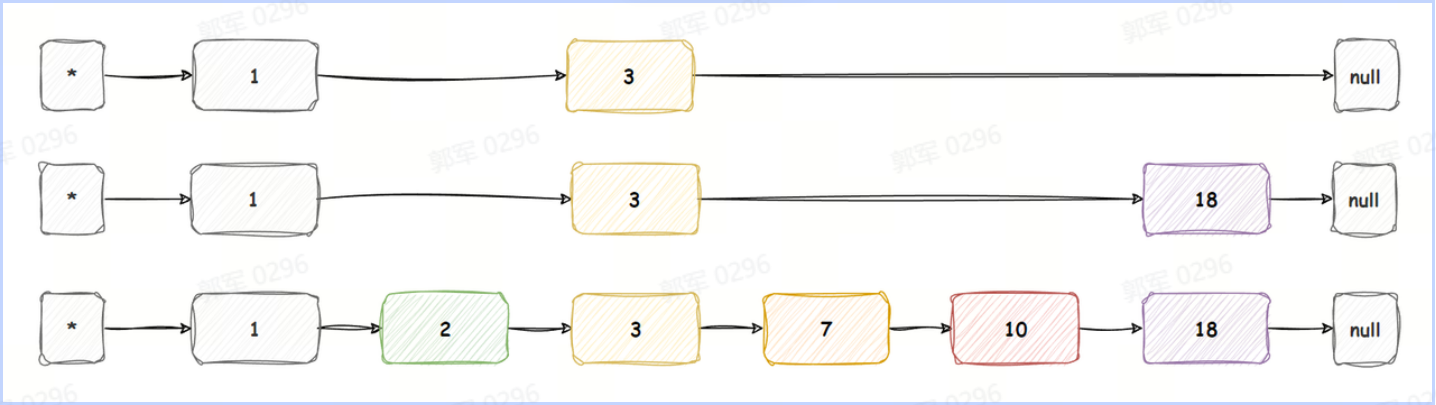
从最顶层开始查询,查询流程如下图所示:
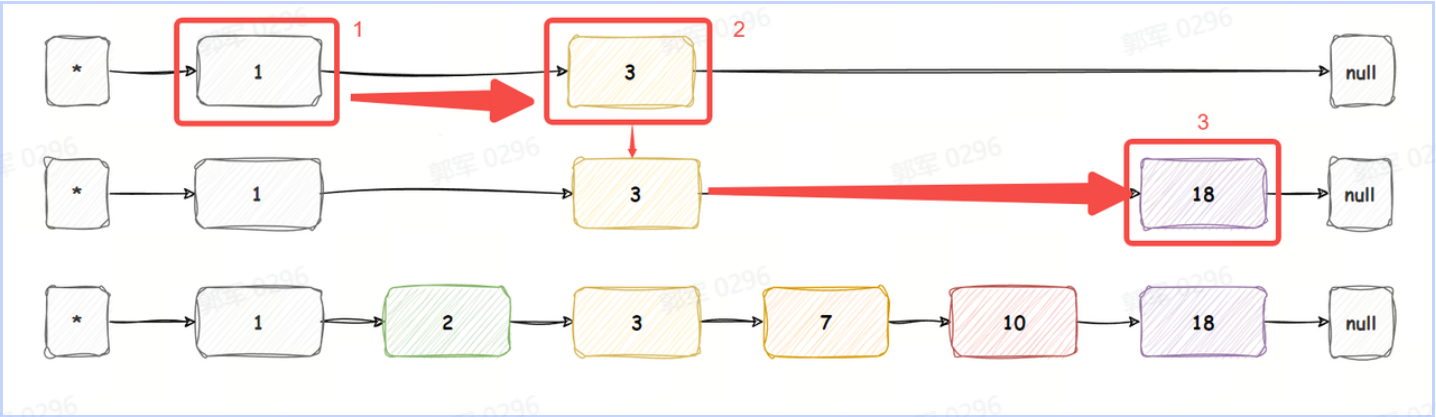
经过 3 次就找到了该节点。
PS:如果从最上层找到最下层,无匹配的节点就返回 null。
# 说一下跳表的添加流程?为什么要有“随机层数”这个概念?
要搞懂跳跃表的添加流程,首先要搞懂下面的前置知识。 前置知识:节点随机层数
所谓的随机层数指的是每次添加节点之前,会先生成当前节点的随机层数,根据生成的随机层数来决定将当前节点存在几层链表中。 为什么要这样设计呢? 这样设计的目的是为了保证 Redis 的执行效率,如果使用固定规律的跳表,为了维护固定的规律,所以在添加和删除节点时,跳表的整体变动非常大,效率也非常低。而使用随机层数,在添加和删除时,其他节点无需改动,因此效率要比固定规律的跳表性能高很多,所以 Redis 采用了节点随机层数。
# 使用Redis如何实现分布式锁?
首先来说 Redis 作为一个独立的三方系统,其天生的优势就是可以作为一个分布式系统来使用,因此使用 Redis 实现的锁都是分布式锁,如下所示:
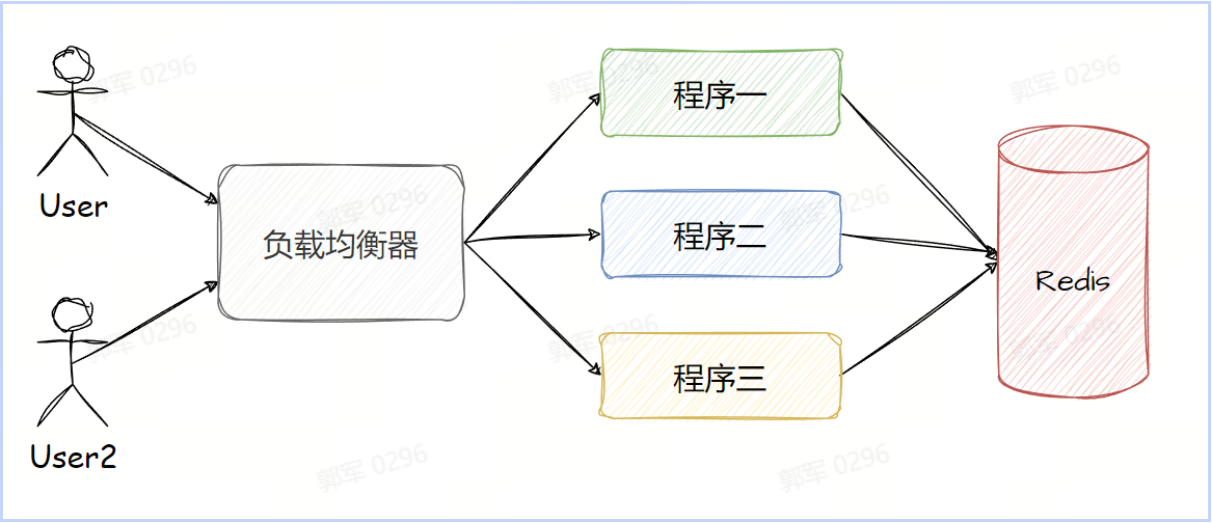
实现分布式锁 使用 Redis 实现分布式锁可以通过 setnx(set if not exists)命令实现,当我们使用 setnx 创建键值成功时,则表明加锁成功,否则既代码加锁失败,实现示例如下:
127.0.0.1:6379> setnx lock true (integer) 1 #创建锁成功 #逻辑业务处理...当我们重复加锁时,只有第一次会加(分布式)锁成功,执行结果如下:
127.0.0.1:6379> setnx lock true # 第一次加锁 (integer) 1 127.0.0.1:6379> setnx lock true # 第二次加锁 (integer) 0从上述命令中可以看出,我们可以使用执行的结果是否为 1 来判断加锁是否成功。
释放分布式锁
127.0.0.1:6379> del lock (integer) 1 #释放锁然而,如果使用 setnx lock true 实现分布式锁会存在死锁问题,以为 setnx 如未设置过期时间,锁忘记删了或加锁线程宕机都会导致死锁,也就是分布式锁一直被占用的情况。
解决死锁问题 死锁问题可以通过设置超时时间来解决,如果超过了超时时间,分布锁会自动释放,这样就不会存在死锁问题了。也就是 setnx 和 expire 配合使用,在 Redis 2.6.12 版本之后,新增了一个强大的功能,我们可以使用一个原子操作也就是一条命令来执行 setnx 和 expire 操作了,实现示例如下:
127.0.0.1:6379> set lock true ex 30 nx OK #创建锁成功 127.0.0.1:6379> set lock true ex 30 nx (nil) #在锁被占用的时候,企图获取锁失败其中 ex 为设置超时时间, nx 为元素非空判断,用来判断是否能正常使用锁的。 因此,我们在 Redis 中实现分布式锁最直接的方案就是使用 set key value ex timeout nx 的方式来实现。
# 有序集合在日常工作中的使用场景有哪些?
有序集合在工作中的应用场景有很多,例如以下这些常见的使用场景:
- 排行榜:可以将用户的得分作为有序集合的分值,用户的 ID 作为成员,通过有序集合的排名功能可以得到用户的排名信息。当然也可以是文章的热度、商品的热度等排行榜,如下所示:
zadd hot 100 aid_1 99 aid_2 95 aid_3 90 aid_4- 用户关注集合:可以将用户的关注数作为有序集合的分值,用户 ID 作为成员,通过分值的排序可以得到关注数最多的用户。当然也可以把用户的关注时间戳作为分值,如下所示:
zadd user_1_friends 1704179221 zhangsan 1704179222 lisi- 商品价格排序:可以将商品的价格作为有序集合的分值,商品 ID 作为成员,通过有序集合的排序功能可以得到价格从高到低的商品列表。
- 时间轴(timeline):可以将事件的时间戳作为有序集合的分值,事件内容作为成员,通过有序集合的排序功能可以得到按时间顺序排列的事件内容。例如某某事件最新进展(每隔一段时间,例如 60s 更新一下时间轴事件)。
# 使用Redis实现分布式锁存在什么问题?如何解决这些问题?
默认情况下,如果使用 setnx lock true 实现分布式锁会存在以下问题:
- 死锁问题:setnx 如未设置过期时间,锁忘记删了或加锁线程宕机都会导致死锁,也就是分布式锁一直被占用的情况。
- 锁误删问题:setnx 设置了超时时间,但因为执行时间太长,所以在超时时间之内锁已经被自动释放了,但线程不知道,因此在线程执行结束之后,会把其他线程的锁误删的问题。
- 不可重入问题:也就是说同一线程在已经获取了某个锁的情况下,如果再次请求获取该锁,则请求会失败(因为只有在第一次能加锁成功)。也就是说,一个线程不能对自己已持有的锁进行重复锁定。
- 无法自动续期:线程在持有锁期间,任务未能执行完成,锁可能会因为超时而自动释放。SETNX 无法自动根据任务的执行情况,设置新的超时实现,以延长锁的时间。
而这些问题的解决方案也是不同的。
① 解决死锁问题 死锁问题可以通过设置超时时间来解决,如果超过了超时时间,分布锁会自动释放,这样就不会存在死锁问题了。也就是 setnx 和 expire 配合使用,在 Redis 2.6.12 版本之后,新增了一个强大的功能,我们可以使用一个原子操作也就是一条命令来执行 setnx 和 expire 操作了,实现示例如下:
127.0.0.1:6379> set lock true ex 30 nx OK #创建锁成功 127.0.0.1:6379> set lock true ex 30 nx (nil) #在锁被占用的时候,企图获取锁失败其中 ex 为设置超时时间, nx 为元素非空判断,用来判断是否能正常使用锁的。
② 解决锁误删问题
锁误删可以通过将锁标识存储到 Redis 中来解决,删除之前先判断锁归属(也就是将线程 id 存储到分布式的 value 值内,删除之前先判断锁 value 值是否等于当前线程 id),如果属于你的锁再删除,否则不删除就可以,这就解决了锁误删的问题。
但这样解决因为判断和删除是非原子操作,所以依旧有问题,这个问题可以通过编写 lua 脚本或使用 Redisson 框架来解决,因为他们两都能保证判断和删除的原子性。
Lua 脚本指的是使用 Lua 语言编写的一段可执行的程序代码。Lua 是一种轻量级、高效、可嵌入的脚本语言,广泛应用于各种领域,包括游戏开发、嵌入式应用、脚本扩展等。 在 Redis 中,通过使用内置的 Lua 解释器,用户可以通过编写 Lua 脚本来执行一系列的操作。用户可以将一段 Lua 脚本传递给 Redis,并在 Redis 服务器端进行执行。Redis 提供了一系列的功能函数和 API 供 Lua 脚本使用,例如,命令操作、数据读写、事务处理等。
③ 通用解决方案
以上问题有一个通用的解决方案,那就是使用 Redisson 框架来实现 Redis 分布式锁,这样既可以解决死锁问题,也可以解决锁误删、不可重入和无法自动续期的问题了。
# 说一下什么是Redisson?使用它如何实现分布式锁?它实现的分布式锁有什么优点?
Redisson 是一个开源的用于操作 Redis 的 Java 框架。与 Jedis 和 Lettuce 等轻量级的 Redis 框架不同,它提供了更高级且功能丰富的 Redis 客户端。它提供了许多简化 Redis 操作的高级 API,并支持分布式对象、分布式锁、分布式集合等特性。
Redisson 优点
- Redisson 可以设置分布式锁的过期时间,从而避免锁一直被占用而导致的死锁问题。
- Redisson 在为每个锁关联一个线程 ID 和重入次数(递增计数器)作为分布锁 value 的一部分存储在 Redis 中,这样就避免了锁误删和不可重入的问题。
- Redisson 还提供了自动续期的功能,通过定时任务(看门狗)定期延长锁的有效期,确保在业务未完成前,锁不会被其他线程获取。
Redisson 实现分布锁 ① 添加 Redisson 框架支持 如果是 Spring Boot 项目,直接添加 Redisson 为 Spring Boot 写的如下依赖:
<!-- Redisson --> <!-- https://mvnrepository.com/artifact/org.redisson/redisson-spring-boot-starter --> <dependency> <groupId>org.redisson</groupId> <artifactId>redisson-spring-boot-starter</artifactId> <version>3.25.2</version> <!-- 请根据实际情况使用最新版本 --> </dependency>其他项目,访问 https://mvnrepository.com/search?q=Redisson 获取具体依赖配置。
② 配置 RedissonClient 对象
将 RedissonClient 重写,存放到 IoC 容器,并且配置连接的 Redis 服务器信息。
import org.redisson.Redisson; import org.redisson.api.RedissonClient; import org.redisson.config.Config; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class RedissonConfig { @Bean public RedissonClient redissonClient() { Config config = new Config(); // 也可以将 redis 配置信息保存到配置文件 config.useSingleServer().setAddress("redis://127.0.0.1:6379"); return Redisson.create(config); } }③ 创建分布式锁
Redisson 分布式锁的操作和 Java 中的 ReentrantLock(可重入锁)的操作很像,都是先使用 tryLock 尝试获取(非公平)锁,最后再通过 unlock 释放锁,具体实现如下:
import org.redisson.api.RLock; import org.redisson.api.RedissonClient; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; import java.util.concurrent.TimeUnit; @RestController public class LockController { @Autowired private RedissonClient redissonClient; @GetMapping("/lock") public String lockResource() throws InterruptedException { String lockKey = "myLock"; // 获取 RLock 对象 RLock lock = redissonClient.getLock(lockKey); try { // 尝试获取锁(尝试加锁)(锁超时时间是 30 秒) boolean isLocked = lock.tryLock(30, TimeUnit.SECONDS); if (isLocked) { // 成功获取到锁 try { // 模拟业务处理 TimeUnit.SECONDS.sleep(5); return "成功获取锁,并执行业务代码"; } catch (InterruptedException e) { e.printStackTrace(); } finally { // 释放锁 lock.unlock(); } } else { // 获取锁失败 return "获取锁失败"; } } catch (InterruptedException e) { e.printStackTrace(); } return "获取锁成功"; } }# 说一下Redisson中的看门狗机制?
Redisson 看门狗(Watchdog)机制是一种用于延长分布式锁的有效期的机制。它通过定时续租锁的方式,防止持有锁的线程在执行操作时超过了锁的有效期而导致锁被自动释放。
看门狗(Watchdog)的执行过程大致如下:
- 获取锁并设置超时时间:当客户端通过 Redisson 尝试获取一个分布式锁时,会使用 Redis 命令将锁存入 Redis,并设置一个初始的有效时间(即超时时间)。
- 启动看门狗线程:如果开启了看门狗的功能(默认开启),在成功获取锁后,Redisson 会在客户端内部启动一个后台守护线程,也就是所谓的“看门狗”定时任务定时去执行并续期。
- 定时检查与续期:看门狗按照预设的时间间隔(默认为锁有效时间的三分之一)周期性地检查锁是否仍然被当前客户端持有。如果客户端仍然持有锁,看门狗会调用 Redis 的相关命令或者 Lua 脚本来延长锁的有效期,确保在业务处理期间锁不会因超时而失效。
- 循环监控和更新:这个过程会一直持续到客户端显式地释放锁,或者由于其他原因(例如客户端崩溃、网络中断等)导致无法继续执行看门狗任务为止。
- 终止看门狗任务:客户端在完成业务逻辑后,会主动调用解锁方法释放锁,此时 Redisson 不仅会解除对 Redis 中对应键的锁定状态,还会同步停止看门狗的任务。
通过看门狗机制,即使在长时间运行的业务场景下,也能有效地避免由于锁超时而导致的数据不一致或其他并发控制问题,提高了系统的稳定性和可靠性。
# 什么是RedLock吗?它有什么优缺点?推荐使用RedLock吗?为什么?
RedLock 是 Redis 分布式锁的一种实现方案,由 Redis 的作者 Salvatore Sanfilippo 提出。RedLock 算法旨在解决单个 Redis 实例作为分布式锁时可能出现的单点故障问题,通过在多个独立运行的 Redis 实例上同时获取锁的方式来提高锁服务的可用性和安全性。
RedLock 实现代码
在 Java 开发中,可以使用 Redisson 框架很方便的实现 RedLock,具体操作代码如下:
import org.redisson.Redisson; import org.redisson.api.RedisClient; import org.redisson.api.RedissonClient; import org.redisson.config.Config; import org.redisson.redisson.RedissonRedLock; public class RedLockDemo { public static void main(String[] args) { // 创建 Redisson 客户端配置 Config config = new Config(); config.useClusterServers() .addNodeAddress("redis://127.0.0.1:6379", "redis://127.0.0.1:6380", "redis://127.0.0.1:6381"); // 假设有三个 Redis 节点 // 创建 Redisson 客户端实例 RedissonClient redissonClient = Redisson.create(config); // 创建 RedLock 对象 RedissonRedLock redLock = redissonClient.getRedLock("resource"); try { // 尝试获取分布式锁,最多尝试 5 秒获取锁,并且锁的有效期为 5000 毫秒 boolean lockAcquired = redLock.tryLock(5, 5000, TimeUnit.MILLISECONDS); if (lockAcquired) { // 加锁成功,执行业务代码... } else { System.out.println("Failed to acquire the lock!"); } } catch (InterruptedException e) { Thread.currentThread().interrupt(); System.err.println("Interrupted while acquiring the lock"); } finally { // 无论是否成功获取到锁,在业务逻辑结束后都要释放锁 if (redLock.isLocked()) { redLock.unlock(); } // 关闭 Redisson 客户端连接 redissonClient.shutdown(); } } }优缺点分析
优点分析
RedLock 是对集群的每个节点进行加锁,如果大多数节点(N/2+1)加锁成功,则才会认为加锁成功。
这样即使集群中有某个节点挂掉了,因为大部分集群节点都加锁成功了,所以分布式锁还是可以继续使用的。
缺点分析
RedLock 主要存在以下两个问题:
- 性能问题:RedLock 要等待大多数节点返回之后,才能加锁成功,而这个过程中可能会因为网络问题,或节点超时的问题,影响加锁的性能。
- 并发安全性问题:当客户端加锁时,如果遇到 GC 可能会导致加锁失效,但 GC 后误认为加锁成功的安全事故,例如以下流程:
- 客户端 A 请求 3 个节点进行加锁。
- 在节点回复处理之前,客户端 A 进入 GC 阶段(存在 STW,全局停顿)。
- 之后因为加锁时间的原因,锁已经失效了。
- 客户端 B 请求加锁(和客户端 A 是同一把锁),加锁成功。
- 客户端 A GC 完成,继续处理前面节点的消息,误以为加锁成功。
- 此时客户端 B 和客户端 A 同时加锁成功,出现并发安全性问题。
推荐使用 RedLock 吗?为什么?
不推荐使用 RedLock,因为 RedLock 存在的问题争议较大(性能和并发问题),且没有完美的解决方案,所以 Redisson 中已经废弃了 RedLock,这一点在 Redisson 官方文档中能找到
RedLock 替代方案
虽然 Redisson 中已经废弃了 RedLock,但是你可以直接使用 Redisson 中的普通的加锁即可,因为它的普通锁会基于 wait 机制,等待锁将信息同步到从节点,从而保证数据一致性的,虽然不能完全避免数据一致性问题,但也能最大限度的保证数据的一致性。
# 什么是布隆过滤器?它有什么特点?说一下它的底层实现原理?
布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构,用于判断一个元素是否在一个集合中。它基于位数组和多个哈希函数的原理,可以高效地进行元素的查询,而且占用的空间相对较小,如下图所示:
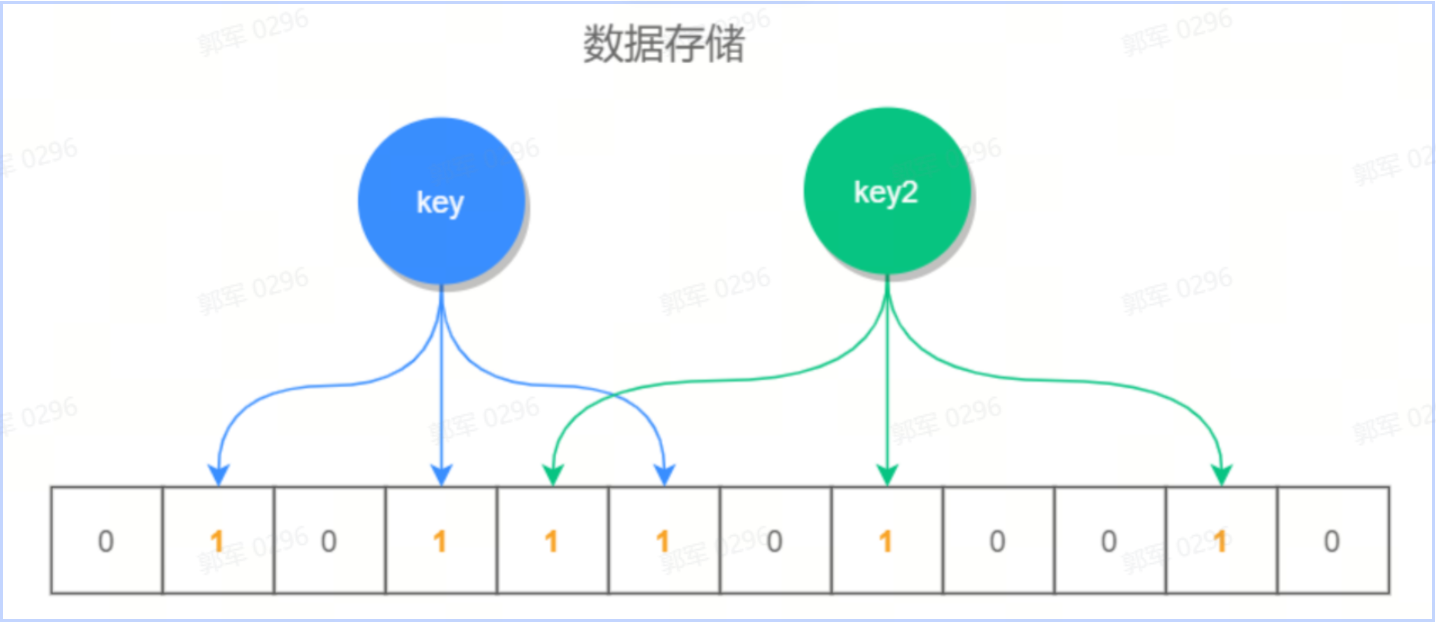
根据 key 值计算出它的存储位置,然后将此位置标识全部标识为 1(未存放数据的位置全部为 0),查询时也是查询对应的位置是否全部为 1,如果全部为 1,则说明数据是可能存在的,否则一定不存在。
布隆过滤器特点
也就是说,如果布隆过滤器说一个元素不在集合中,那么它一定不在这个集合中;但如果它说一个元素在集合中,则有可能是不存在的(存在误差)。
底层实现原理
布隆过滤器的具体执行步骤如下:
- 在 Redis 中创建一个位数组,用于存储布隆过滤器的位向量,每个位置的值设置为 0。
- 添加元素到布隆过滤器时,对元素进行多次哈希计算,并将对应的位数组位置设置为 1。
- 查询元素是否存在时,对元素进行多次哈希计算,并检查对应的位数组位置是否都为 1,都为 1 表示可能存在,其中有一个为 0 则一定不存在。
也就是说布隆过滤器是通过一个位数组,加上多组哈希算法来实现的,每次添加一个 key 的时候,通过多组哈希算法计算得到位数组的保存位置,然后将其设置为 1,查询时候也是如此,在查找中只要有一个位元素为 0,则表示当前 key 是不存在的,如果都为 1,则表示可能存在。
# 在Redis中如何实现布隆过滤器?
在 Redis 中不能直接使用布隆过滤器,但我们可以通过 Redis 4.0 版本之后提供的 modules (扩展模块) 的方式引入,它的实现步骤如下。
① 打包RedisBloom插件
git clone https://github.com/RedisLabsModules/redisbloom.git cd redisbloom make # 编译redisbloom
编译正常执行完,会在根目录生成一个 redisbloom.so 文件。
② 启用RedisBloom插件
重新启动 Redis 服务,并指定启动 RedisBloom 插件,具体命令如下:
redis-server redis.conf --loadmodule ./src/modules/RedisBloom-master/redisbloom.so
③ 创建布隆过滤器
创建一个布隆过滤器,并设置期望插入的元素数量和误差率,在 Redis 客户端中输入以下命令:
BF.RESERVE my_bloom_filter 0.01 100000
④ 添加元素到布隆过滤器
在 Redis 客户端中输入以下命令:
BF.ADD my_bloom_filter leige
⑤ 检查元素是否存在
在 Redis 客户端中输入以下命令:
BF.EXISTS my_bloom_filter leige
# 除了Redis还有其他实现布隆过滤器的手段吗?它们和Redis有什么区别?
除了 Redis 可以实现布隆过滤器之外,我们还可以使用以下方法实现布隆过滤器:
- 使用 Google Guava 实现布隆过滤器。
- 使用 Hutool 框架实现布隆过滤器。
但是以上方式实现的布隆过滤器为单机版的布隆过滤器,而 Redis 实现的布隆过滤器为分布式布隆过滤器。
# Redis中存储的数据会丢失吗?为什么?
Redis 存储的数据不会丢失,保证数据不丢失的手段主要有以下两个:
- 持久化:持久化是指将内存中的数据保存到硬盘上,以防止在服务器重启、宕机等意外情况下导致数据丢失。由于 Redis 是一个基于内存的数据库系统,默认情况下所有的数据都存储在内存中,这意味着一旦服务进程终止或硬件故障,内存中的所有数据都将消失。而 Redis 提供了 3 种持久化的手段,以保证 Redis 可以将内存中的数据保存到磁盘上,这样无论是服务器重启,还是宕机、掉电等问题,Redis 的数据都不会丢失。
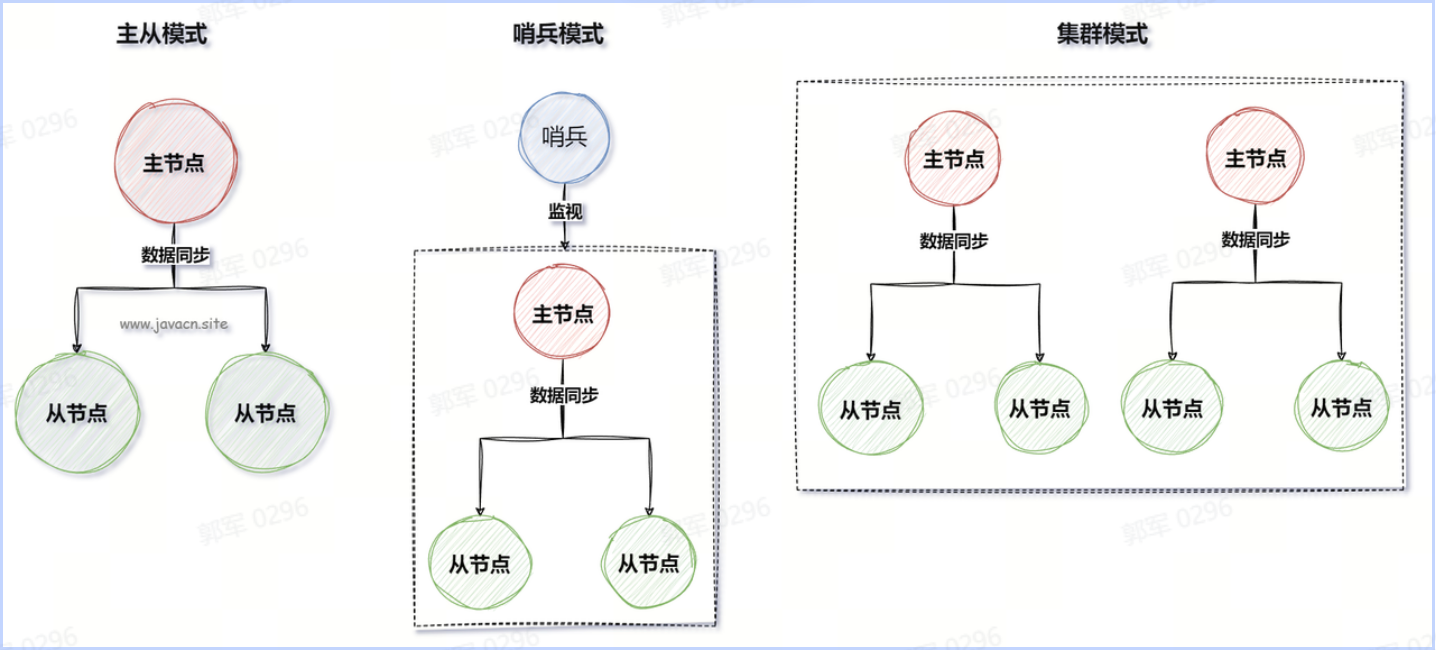
- 多机部署:多机部署是指在多个独立的服务器或虚拟机上部署和运行 Redis 服务实例,以实现数据冗余、高可用性、可扩展性和负载均衡等目标。Redis 多机运行部署的实现总共有三种:主从模式、哨兵模式和集群模式。
# Redis会怎么处理过期之后的键值对?它为什么要这样设计?
Redis 中过期的键值对不会立即删除,而是使用以下手段来删除过期键的:
- 惰性删除(Lazy Expire):Redis 不会主动地、周期性地检查和删除所有过期的键。惰性删除是指在 Redis 访问某个键值时,才会检查该键是否已经过期,如果已过期,则返回 NULL,并同时删除它。
- 定期删除(Periodic Expire):每隔一段时间检查一次数据库,随机删除一些过期键。定期删除在 redis.conf 配置文件中配置,如下图所示:
 hz 等于 10 表示每秒钟删除 10 次,也就是每 100 毫秒执行一次定期删除。
hz 等于 10 表示每秒钟删除 10 次,也就是每 100 毫秒执行一次定期删除。
之所以要采用这两种方式来删除是为了保证清除过期数据,不影响 Redis 整体的执行效率。
# 什么是缓存雪崩?如何解决缓存雪崩?
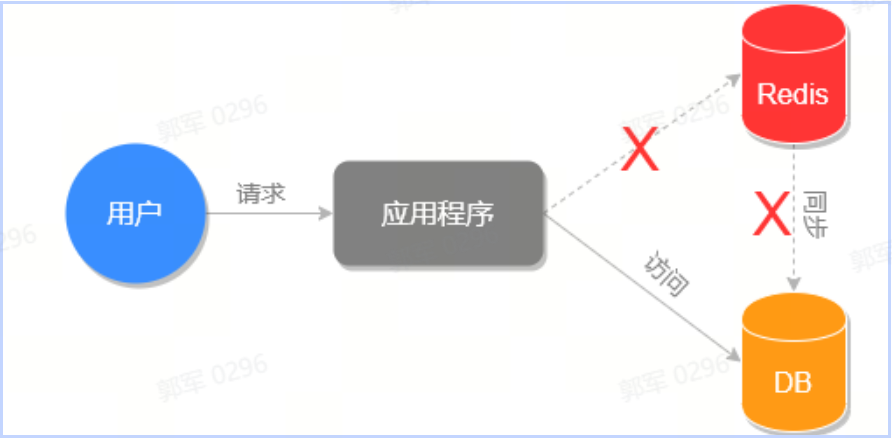
缓存雪崩是指在短时间内,有大量缓存同时过期,导致大量的请求直接查询数据库,从而对数据库造成了巨大的压力,严重情况下可能会导致数据库宕机的情况叫做缓存雪崩。
我们先来看下正常情况下和缓存雪崩时程序的执行流程图,正常情况下系统的执行流程如下图所示:

缓存雪崩的执行流程,如下图所示:
以上对比图可以看出缓存雪崩对系统造成的影响,导致缓存雪崩的主要原因有以下几个:
- 缓存过期时间设置不合理:当大量缓存数据在同一时间失效时,会导致大量请求直接打到数据库或者后端服务。
- 缓存服务器故障:如果缓存服务器发生故障,无法提供缓存服务,那么所有请求将直接访问数据库或者后端服务。
- 缓存数据的热点分布不均匀:如果某些热门数据集中在一部分缓存节点上,当这些节点发生故障或者数据失效时,会导致请求直接打到数据库或者后端服务。
如何解决缓存雪崩问题?
缓存雪崩的常见解决方案有以下几个:
- 随机生成缓存过期时间:随机生成缓存过期时间,可以避免缓存同时过期,从而避免雪崩问题的发生。
// 缓存原本的失效时间 int exTime = 10 * 60; // 随机数生成类 Random random = new Random(); // 缓存设置 jedis.setex(cacheKey, exTime+random.nextInt(1000) , value);使用多级缓存:可以使用多级缓存架构,将热门数据同时缓存在多个缓存节点上,避免单一节点故障导致请求直接访问数据库或者后端服务,例如可以设计二级缓存(分布式缓存+本地缓存),如下图所示:
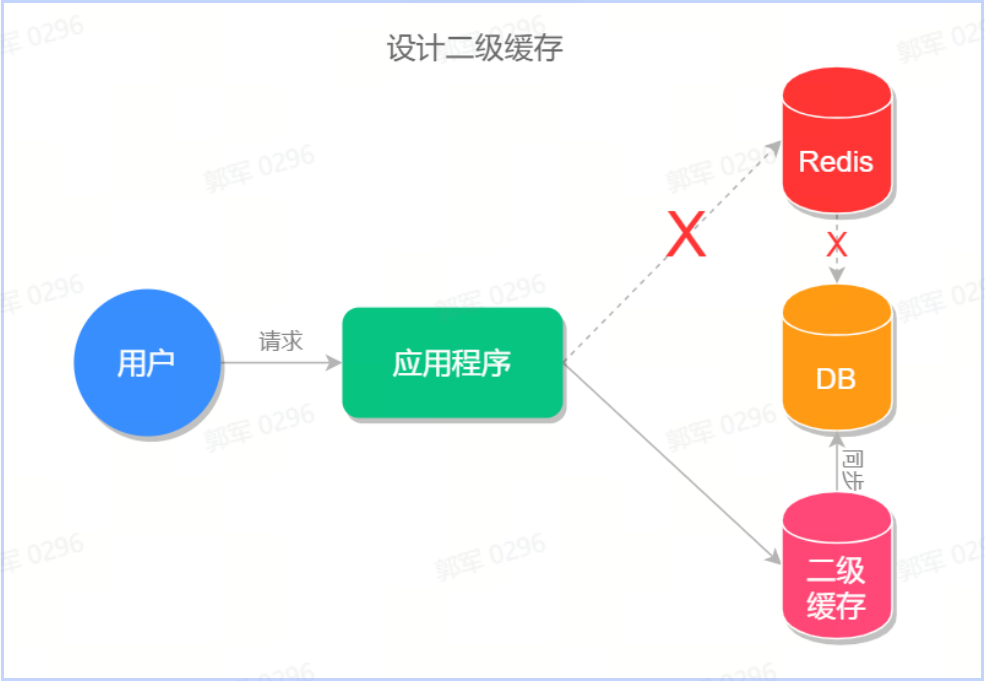
缓存过期前预加载:在缓存即将过期之前,提前异步加载缓存,避免在缓存失效时大量请求直接打到数据库或者后端服务。
开启限流或降级功能:当缓存发生雪崩时,采用限流或降级的机制来减少服务器的压力,保证系统的可用性。
实时监控和预警:通过监控缓存的状态和命中率,及时发现缓存问题,预警系统管理员或运维人员。
# 什么是缓存穿透?如何解决缓存穿透?
缓存穿透是指查询数据库和缓存都无数据,因为数据库查询无数据,出于容错考虑,不会将结果保存到缓存中,因此每次请求都会去查询数据库,从而给数据库带来了额外的压力,降低了系统性能的情况就叫做缓存穿透。
也就是说缓存穿透是因为数据库查询无数据,出于容错考虑,不会将结果保存到缓存中,因此每次请求都会去查询数据库,这种情况就叫做缓存穿透。
缓存穿透执行流程如下图所示:
 其中红色路径表示缓存穿透的执行路径,可以看出缓存穿透会给数据库造成很大的压力。
其中红色路径表示缓存穿透的执行路径,可以看出缓存穿透会给数据库造成很大的压力。解决缓存穿透
缓存穿透的常见解决方案有以下几个:
- 缓存空对象:对于查询结果为 null 或不存在的数据,也可以将它们以特殊值(如"NULL"、特定标识符)进行缓存,并设置较短的过期时间。这样,短时间内相同的查询请求就可以直接从缓存中获得响应,避免了对数据库的直接查询。
- 布隆过滤器(Bloom Filter):在请求到达缓存之前,先通过布隆过滤器判断数据可能存在还是一定不存在。对于确定不存在的数据,可以直接返回;可能存在则继续查询缓存和数据库。布隆过滤器是一种空间效率极高的概率型数据结构,它会给出“可能存在”或“肯定不存在”的答案。

- 开启限流功能:当发现大量连续未命中的请求时,可以采用限流策略限制同一时间段内向数据库发送的查询请求数量,减轻数据库压力。
# 什么是缓存击穿?如何解决缓存击穿?
缓存击穿指的是某个热点缓存,在某一时刻恰好失效了,然后此时刚好有大量的并发请求,此时这些请求将会给数据库造成巨大的压力,这种情况就叫做缓存击穿。
缓存击穿的执行流程如下图所示:

缓存击穿的主要原因是热点数据在缓存中失效或被淘汰,并发请求同时访问该数据,导致缓存无法命中。
解决缓存击穿
缓存击穿的常见解决方案有以下几个:
- 设置永不过期:对于某些热点缓存,我们可以设置永不过期,这样就能保证缓存的稳定性,但需要注意在数据更改之后,要及时更新此热点缓存,不然就会造成查询结果的误差。
- 缓存过期前预加载:在缓存即将过期之前,提前异步加载缓存,避免在缓存失效时大量请求直接打到数据库或者后端服务。
- 使用多级缓存:可以使用多级缓存架构,将热门数据同时缓存在多个缓存节点上,避免单一节点故障导致请求直接访问数据库或者后端服务,例如可以设计多级缓存,也就是使用分布式缓存(Redis)+本地缓存(Caffeine/Guava Cache),如下图所示:
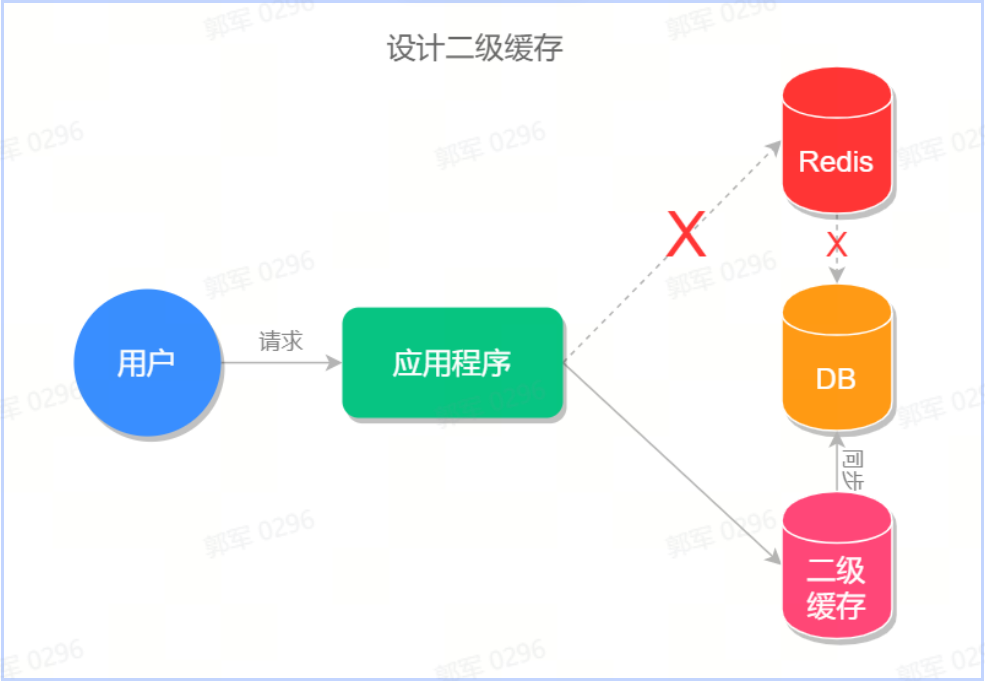
- 开启限流或降级功能:当缓存发生雪崩时,采用限流或降级的机制来减少服务器的压力,保证系统的可用性。
# 什么是缓存预热?如何实现缓存预热?
缓存预热指的是在系统启动、高峰期来临之前或数据变更之后,提前将热门或需要经常访问的数据加载到缓存中,以提高系统的响应性能和缓存命中率。通过缓存预热,可以避免在实际请求到来时出现缓存穿透或缓存击穿的情况,减少对后端存储的直接访问。
实现步骤 实现缓存预热的一般步骤如下:
- 确定热门数据:首先需要确定哪些数据是热门或需要经常访问的数据。可以通过系统日志、业务需求、数据统计分析等方式进行判断和评估。
- 加载数据到缓存:在系统启动、高峰期来临之前或数据变更之后,提前将热门数据加载到缓存中。可以通过定时任务、异步加载、批量加载等方式来实现数据加载。
- 设置适当的过期时间:根据业务需求和数据的访问频率,设置适当的缓存过期时间。过期时间可以根据不同的数据进行灵活调整,以保证缓存数据的有效性。
- 监控和维护:在缓存预热完成后,需要进行监控和维护。可以通过监控缓存命中率、缓存失效率等指标来评估缓存的效果,及时进行调优和维护。
缓存预热实现
缓存预热的方法有很多种,下面是一些常见的实现方式:
- 手动初始化:在应用程序启动阶段或者服务初始化的时候,通过编写代码主动地从数据库加载热点数据,并将其放入缓存(如 Redis)。
// 初始化阶段加载热点数据 public void warmUpCache() { List<HotData> hotDatas = loadHotDataFromDatabase(); for (HotData data : hotDatas) { String key = buildKey(data.getId()); redisTemplate.opsForValue().set(key, data, expirationTime, TimeUnit.MINUTES); } }- 定时任务:使用定时任务定期刷新或加载数据到缓存,可以是固定时间间隔,也可以是在数据变更后触发。
- 事件驱动:当有新的数据添加到数据库时,触发一个事件来通知缓存系统加载新数据。
- 使用框架:某些框架或中间件提供了缓存预热功能的支持。例如,在 Spring Boot 项目中,可以通过实现 CommandLineRunner 或 ApplicationRunner 接口,在应用启动后自动加载数据到缓存。
import org.springframework.boot.ApplicationArguments; import org.springframework.boot.ApplicationRunner; import org.springframework.boot.CommandLineRunner; import org.springframework.stereotype.Component; @Component public class MyRunner implements CommandLineRunner, ApplicationRunner { @Override public void run(String... args) throws Exception { System.out.println("This is CommandLineRunner"); // 实现自定义操作 } @Override public void run(ApplicationArguments args) throws Exception { System.out.println("This is ApplicationRunner"); // 实现自定义操作 } }上述示例中,MyRunner 类同时实现了 CommandLineRunner 和 ApplicationRunner 接口,可以通过重写的两个 run 方法分别执行不同的操作。
PS:CommandLineRunner 执行时机早于 ApplicationRunner 接口,但 CommandLineRunner 适用于简单的命令行参数场景,例如在命令行中指定一些参数来配置应用程序行为。ApplicationRunner 适用于更复杂的场景,可以通过键值对的方式传递参数,以及获取更多关于应用程序参数的元数据。
# 六. Spring
# 在SpringBoot中如何实现缓存预热?
SpringBoot 缓存预热是指在 Spring Boot 项目启动时,预先将数据加载到缓存系统(如 Redis)中的一种机制。
实现方案概述
在 Spring Boot 启动之后,可以通过以下手段实现缓存预热:
- 使用启动监听事件实现缓存预热。
- 使用 @PostConstruct 注解实现缓存预热。
- 使用 CommandLineRunner 或 ApplicationRunner 实现缓存预热。
- 通过实现 InitializingBean 接口,并重写 afterPropertiesSet 方法实现缓存预热。
具体实现方案
① 启动监听事件 可以使用 ApplicationListener 监听 ContextRefreshedEvent 或 ApplicationReadyEvent 等应用上下文初始化完成事件,在这些事件触发后执行数据加载到缓存的操作,具体实现如下:
@Component public class CacheWarmer implements ApplicationListener<ContextRefreshedEvent> { @Override public void onApplicationEvent(ContextRefreshedEvent event) { // 执行缓存预热业务... cacheManager.put("key", dataList); } }或监听 ApplicationReadyEvent 事件,如下代码所示:
@Component public class CacheWarmer implements ApplicationListener<ApplicationReadyEvent> { @Override public void onApplicationEvent(ApplicationReadyEvent event) { // 执行缓存预热业务... cacheManager.put("key", dataList); } }ContextRefreshedEvent VS ApplicationReadyEvent
ContextRefreshedEvent 和 ApplicationReadyEvent 发生的时间和应用场景略有不同:
- ContextRefreshedEvent(上下文刷新事件):当 ApplicationContext 容器初始化或刷新时触发该事件,这个事件在 Bean 的初始化方法之前触发,意味着在该事件完成之前,Bean 已经完成实例化和配置了。
- ApplicationReadyEvent(应用就绪事件):当 Spring Boot 应用完全启动并准备接受请求时触发该事件。在该事件触发时,Spring Boot 应用的所有初始化工作已完成,包括 Bean 的实例化、依赖注入等。这个事件通常用于在应用启动完成后执行一些特定的操作,比如启动定时任务、加载缓存数据等。
所以说,ContextRefreshedEvent 事件被触发时,Spring容器中的 Bean 已经准备好了,但应用可能还没有完全启动,尚未准备好接收请求。而 ApplicationReadyEvent 事件则表示应用已经完全启动并准备好处理请求。
② @PostConstruct 在需要进行缓存预热的类上添加 @Component 注解,并在其方法中添加 @PostConstruct 注解和缓存预热的业务逻辑,具体实现代码如下:
@Component public class CachePreloader { @Autowired private YourCacheManager cacheManager; @PostConstruct public void preloadCache() { // 执行缓存预热业务... cacheManager.put("key", dataList); } }③ CommandLineRunner或ApplicationRunner
CommandLineRunner 和 ApplicationRunner 都是 Spring Boot 应用程序启动后要执行的接口,它们都允许我们在应用启动后执行一些自定义的初始化逻辑,例如缓存预热。
CommandLineRunner 实现示例如下:
@Component public class MyCommandLineRunner implements CommandLineRunner { @Override public void run(String... args) throws Exception { // 执行缓存预热业务... cacheManager.put("key", dataList); } }ApplicationRunner 实现示例如下:
@Component public class MyApplicationRunner implements ApplicationRunner { @Override public void run(ApplicationArguments args) throws Exception { // 执行缓存预热业务... cacheManager.put("key", dataList); } }CommandLineRunner 和 ApplicationRunner 区别如下:
方法签名不同:
- CommandLineRunner 接口有一个 run(String... args) 方法,它接收命令行参数作为可变长度字符串数组。
- ApplicationRunner 接口则提供了一个 run(ApplicationArguments args) 方法,它接收一个 ApplicationArguments 对象作为参数,这个对象提供了对传入的所有命令行参数(包括选项和非选项参数)的访问。
参数解析方式不同:
- CommandLineRunner 接口更简单直接,适合处理简单的命令行参数。
- ApplicationRunner 接口提供了一种更强大的参数解析能力,可以通过 ApplicationArguments 获取详细的参数信息,比如获取选项参数及其值、非选项参数列表以及查询是否存在特定参数等。
使用场景不同:
- 当只需要处理一组简单的命令行参数时,可以使用 CommandLineRunner。
- 对于需要精细控制和解析命令行参数的复杂场景,推荐使用 ApplicationRunner。
④ 实现InitializingBean接口
实现 InitializingBean 接口并重写 afterPropertiesSet 方法,可以在 Spring Bean 初始化完成后执行缓存预热,具体实现代码如下:
@Component public class CachePreloader implements InitializingBean { @Autowired private YourCacheManager cacheManager; @Override public void afterPropertiesSet() throws Exception { // 执行缓存预热业务... cacheManager.put("key", dataList); } }# 什么是IoC?它解决了什么问题?为什么要使用它?
IoC 和 AOP 是 Spring 中最核心的两个概念。
IoC 是 Inversion of Control 的缩写,翻译成中文是“控制反转”的意思,它不是一个具体的技术,而是一个实现对象解耦的思想。
控制反转的意思是将要使用的对象生命周期的控制权进行反转,传统开发是当前类控制依赖对象的生命周期的,现在交给其他人(Spring),这就是控制(权)反转。
也就是说 IoC 解决了将对象的生命周期控制权从原来的类型,反转给 IoC 框架了,这样程序中就无需在关注对象的生命周期了,这些都由 IoC 框架来控制了。
为什么要使用 IoC?
使用 IoC 主要是因为 IoC 有以下几个优点:
- 解耦和松散耦合:IoC 通过将组件之间的依赖关系从代码中分离出来,实现了松散耦合。这意味着组件不需要直接了解它们之间的详细实现,从而提高了代码的可维护性和可重用性。
- 代码简洁性:IoC 使你的代码更加专注于业务逻辑,而不需要过多关注依赖的创建和管理。这使得代码更加清晰、简洁和易于理解。
- 生命周期管理:IoC 容器可以管理组件的生命周期,确保它们在合适的时间进行创建、初始化和销毁。
- 可重用性:由于依赖关系由容器管理,可以更容易地将组件在不同的应用程序中重用。
- AOP 实现基础:IoC 是实现 AOP(面向切面编程)的基础,允许你将横切关注点(如日志、安全性)与核心业务逻辑分离。
# IoC和DI有什么关系?IoC的实现除了DI之外,还有其他实现方式吗?
DI 是 Dependency Injection 的缩写,翻译成中文是“依赖注入”的意思。依赖注入不是一种设计实现,而是一种具体的技术,它是在 IoC 容器运行期间,动态地将某个依赖对象注入到当前对象的技术就叫做 DI(依赖注入)。
比如 A 对象需要依赖 B 对象,那么在 A 运行时,动态的将依赖对象 B 注入到当前类中,而非通过直接 new 的方式获取 B 对象的方式,就是依赖注入。
DI VS IoC
IoC 和 DI 虽然定义不同,但它们所做的事情都是一样的,都是用来实现对象解耦的,而二者又有所不同:IoC 是一种设计思想,而 DI 是一种具体的实现技术。
比如,磊哥今天心情比较好,想出去吃顿好的,那么“想吃顿好的”就是一种思想、就是 IoC。 但什么才是“好的(饭)”呢?海底捞还是韩式料理?具体吃什么是 DI。 因此“磊哥今天心情比较好,想出去吃顿好的”是一种思想、是 IoC;而吃什么,比如吃一顿海底捞而非韩式料理就是具体的实现、是 DI。
IoC 除了 DI 实现外,还有其他实现方式吗?
IoC 除了 DI 依赖注入之外,还可以通过依赖查找(Dependency Search)来实现。
在 Spring 框架中,依赖查找通过 ApplicationContext 接口的 getBean() 方法来实现,如下代码所示:
import org.springframework.context.ApplicationContext; import org.springframework.context.support.ClassPathXmlApplicationContext; public class App { public static void main(String[] args) { // 1.先得到 Spring 上下文对象 ApplicationContext context = new ClassPathXmlApplicationContext("spring-config.xml"); // 2.得到 Bean【依赖查找 -> IoC 的一种实现】 UserService userService = (UserService) context.getBean("user"); // 3.使用 Bean 对象(非必须) userService.sayHi(); } }# **BeanFactory和FactoryBean有什么区别? **
BeanFactory 和 FactoryBean 完全不同的两个接口,BeanFactory 是用来管理 Bean 对象的,而 FactoryBean 本质上一个 Bean,也归 BeanFactory 管理,但使用 FactoryBean 可以来创建普通的 Bean 对象和 AOP 代理对象,它们具体区别如下。
① BeanFactory BeanFactory 是 Spring 框架的核心接口之一,它是一个工厂模式的实现,负责管理 bean 的生命周期、创建和销毁等操作。BeanFactory 提供了各种方法来获取 bean,包括按名称获取、按类型获取等。
其中,ApplicationContext 就是 BeanFactory 的子类,咱们通常会使用 ApplicationContext 来获取某个 Bean:
 BeanFactory 使用示例:
BeanFactory 使用示例:// 创建BeanFactory容器 BeanFactory beanFactory = new XmlBeanFactory(new ClassPathResource("applicationContext.xml")); // 获取bean实例 YourBean yourBean = (YourBean) beanFactory.getBean("yourBeanName");BeanFactory 源代码如下:
public interface BeanFactory { // 对FactoryBean的转义定义,因为如果使用bean的名字检索FactoryBean得到的对象是工厂生成的对象, // 如果需要得到工厂本身,需要转义 String FACTORY_BEAN_PREFIX = "&"; // 根据bean的名字,获取在IOC容器中得到bean实例 Object getBean(String name) throws BeansException; // 根据bean的名字和Class类型来得到bean实例,增加了类型安全验证机制。 <T> T getBean(String name, @Nullable Class<T> requiredType) throws BeansException; Object getBean(String name, Object... args) throws BeansException; <T> T getBean(Class<T> requiredType) throws BeansException; <T> T getBean(Class<T> requiredType, Object... args) throws BeansException; // 提供对bean的检索,看看是否在IOC容器有这个名字的bean boolean containsBean(String name); // 根据bean名字得到bean实例,并同时判断这个bean是不是单例 boolean isSingleton(String name) throws NoSuchBeanDefinitionException; boolean isPrototype(String name) throws NoSuchBeanDefinitionException; boolean isTypeMatch(String name, ResolvableType typeToMatch) throws NoSuchBeanDefinitionException; boolean isTypeMatch(String name, @Nullable Class<?> typeToMatch) throws NoSuchBeanDefinitionException; // 得到bean实例的Class类型 @Nullable Class<?> getType(String name) throws NoSuchBeanDefinitionException; // 得到bean的别名,如果根据别名检索,那么其原名也会被检索出来 String[] getAliases(String name); }BeanFactory 主要使用场景:是从 IoC 容器中获取 Bean 对象。
② FactoryBean 它是一个 Bean,但又不仅仅是一个普通的 Bean,它是一个能生成 Bean 对象的工厂。
它的使用示例如下:
@Component public class MyBean implements FactoryBean { private String message; public MyBean() { this.message = "通过构造方法初始化实例"; } @Override public Object getObject() throws Exception { // 方法增强 return new MyBean("通过 FactoryBean.getObject() 创建实例"); } @Override public Class<?> getObjectType() { return MyBean.class; } public String getMessage() { return message; } }FactoryBean 在 Spring 中最为典型的一个应用就是用来创建 AOP 的代理对象。
FactoryBean 源码如下:
public interface FactoryBean<T> { // 从工厂中获取bean @Nullable T getObject() throws Exception; // 获取Bean工厂创建的对象的类型 @Nullable Class<?> getObjectType(); // Bean工厂创建的对象是否是单例模式 default boolean isSingleton() { return true; } }# 什么是AOP?实际工作中AOP的使用场景有哪些?
AOP(Aspect-OrientedProgramming,面向切面编程)可以说是 OOP(Object-Oriented Programing,面向对象编程)的补充和完善,OOP 引入封装、继承和多态性等概念来建立一种公共对象处理的能力,当我们需要处理公共行为的时候,OOP 就会显得无能为力,而 AOP 的出现正好解决了这个问题。比如统一的日志处理模块、授权验证模块等都可以使用 AOP 很轻松的处理。
AOP 优点主要有以下几个:
- 集中处理某一类问题,方便维护。
- 逻辑更加清晰。
- 降低模块间的耦合度。
AOP 常见使用场景有以下几个:
- 用户登录和鉴权。
- 统一日志记录。
- 统一方法执行时间统计。
- 统一的返回格式设置。
- 统一的异常处理。
- 声明式事务的实现。
# 说一下AOP的底层实现原理?
Spring 中的 AOP 底层是通过代理来实现的,而 Spring 中使用了以下两种代理:
- JDK 动态代理:对于实现了接口的目标类,Spring 使用 Java 提供的 java.lang.reflect.Proxy 类来创建代理对象。它要求目标类实现至少一个接口,并通过接口生成代理对象,代理对象实现了相同的接口,并且调用代理方法时会触发代理处理器的逻辑。JDK 动态代理底层又是通过反射实现的。
- CGLib 代理:对于没有实现接口的目标类,Spring 使用 CGLIB 来创建代理对象。CGLIB 会生成目标类的子类作为代理,重写方法并在方法前后插入切面逻辑。CGLib 底层是通过生成目标类的字节码来实现的。
这点可以从 Bean 的初始化源码中看到,AOP 源码实现流程:
- Bean 初始化源码 initializeBean 方法,调用了 BeanPostProcessor 后置处理方法,如下图所示:
- applyBeanPostProcessorsAfterInitialization 方法中会调用 postProcessAfterInitialization 方法,如下图所示:
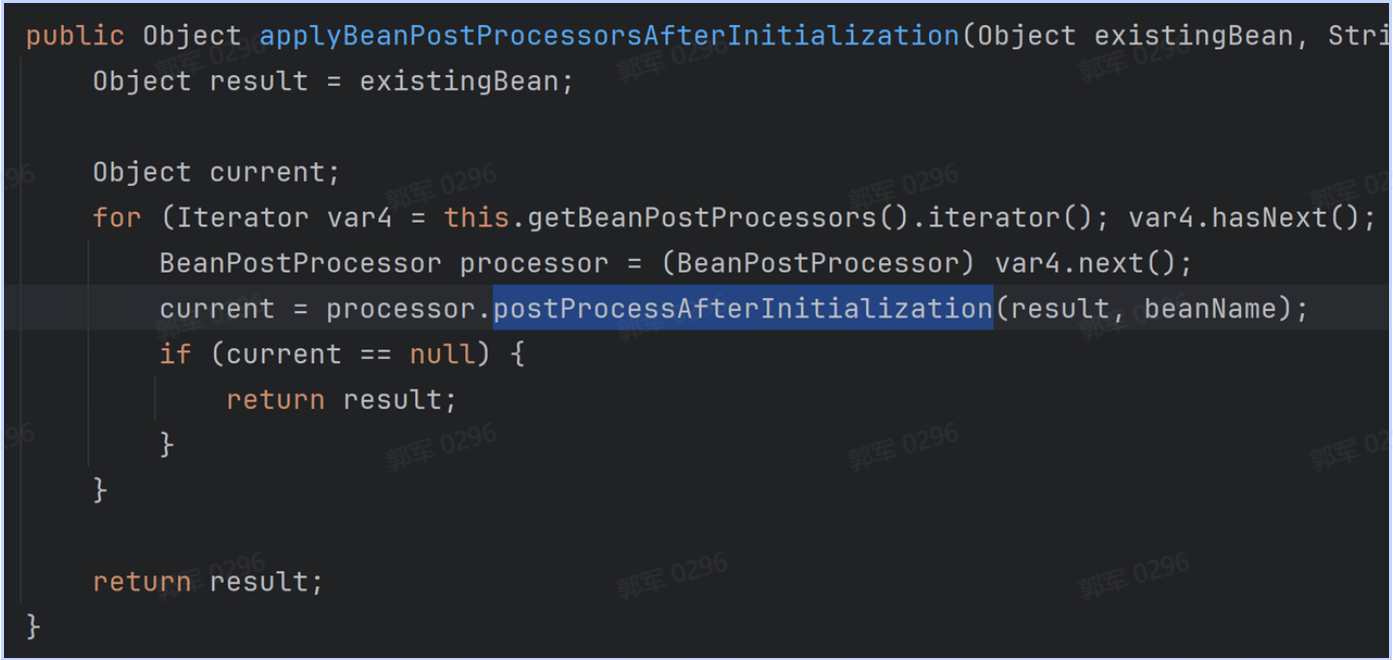
- AbstractAutoProxyCreator 类中的 postProcessAfterInitialization 里面就创建了代理对象,源码如下:
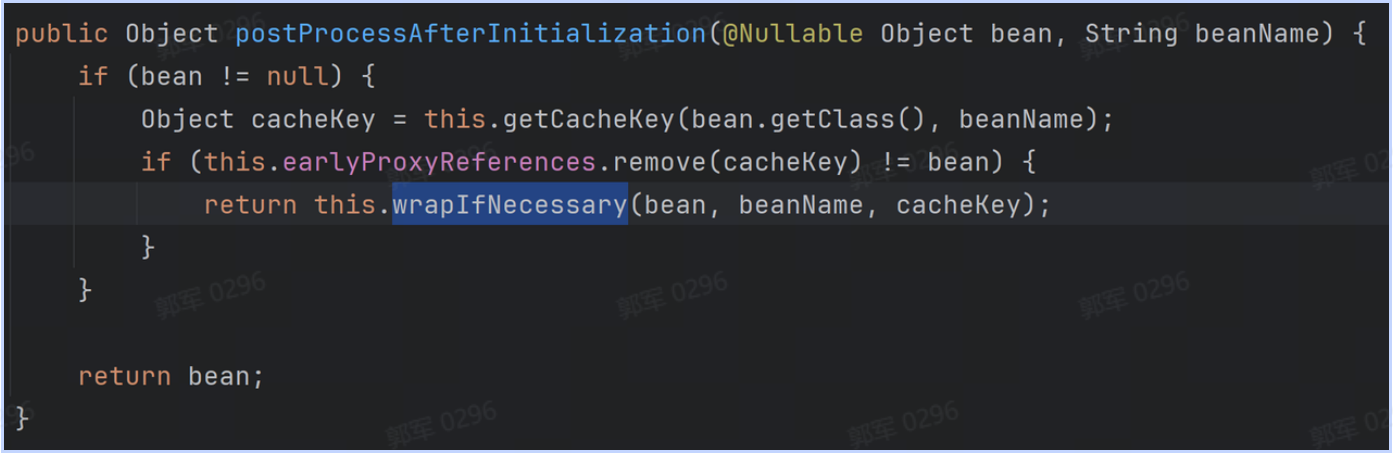
- 继续看 wrapIfNecessary 方法的实现里,如果存在 advice 会调用 createProxy 生成代理对象:
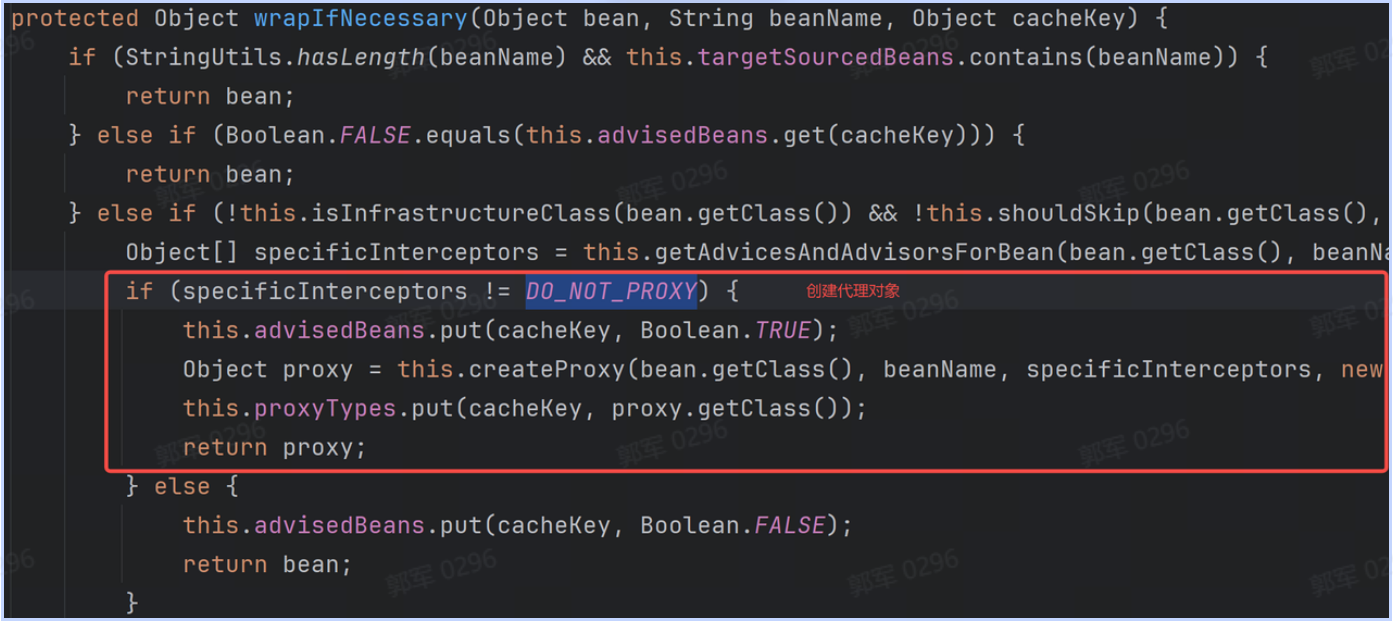
# JDK动态代理和CGLib有什么区别?
JDK 动态代理(JDK Proxy)和 CGLib 都是 Spring 中用于实现 AOP 的代理技术,但它们存在以下区别:
- 来源不同:JDK Proxy 是 Java 语言自带的功能,无需通过加载第三方类实现。Java 对 JDK Proxy 提供了稳定的支持,并且会持续的升级和更新 JDK Proxy,例如 Java 8 版本中的 JDK Proxy 性能相比于之前版本提升了很多;而 CGLib 是第三方提供的工具,基于 ASM(一个字节码操作框架)实现的。
- 使用场景不同:JDK Proxy 只能代理实现了接口的类,而 CGLib 无需实现接口,它是通过实现目标类的子类来完成调用的,所以要求被代理类不能被 final 修饰。
- 性能不同:JDK Proxy 在 JDK 7 之前性能远不如 CGLib,但 JDK 7 之后(JDK 7 和 JDK 8 都有优化)JDK Proxy 性能就略高于 CGLib 了。
小结:JDK Proxy 是 Java 自带的,在 JDK 高版本性能比较高的动态代理工具,但它要求被代理类必须要实现接口,它的性能在 JDK 7 之后也略高于 CGLib;而 CGLib 是基于字节码技术实现的第三方动态代理,它是通过生成代理对象的子类来实现代理的,所以要求被代理类不能被 final 修饰。
# SpringAOP默认使用的是JDK动态代理还是CGLib?
Spring 中默认使用的是 JDK 动态代理,这点官网文档中有具体的说明:
https://docs.spring.io/spring-framework/reference/core/aop/introduction-proxies.html

# SpringBoot中AOP默认使用的是JDK动态代理还是CGLib?如何证明这个问题?
Spring AOP 默认使用的是 JDK 实现动态代理的,这点官网文档中有具体的说明:
https://docs.spring.io/spring-framework/reference/core/aop/introduction-proxies.html
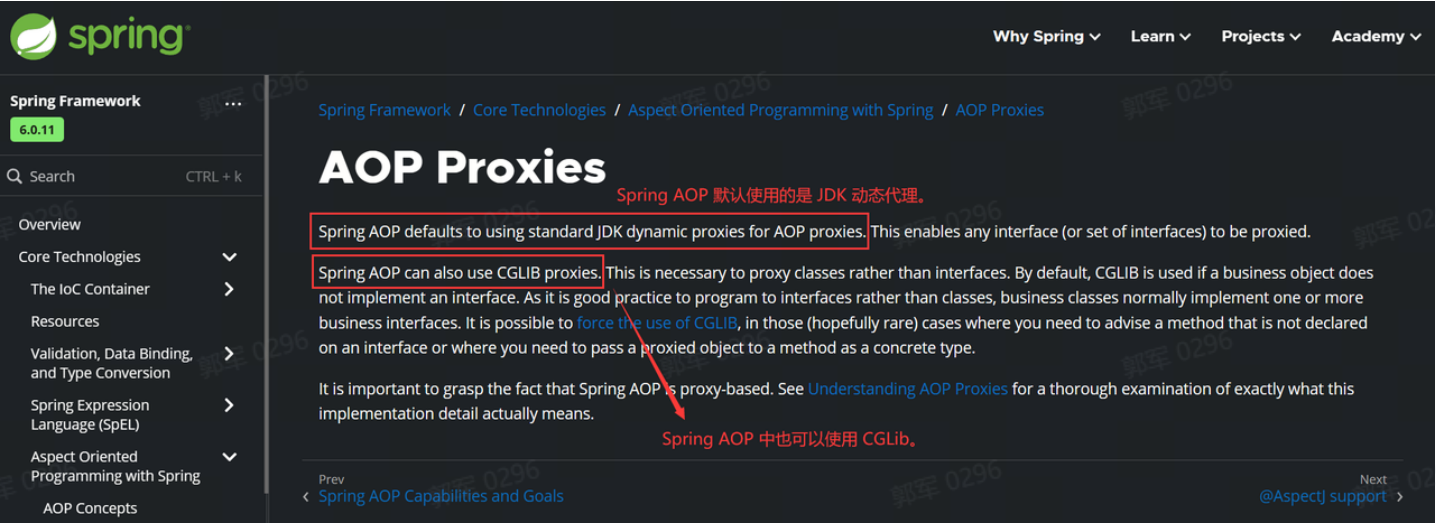
然而,Spring Boot 2.0 之后却默认并只使用了 CGLib,如下图所示:
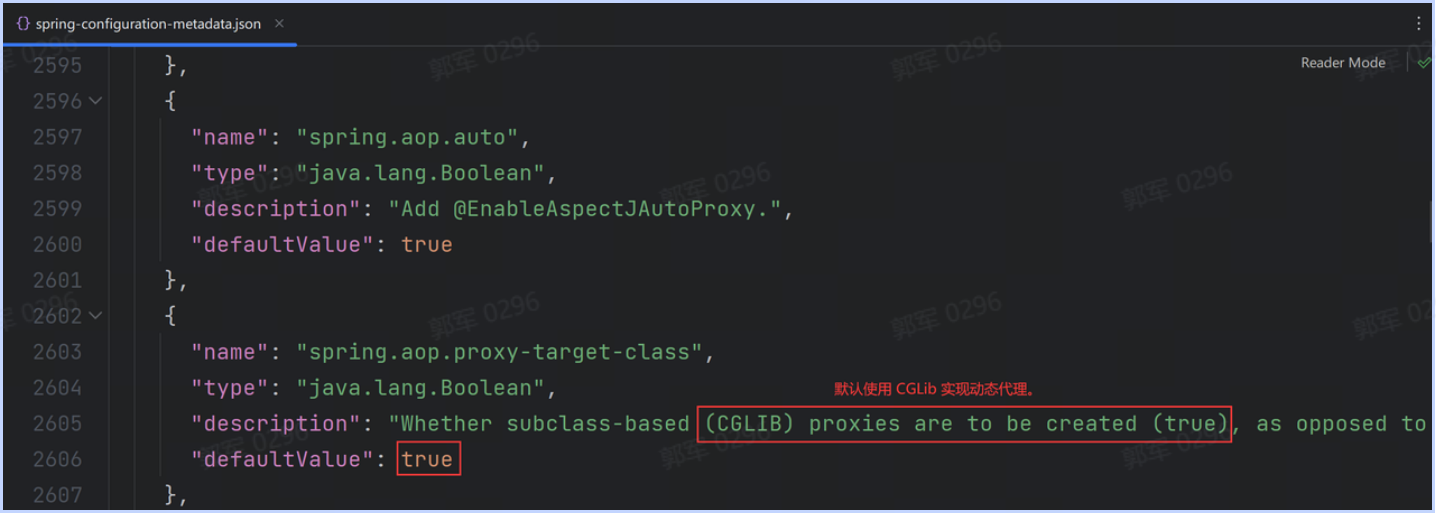
此配置文件为 Spring Boot 自动注入的配置文件,所以在 Spring Boot 2.x 之后,它里面只会使用 CGLib 作为动态代理,无论被代理类是否实现接口都会使用 CGLib 来实现。
证明 Spring Boot 中 AOP 只使用了 CGLib
Spring Boot 2 之后默认并只使用了 CGLib,这点可以通过给被代理类,添加 final 修饰来证明,因为 CGLib 是通过生成子类来实现的动态代理,如果被代理类使用 final 修饰,则自然会报错,而咱们下面的代码也证明了这一点,如下图所示:
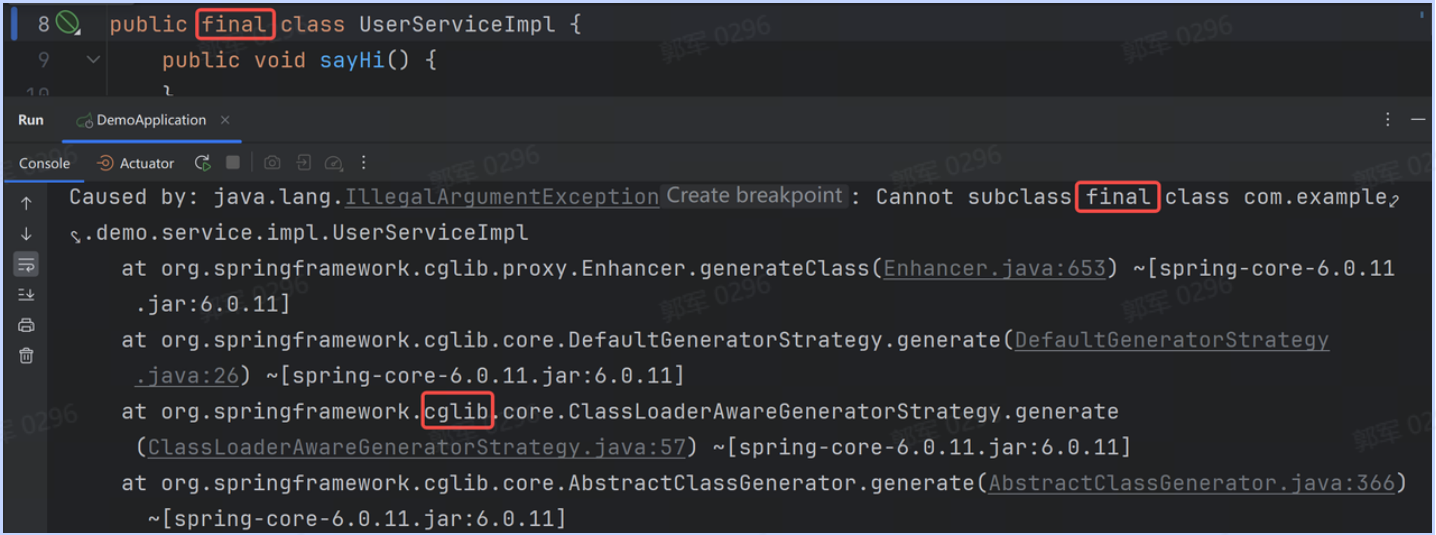
配置使用 JDK Proxy 动态代理
可以在配置文件中设置以下配置来开启 JDK 动态代理:
# 是否启用 aop spring.aop.auto=true # 代理方式:设置为 true 时表示强制使用 cglib 代理 spring.aop.proxy-target-class=false# Bean有几种注入方式?它们有什么区别?
Bean 对象有以下 3 种注入方式:
- 属性注入(Field Injection)
- Setter 注入(Setter Injection)
- 构造方法注入(Constructor Injection)
接下来,我们分别来看。
① 属性注入
属性注入是我们最熟悉,也是日常开发中使用最多的一种注入方式,它的实现代码如下:
@RestController public class UserController { // 属性对象 @Autowired private UserService userService; @RequestMapping("/add") public UserInfo add(String username, String password) { return userService.add(username, password); } }优点分析
属性注入最大的优点就是实现简单、使用简单,只需要给变量上添加一个注解(@Autowired),就可以在不 new 对象的情况下,直接获得注入的对象了(这就是 DI 的功能和魅力所在),所以它的优点就是使用简单。
缺点分析
属性注入的缺点主要包含以下 2 个:
- 功能性问题:无法注入一个不可变的对象(final 修饰的对象)。
 原因也很简单:在 Java 中 final 对象(不可变)要么直接赋值,要么在构造方法中赋值,所以当使用属性注入 final 对象时,它不符合 Java 中 final 的使用规范,所以就不能注入成功了。
原因也很简单:在 Java 中 final 对象(不可变)要么直接赋值,要么在构造方法中赋值,所以当使用属性注入 final 对象时,它不符合 Java 中 final 的使用规范,所以就不能注入成功了。 - 通用性问题:只能适应于 IoC 容器,Idea 也会提示你,不建议使用:
② Setter 注入
Setter 注入的实现代码如下:
@RestController public class UserController { // Setter 注入 private UserService userService; @Autowired public void setUserService(UserService userService) { this.userService = userService; } @RequestMapping("/add") public UserInfo add(String username, String password) { return userService.add(username, password); } }从上面代码可以看出,Setter 注入比属性注入要麻烦很多。
优缺点分析
Setter 优点是它符合单一职责的设计原则,因为每一个 Setter 只针对一个对象。
但它的缺点也很明显,它的缺点主要体现在以下 2 点:
- 不能注入不可变对象(final 修饰的对象)。
- 注入的对象可调用多次,也就是注入对象会被修改。
③ 构造方法注入 构造方法注入是 Spring 官方从 4.x 之后推荐的注入方式,它的实现代码如下:
@RestController public class UserController { // 构造方法注入 private UserService userService; @Autowired public UserController(UserService userService) { this.userService = userService; } @RequestMapping("/add") public UserInfo add(String username, String password) { return userService.add(username, password); } }当然,如果当前的类中只有一个构造方法,那么 @Autowired 也可以省略,所以以上代码还可以这样写:
@RestController public class UserController { // 构造方法注入 private UserService userService; public UserController(UserService userService) { this.userService = userService; } @RequestMapping("/add") public UserInfo add(String username, String password) { return userService.add(username, password); } }优点分析
构造方法注入相比于前两种注入方法,它可以注入不可变对象,并且它只会执行一次,也不存在像 Setter 注入那样,被注入的对象随时被修改的情况,它的优点有以下 4 个:
- 可注入不可变对象。
- 注入对象不会被修改。
- 注入对象会被完全初始化。
- 通用性更好。
优点1:注入不可变对象
使用构造方法注入可以注入不可变对象,如下代码所示:
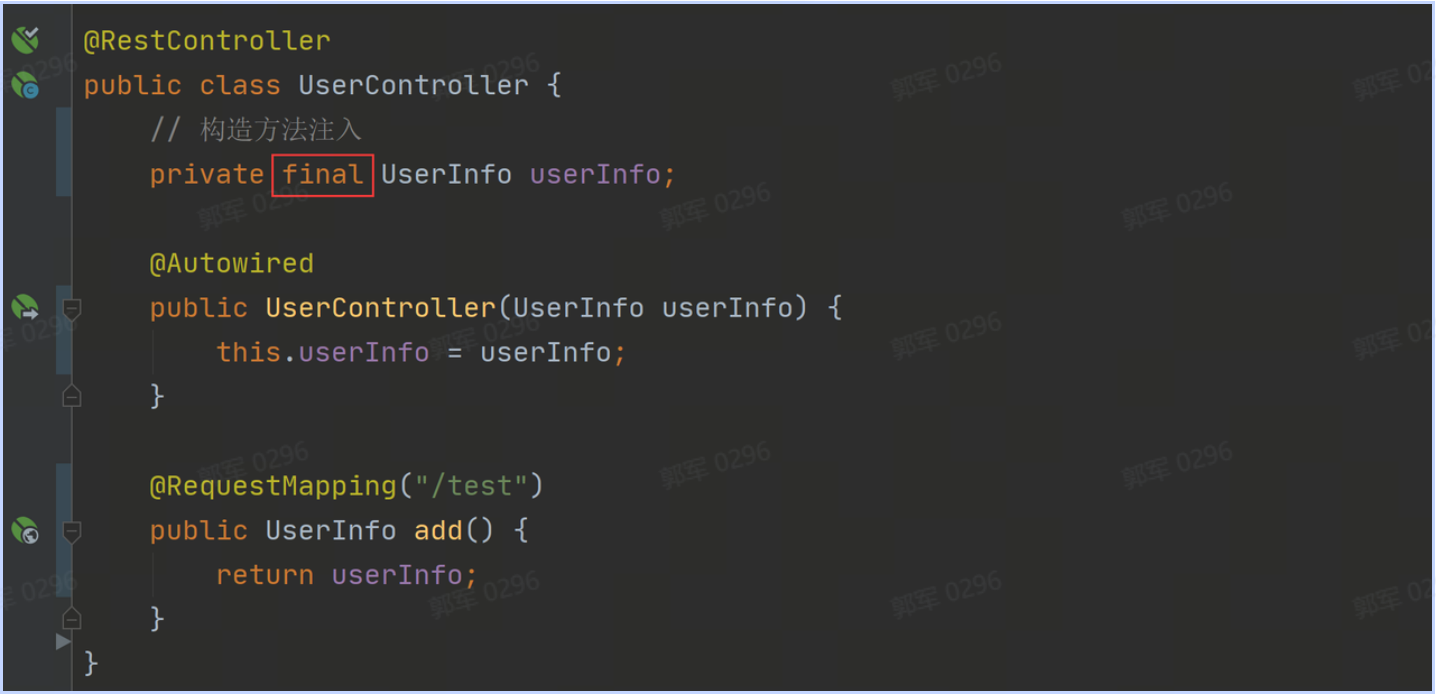
优点2:注入对象不会被修改
构造方法注入不会像 Setter 注入那样,构造方法在对象创建时只会执行一次,因此它不存在注入对象被随时(调用)修改的情况。
优点3:完全初始化
因为依赖对象是在构造方法中执行的,而构造方法是在对象创建之初执行的,因此被注入的对象在使用之前,会被完全初始化,这也是构造方法注入的优点之一。
优点4:通用性更好
构造方法和属性注入不同,构造方法注入可适用于任何环境,无论是 IoC 框架还是非 IoC 框架,构造方法注入的代码都是通用的,所以它的通用性更好。
缺点分析
构造方法注入的唯一缺点就是没有属性注入写法简单。
# 说一下Bean的生命周期?
Bean 生命周期是指其在 Spring 容器中从创建到销毁的过程。
在 Spring 源码中,AbstractAutowireCapableBeanFactory 是用于实现 Bean 的自动装配和创建的关键类。它里面的 doCreateBean 方法包含了 Bean 生命周期的实现逻辑,如下源码所示(以下源码基于 Spring 6):
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException { BeanWrapper instanceWrapper = null; if (mbd.isSingleton()) { instanceWrapper = (BeanWrapper)this.factoryBeanInstanceCache.remove(beanName); } // a.实例化 Bean if (instanceWrapper == null) { instanceWrapper = this.createBeanInstance(beanName, mbd, args); } // 忽略其他方法... Object exposedObject = bean; try { // b.设置属性 this.populateBean(beanName, mbd, instanceWrapper); // c.执行初始化方法 exposedObject = this.initializeBean(beanName, exposedObject, mbd); } catch (Throwable var18) { if (var18 instanceof BeanCreationException bce) { if (beanName.equals(bce.getBeanName())) { throw bce; } } throw new BeanCreationException(mbd.getResourceDescription(), beanName, var18.getMessage(), var18); } // 忽略其他方法... // 定义 Bean 的销毁回调方法 try { this.registerDisposableBeanIfNecessary(beanName, bean, mbd); return exposedObject; } catch (BeanDefinitionValidationException var16) { throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Invalid destruction signature", var16); } }# Bean是线程安全的吗?实际工作中怎么保证其线程安全?
过滤器(Filter)是一种常见的 Web 组件,用于在 Servlet 容器中对请求和响应进行预处理和后处理。过滤器提供了一种在请求和响应的处理链上干预和修改数据的机制,可以用于实现一些与应用程序业务逻辑无关的通用功能。
过滤器可以使用 Servlet 3.0 提供的 @WebFilter 注解,配置过滤的 URL 规则,然后再实现 Filter 接口,重写接口中的 doFilter 方法,具体实现代码如下:
import org.springframework.stereotype.Component; import javax.servlet.*; import javax.servlet.annotation.WebFilter; import java.io.IOException; @Component @WebFilter(urlPatterns = "/*") public class TestFilter implements Filter { @Override public void init(FilterConfig filterConfig) throws ServletException { System.out.println("过滤器:执行 init 方法。"); } @Override public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException { System.out.println("过滤器:开始执行 doFilter 方法。"); // 请求放行 filterChain.doFilter(servletRequest, servletResponse); System.out.println("过滤器:结束执行 doFilter 方法。"); } @Override public void destroy() { System.out.println("过滤器:执行 destroy 方法。"); } }其中:
- void init(FilterConfig filterConfig):容器启动(初始化 Filter)时会被调用,整个程序运行期只会被调用一次。用于实现 Filter 对象的初始化。
- void doFilter(ServletRequest request, ServletResponse response,FilterChain chain):具体的过滤功能实现代码,通过此方法对请求进行过滤处理,其中 FilterChain 参数是用来调用下一个过滤器或执行下一个流程。
- void destroy():用于 Filter 销毁前完成相关资源的回收工作。
# **SpringBoot中的自动装配是啥意思?举例说明一下? **
Spring Boot 的自动装配(Auto-Configuration)是指在应用程序启动时,根据类路径下的依赖、配置文件以及预定义的规则,自动配置和初始化 Spring 应用程序中的各种组件、模块和功能的过程。
这种自动配置机制大大减少了开发人员手动配置的工作,使得开发者可以更专注于业务逻辑的实现,同时提供了更高效、快速的应用程序启动和开发体验。
例如,在 Spring 我们需要手动设置数据库的连接 URL、用户名、密码等参数,并将其实例化为一个 Bean,如下代码是所示:
import javax.sql.DataSource; import org.apache.commons.dbcp2.BasicDataSource; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class DatabaseConfig { @Bean public DataSource dataSource() { BasicDataSource dataSource = new BasicDataSource(); dataSource.setUrl("jdbc:mysql://localhost:3306/mydb"); dataSource.setUsername("username"); dataSource.setPassword("password"); return dataSource; } }而在 Spring Boot 中,虽然我们只需要通过 application.properties 或 application.yml 文件配置数据源信息,Spring Boot 就会自动根据这些属性生成 DataSource Bean,而无需手动配置。
application.properties 示例配置如下:
spring.datasource.url=jdbc:mysql://localhost:3306/mydb spring.datasource.username=username spring.datasource.password=password spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver# 如何实现自定义注解?实际工作中哪些地方使用到了自定义注解?
自定义注解可以标记在方法上或类上,用于在编译期或运行期进行特定的业务功能处理。在 Java 中,自定义注解使用 @interface 关键字来定义,它可以实现如:日志记录、性能监控、权限校验等功能。
自定义注解实现方式
在 Spring Boot 中实现一个自定义注解可以通过以下两种方式实现:
- 通过 AOP(面向切面编程)实现。
- 通过拦截器(Interceptor)实现。
实际工作中哪里会用到自定义注解?
实际工作中我们通常会使用自定义注解来实现如权限验证,或者是幂等性判断等功能。
幂等性判断是指在分布式系统或并发环境中,对于同一操作的多次重复请求,系统的响应结果应该是一致的。简而言之,无论接收到多少次相同的请求,系统的行为和结果都应该是相同的。
# 什么是拦截器?如何实现拦截器?
拦截器(Interceptor)是一种在应用程序中用于拦截、处理和转换请求和响应的组件。在 Web 开发中,拦截器是一种常见的技术,用于在请求到达控制器之前或响应返回浏览器之前进行干预和处理。
在 Spring Boot 中拦截器的实现分为两步:
- 创建一个普通的拦截器,实现 HandlerInterceptor 接口,并重写接口中的相关方法。
- 将上一步创建的拦截器加入到 Spring Boot 的配置文件中,并配置拦截规则。
具体实现如下。
1.实现自定义拦截器
import org.springframework.stereotype.Component; import org.springframework.web.servlet.HandlerInterceptor; import org.springframework.web.servlet.ModelAndView; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; @Component public class TestInterceptor implements HandlerInterceptor { @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { System.out.println("拦截器:执行 preHandle 方法。"); return true; } @Override public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception { System.out.println("拦截器:执行 postHandle 方法。"); } @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception { System.out.println("拦截器:执行 afterCompletion 方法。"); } }其中:
- preHandle 方法:在目标方法执行前被调用,也就是调用目标方法之前被调用。比如我们在操作数据之前先要验证用户的登录信息,就可以在此方法中实现,如果验证成功则返回 true,继续执行数据操作业务;否则就返回 false,后续操作数据的业务就不会被执行了。
- postHandle 方法:调用请求方法之后执行,但它会在 DispatcherServlet 进行渲染视图之前被执行。
- afterCompletion 方法:会在整个请求结束之后再执行,也就是在 DispatcherServlet 渲染了对应的视图之后再执行。
2.配置拦截规则
最后,我们再将上面的拦截器注入到项目配置文件中,并设置相应拦截规则,具体实现代码如下:
import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Configuration; import org.springframework.web.servlet.config.annotation.InterceptorRegistry; import org.springframework.web.servlet.config.annotation.WebMvcConfigurer; @Configuration public class AppConfig implements WebMvcConfigurer { // 注入拦截器 @Autowired private TestInterceptor testInterceptor; @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(testInterceptor) // 添加拦截器 .addPathPatterns("/**"); // 拦截所有地址 .excludePathPatterns("/login"); // 放行接口 } }# 什么是过滤器?如何实现过滤器?
过滤器(Filter)是一种常见的 Web 组件,用于在 Servlet 容器中对请求和响应进行预处理和后处理。过滤器提供了一种在请求和响应的处理链上干预和修改数据的机制,可以用于实现一些与应用程序业务逻辑无关的通用功能。
过滤器可以使用 Servlet 3.0 提供的 @WebFilter 注解,配置过滤的 URL 规则,然后再实现 Filter 接口,重写接口中的 doFilter 方法,具体实现代码如下:
import org.springframework.stereotype.Component; import javax.servlet.*; import javax.servlet.annotation.WebFilter; import java.io.IOException; @Component @WebFilter(urlPatterns = "/*") public class TestFilter implements Filter { @Override public void init(FilterConfig filterConfig) throws ServletException { System.out.println("过滤器:执行 init 方法。"); } @Override public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException { System.out.println("过滤器:开始执行 doFilter 方法。"); // 请求放行 filterChain.doFilter(servletRequest, servletResponse); System.out.println("过滤器:结束执行 doFilter 方法。"); } @Override public void destroy() { System.out.println("过滤器:执行 destroy 方法。"); } }其中:
- void init(FilterConfig filterConfig):容器启动(初始化 Filter)时会被调用,整个程序运行期只会被调用一次。用于实现 Filter 对象的初始化。
- void doFilter(ServletRequest request, ServletResponse response,FilterChain chain):具体的过滤功能实现代码,通过此方法对请求进行过滤处理,其中 FilterChain 参数是用来调用下一个过滤器或执行下一个流程。
- void destroy():用于 Filter 销毁前完成相关资源的回收工作。
# 拦截器和过滤器有什么区别?
拦截器(Interceptor)和过滤器(Filter)都是用于在请求到达目标资源之前或之后进行处理的组件,但它们是完全不同的 2 个组件,它们的区别主要体现在以下 5 点:
- 所属框架不同:过滤器来自于 Servlet,而拦截器来自于 Spring 框架。
- 执行时机不同:请求的执行顺序是:请求进入容器 > 进入过滤器 > 进入 Servlet > 进入拦截器 > 执行控制器(Controller),所以过滤器和拦截器的执行时机,是过滤器会先执行,然后才会执行拦截器,最后才会进入真正的要调用的方法。
- 底层实现不同:过滤器是基于方法回调实现的,拦截器是基于 Spring 框架中的执行流程(调用 Controller 之前,先验证所有的拦截器,判断是否可以继续通行)实现的。
- 支持的项目类型不同:过滤器是 Servlet 规范中定义的,所以过滤器要依赖 Servlet 容器,它只能用在 Web 项目中;而拦截器是 Spring 中的一个组件,因此拦截器既可以用在 Web 项目中,同时还可以用在 Application 或 Swing 程序中。
- 使用场景不同:因为拦截器更接近业务系统,所以拦截器主要用来实现项目中的业务判断的,比如:登录判断、权限判断、日志记录等业务;而过滤器通常是用来实现通用功能过滤的,比如:敏感词过滤、字符集编码设置、响应数据压缩等功能。
# 什么是跨域问题?解决跨域的方案都有哪些?日常工作中会使用哪种解决方案?
跨域问题(Cross-Origin Resource Sharing,简称 CORS)指的是在浏览器中,通过 JavaScript 发起的跨域请求被阻止或限制的安全机制。
浏览器为了保护用户的信息安全,实施了同源策略(Same-Origin Policy),即只允许页面请求同源(相同协议、域名和端口)的资源。当 JavaScript 发起的请求跨越了同源策略,即请求的目标与当前页面的域名、端口、协议不一致时,浏览器会阻止请求的发送或接收。
解决跨域问题方案
跨域问题可以从以下方面解决:
- 在应用层面,例如 Spring Boot 项目中解决跨域问题。
- 在反向代理,例如 Nginx 中解决跨域问题。
- 在网关中,例如 Spring Cloud Gateway 中解决跨域问题。
① Spring Boot 中解决跨域
在 Spring Boot 中跨域问题有很多种解决方案,例如以下 5 个:
- 使用 @CrossOrigin 注解实现跨域【局域类跨域】
- 通过配置文件实现跨域【全局跨域】
- 通过 CorsFilter 对象实现跨域【全局跨域】
- 通过 Response 对象实现跨域【局域方法跨域】
- 通过实现 ResponseBodyAdvice 实现跨域【全局跨域】
接下来详细来看。
① 通过注解跨域
使用 @CrossOrigin 注解可以轻松的实现跨域,此注解既可以修饰类,也可以修饰方法。当修饰类时,表示此类中的所有接口都可以跨域;当修饰方法时,表示此方法可以跨域,它的实现如下:
import org.springframework.web.bind.annotation.CrossOrigin; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import java.util.HashMap; @RestController @CrossOrigin(origins = "*") public class TestController { @RequestMapping("/test") public HashMap<String, Object> test() { return new HashMap<String, Object>() {{ put("state", 200); put("data", "success"); put("msg", ""); }}; } }以上代码的执行结果如下图所示:
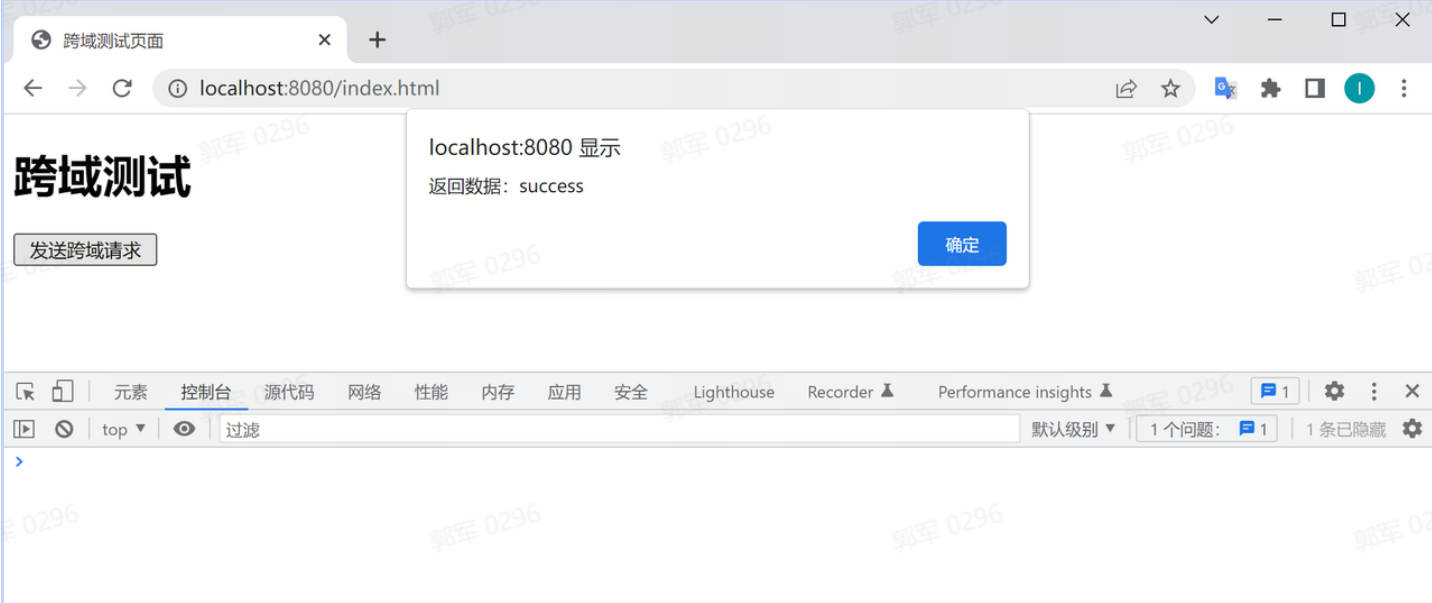
从上图中可以看出,前端项目访问另一个后端项目成功了,也就说明它解决了跨域问题。
优缺点分析
此方式虽然虽然实现(跨域)比较简单,但细心的朋友也能发现,使用此方式只能实现局部跨域,当一个项目中存在多个类的话,使用此方式就会比较麻烦(需要给所有类上都添加此注解)。
② 通过配置文件跨域
通过设置配置文件的方式就可以实现全局跨域了,它的实现步骤如下:
创建一个新配置文件。
添加 @Configuration 注解,实现 WebMvcConfigurer 接口。
重写 addCorsMappings 方法,设置允许跨域的代码。
具体实现代码如下:
import org.springframework.context.annotation.Configuration; import org.springframework.web.servlet.config.annotation.CorsRegistry; import org.springframework.web.servlet.config.annotation.WebMvcConfigurer; @Configuration // 一定不要忽略此注解 public class CorsConfig implements WebMvcConfigurer { @Override public void addCorsMappings(CorsRegistry registry) { registry.addMapping("/**") // 所有接口 .allowCredentials(true) // 是否发送 Cookie .allowedOriginPatterns("*") // 支持域 .allowedMethods(new String[]{"GET", "POST", "PUT", "DELETE"}) // 支持方法 .allowedHeaders("*") .exposedHeaders("*"); } }③ 通过 CorsFilter 跨域
此实现方式和上一种实现方式类似,它也可以实现全局跨域,它的具体实现代码如下:
import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.web.cors.CorsConfiguration; import org.springframework.web.cors.UrlBasedCorsConfigurationSource; import org.springframework.web.filter.CorsFilter; @Configuration // 一定不能忽略此注解 public class MyCorsFilter { @Bean public CorsFilter corsFilter() { // 1.创建 CORS 配置对象 CorsConfiguration config = new CorsConfiguration(); // 支持域 config.addAllowedOriginPattern("*"); // 是否发送 Cookie config.setAllowCredentials(true); // 支持请求方式 config.addAllowedMethod("*"); // 允许的原始请求头部信息 config.addAllowedHeader("*"); // 暴露的头部信息 config.addExposedHeader("*"); // 2.添加地址映射 UrlBasedCorsConfigurationSource corsConfigurationSource = new UrlBasedCorsConfigurationSource(); corsConfigurationSource.registerCorsConfiguration("/**", config); // 3.返回 CorsFilter 对象 return new CorsFilter(corsConfigurationSource); } }④ 通过 Response 跨域
此方式是解决跨域问题最原始的方式,但它可以支持任意的 Spring Boot 版本(早期的 Spring Boot 版本也是支持的)。但此方式也是局部跨域,它应用的范围最小,设置的是方法级别的跨域,它的具体实现代码如下:
import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import javax.servlet.http.HttpServletResponse; import java.util.HashMap; @RestController public class TestController { @RequestMapping("/test") public HashMap<String, Object> test(HttpServletResponse response) { // 设置跨域 response.setHeader("Access-Control-Allow-Origin", "*"); return new HashMap<String, Object>() {{ put("state", 200); put("data", "success"); put("msg", ""); }}; } }⑤ 通过 ResponseBodyAdvice 跨域
通过重写 ResponseBodyAdvice 接口中的 beforeBodyWrite(返回之前重写)方法,我们可以对所有的接口进行跨域设置,它的具体实现代码如下:
import org.springframework.core.MethodParameter; import org.springframework.http.MediaType; import org.springframework.http.server.ServerHttpRequest; import org.springframework.http.server.ServerHttpResponse; import org.springframework.web.bind.annotation.ControllerAdvice; import org.springframework.web.servlet.mvc.method.annotation.ResponseBodyAdvice; @ControllerAdvice public class ResponseAdvice implements ResponseBodyAdvice { /** * 内容是否需要重写(通过此方法可以选择性部分控制器和方法进行重写) * 返回 true 表示重写 */ @Override public boolean supports(MethodParameter returnType, Class converterType) { return true; } /** * 方法返回之前调用此方法 */ @Override public Object beforeBodyWrite(Object body, MethodParameter returnType, MediaType selectedContentType, Class selectedConverterType, ServerHttpRequest request, ServerHttpResponse response) { // 设置跨域 response.getHeaders().set("Access-Control-Allow-Origin", "*"); return body; } }此实现方式也是全局跨域,它对整个项目中的所有接口有效。
② Nginx 中解决跨域
在 Nginx 服务器的配置文件中添加以下代码:
server { listen 80; server_name your_domain.com; location /api { # 允许跨域请求的域名,* 表示允许所有域名访问 add_header 'Access-Control-Allow-Origin' '*'; # 允许跨域请求的方法 add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS'; # 允许跨域请求的自定义 Header add_header 'Access-Control-Allow-Headers' 'Origin, X-Requested-With, Content-Type, Accept'; # 允许跨域请求的 Credential add_header 'Access-Control-Allow-Credentials' 'true'; # 预检请求的存活时间,即 Options 请求的响应缓存时间 add_header 'Access-Control-Max-Age' 3600; # 处理预检请求 if ($request_method = 'OPTIONS') { return 204; } } # 其他配置... }上述示例中,location /api 代表配置针对 /api 路径的请求进行跨域设置。可以根据具体需要修改 location 的值和其他相关参数。配置中的 add_header 指令用于设置响应头部,常用的响应头部包括以下这些:
- Access-Control-Allow-Origin:用于指定允许跨域的域名,可以设置为 * 表示允许所有域名访问。
- Access-Control-Allow-Methods:用于指定允许的跨域请求的方法,例如 GET、POST、OPTIONS 等。
- Access-Control-Allow-Headers:用于指定允许的跨域请求的自定义 Header。
- Access-Control-Allow-Credentials:用于指定是否允许跨域请求发送和接收 Cookie。
- Access-Control-Max-Age:用于设置预检请求(OPTIONS 请求)的响应缓存时间。
③ 网关中解决跨域
Spring Cloud Gateway 中解决跨域问题可以通过以下两种方式实现:
- 通过在配置文件中配置跨域实现。
- 通过在框架中添加 CorsWebFilter 来解决跨域问题。
a.配置文件中设置跨域 在 application.yml 或 application.properties 中添加以下配置:
spring: cloud: gateway: globalcors: corsConfigurations: '[/**]': # 这里的'/**'表示对所有路由生效,可以根据需要调整为特定路径 allowedOrigins: "*" # 允许所有的源地址,也可以指定具体的域名 allowedMethods: # 允许的 HTTP 方法类型 - GET - POST - PUT - DELETE - OPTIONS allowedHeaders: "*" # 允许所有的请求头,也可以指定具体的请求头 allowCredentials: true # 是否允许携带凭证(cookies) maxAge: 3600 # CORS预检请求的有效期(秒)其中:
- allowedOrigins: 设置允许访问的来源域名列表,"*" 表示允许任何源。
- allowedMethods: 指定哪些HTTP方法可以被用于跨域请求。
- allowedHeaders: 客户端发送的请求头列表,"*" 表示允许任何请求头。
- allowCredentials: 当设为 true 时,允许浏览器在发起跨域请求时携带认证信息(例如 cookies)。
- maxAge: 预检请求的结果可以在客户端缓存的最大时间。
通过这样的配置,Spring Cloud Gateway 网关将自动处理所有经过它的跨域请求,并添加相应的响应头,从而允许前端应用执行跨域请求。
b.添加 CorsWebFilter 来解决跨域问题 在 Spring-Framework 从 5.3 版本之前,使用以下代码可以让 Spring Cloud Gateway 网关允许跨域:
@Configuration public class GlobalCorsConfig { @Bean public CorsWebFilter corsWebFilter() { CorsConfiguration config = new CorsConfiguration(); // 这里仅为了说明问题,配置为放行所有域名,生产环境请对此进行修改 config.addAllowedOrigin("*"); // 放行的请求头 config.addAllowedHeader("*"); // 放行的请求类型,有 GET, POST, PUT, DELETE, OPTIONS config.addAllowedMethod("*"); // 暴露头部信息 config.addExposedHeader("*"); // 是否允许发送 Cookie config.setAllowCredentials(true); UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource(); source.registerCorsConfiguration("/**", config); return new CorsWebFilter(source); } }而 Spring-Framework 5.3 版本之后,关于 CORS 跨域配置类 CorsConfiguration 中将 addAllowedOrigin 方法名修改为 addAllowedOriginPattern,因此配置了变成了以下这样:
@Configuration public class GlobalCorsConfig { @Bean public CorsWebFilter corsWebFilter() { CorsConfiguration config = new CorsConfiguration(); // 这里仅为了说明问题,配置为放行所有域名,生产环境请对此进行修改 config.addAllowedOriginPattern("*"); // 放行的请求头 config.addAllowedHeader("*"); // 放行的请求类型,有 GET, POST, PUT, DELETE, OPTIONS config.addAllowedMethod("*"); // 暴露头部信息 config.addExposedHeader("*"); // 是否允许发送 Cookie config.setAllowCredentials(true); UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource(); source.registerCorsConfiguration("/**", config); return new CorsWebFilter(source); } }# **@Transactional底层是如何实现的? **
@Transactional 底层是通过动态代理实现的。
当使用 @Transactional 注解标注一个方法时,Spring Boot 在运行时会生成一个代理对象,该代理对象拦截被注解的方法调用,并在方法调用前后进行事务管理。事务管理包括开启事务、提交事务或回滚事务等操作。
@Transactional 实现思路预览:
# 导致@Transactional失效的场景有哪些?导致事务失效背后的原因是啥?
导致 @Transactional 失效的常见场景有以下几个:
- @Transactional 添加在非 public 方法上。
- 使用 try/catch 处理异常。
- 调用类内部的 @Transactional 方法。
- 事务传播机制使用不当。
- 数据库不支持事务。
① 非 public 方法
当使用 @Transactional 修饰非 public 方法时,事务会失效,失效的原因主要有以下两层因素。
a.浅层原因
浅层原因是 @Transactional 源码限制了必须是 public 才能执行后续的代理流程,它的部分实现源码如下:
protected TransactionAttribute computeTransactionAttribute(Method method, Class<?> targetClass) { // Don't allow no-public methods as required. // 非 public 方法,设置为 null if (allowPublicMethodsOnly() && !Modifier.isPublic(method.getModifiers())) { return null; } // 后面代码省略.... }所以 @Transactional 修饰的方法是 public 才行。
b.深层次原因
深层次的原因 Spring Boot 的动态代理只能代理公共方法,而不能代理私有方法或受保护的方法。这是因为 Spring 的动态代理是基于 Java 的接口代理机制或者基于 CGLib 库来实现的,而这两种代理方式都只能代理公共方法。
- 接口代理:当目标类实现了接口时,Spring 使用 JDK 动态代理来生成代理对象。JDK 动态代理是通过生成实现目标类接口的匿名类,并将方法调用委托给目标类的实例来实现的。由于接口中的方法都是公共的,所以 JDK 动态代理只能代理公共方法。
- CGLib 代理:当目标类没有实现接口时,Spring 使用 CGLib 动态代理来生成代理对象。CGLib 动态代理是通过生成目标类的子类,并将方法调用委托给子类的实例来实现的。然而,Java 中的继承要求子类能够继承父类的方法,因此 CGLib 动态代理也只能代理目标类中的公共方法。
所以,由于动态代理的底层机制所限,Spring 的动态代理只能代理公共方法。
PS:虽然 CGLib 可以代理 protected 修饰的方法,但因为它是通过生成被代理类的子类来实现的,所以代理类中的方法也是被 protected 修饰的,又因为被 protected 修饰的方法不允许跨包非子类访问,所以被代理的方法访问是受限制的,因此 CGLib 只有代理公共方法,它的功能才是完整的,所以 CGLib 代理从业务逻辑的角度来说也只能代理公共方法。
② 使用 try/catch 处理异常 如果在 @Transactional 方法内部捕获了所有可能抛出的异常,但没有将它们重新抛出,那么事务就不能发现异常的存在,从而也就不会回滚事务了。
从 @Transactional 实现源码也可以看出,@Transactional 注解只有执行方式捕获到异常了才会回滚,反之则不会滚,核心源码如下:
protected Object invokeWithinTransaction(Method method, Class<?> targetClass, final InvocationCallback invocation) throws Throwable { // If the transaction attribute is null, the method is non-transactional. final TransactionAttribute txAttr = getTransactionAttributeSource().getTransactionAttribute(method, targetClass); final PlatformTransactionManager tm = determineTransactionManager(txAttr); final String joinpointIdentification = methodIdentification(method, targetClass); if (txAttr == null || !(tm instanceof CallbackPreferringPlatformTransactionManager)) { // Standard transaction demarcation with getTransaction and commit/rollback calls. // 自动开启事务 TransactionInfo txInfo = createTransactionIfNecessary(tm, txAttr, joinpointIdentification); Object retVal = null; try { // This is an around advice: Invoke the next interceptor in the chain. // This will normally result in a target object being invoked. // 反射调用业务方法 retVal = invocation.proceedWithInvocation(); } catch (Throwable ex) { // target invocation exception // 异常时,在 catch 逻辑中,自动回滚事务 completeTransactionAfterThrowing(txInfo, ex); throw ex; } finally { cleanupTransactionInfo(txInfo); } // 自动提交事务 commitTransactionAfterReturning(txInfo); return retVal; } else { // ..... } }PS:想要在 catch 里面手动回滚事务,可以通过 TransactionAspectSupport.currentTransactionStatus().setRollbackOnly(); 实现(手动事务回滚)。
③ 调用类内部的 @Transactional 方法
因为 @Transactional 是基于动态代理实现的,而当调用类内部的方法时,不是通过代理对象完成的,而是通过 this 对象实现的,这样就绕过了代理对象,从而事务就失效了。
④ 事务传播机制使用不当
如果事务传播机制设置为 Propagation.NEVER 以非事务方式运行,或者是 Propagation.NOT_SUPPORTED 以非事务方式运行,如果当前存在事务,则把当前事务挂起的传播机制,则当前 @Transactional 修饰的方法也是不会正常执行事务的。
⑤ 数据库不支持事务
Spring Boot/Spring 框架内之所以能使用事务是因为它们连接的数据库支持事务,这是前提条件,所以当数据库层面不支持事务时,那么框架中的代码无论怎么写都不会存在事务的。
# 什么是事务传播机制?它有啥用?
Spring Boot 事务传播机制是指,包含多个事务的方法在相互调用时,事务是如何在这些方法间传播的。

Spring Boot 事务传播机制可使用 @Transactional(propagation=Propagation.REQUIRED) 来定义,事务传播机制的级别包含以下 7 种:
- Propagation.REQUIRED:默认的事务传播级别,它表示如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
- Propagation.SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
- Propagation.MANDATORY:(mandatory:强制性)如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
- Propagation.REQUIRES_NEW:表示创建一个新的事务,如果当前存在事务,则把当前事务挂起。也就是说不管外部方法是否开启事务,Propagation.REQUIRES_NEW 修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
- Propagation.NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。
- Propagation.NEVER:以非事务方式运行,如果当前存在事务,则抛出异常。
- Propagation.NESTED:如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于 PROPAGATION_REQUIRED。
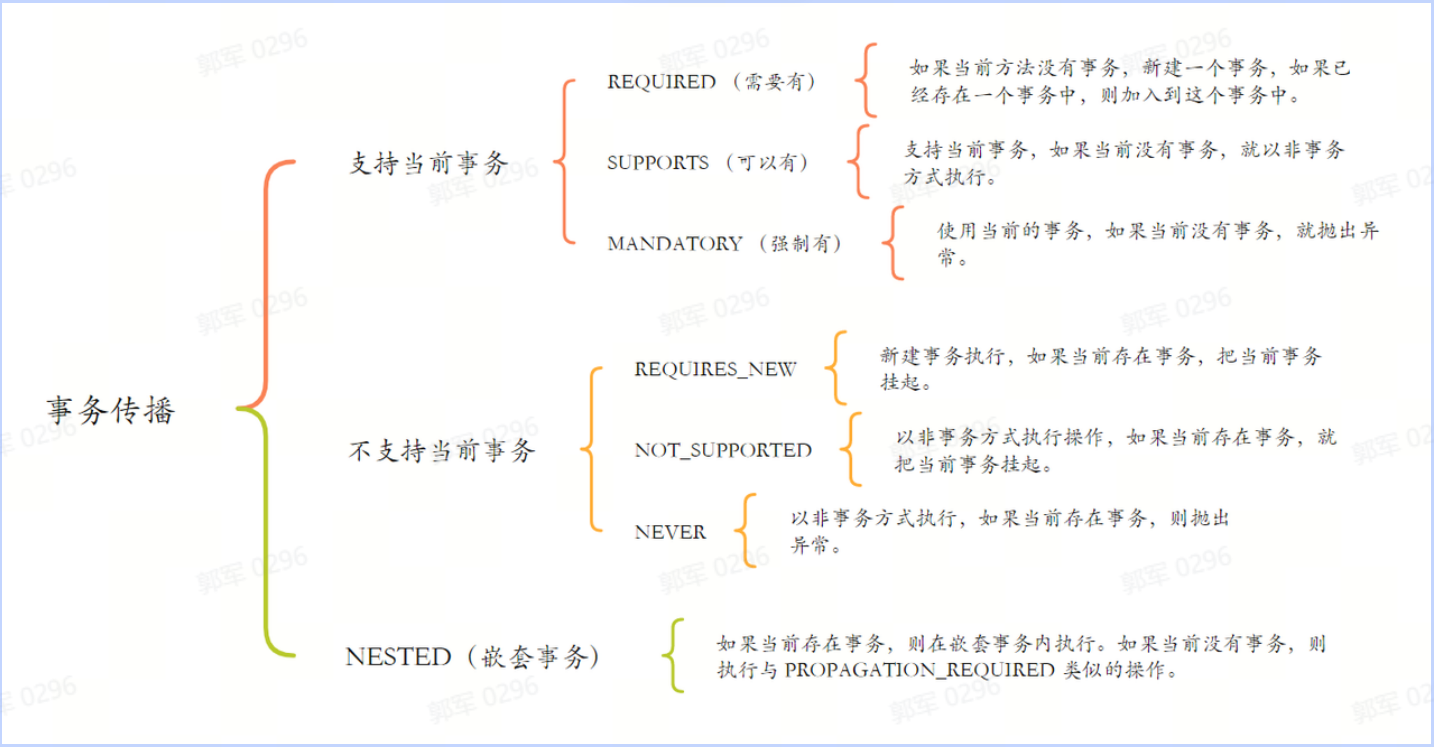
# SpringBoot中使用了哪些设计模式?
Spring 中常用的设计模式有以下几个:
- 工厂模式:Spring 通过 BeanFactory 接口及其实现类如 ApplicationContext 等,为应用程序提供了一个统一的 bean 工厂,负责创建和管理各种 bean 对象。
- 单例模式:Spring 默认将所有 bean 声明为单例。当容器启动时,每个 bean 只会被初始化一次,后续对同一 bean 的所有请求都会返回相同的实例。例如,通过 SingletonBeanRegistry 接口保证单例 bean 在整个应用上下文中只存在一个实例。
- 代理模式:Spring AOP(面向切面编程)大量使用了代理模式。它利用 JDK 动态代理或 CGLIB 库生成代理对象,实现代理功能以添加额外的横切关注点,如事务处理、日志记录、权限控制等。
- 观察者模式:Spring 事件驱动模型实现了观察者模式,通过 ApplicationEventPublisher 发布和监听事件,例如 ContextRefreshedEvent、SessionDestroyedEvent 等。
- 策略模式:Spring 框架中的资源加载(Resource)就是一个策略模式的例子。根据不同的资源路径,Spring 会选择合适的策略(如 ClassPathResource、FileSystemResource 等)进行资源加载。
- 装饰器模式:Spring MVC 的拦截器 Interceptor 可以看作是一种装饰器模式的应用,它允许我们包装 HandlerExecutionChain,在执行处理器方法前后插入自定义行为。
- 适配器模式:Spring 通过适配器模式整合不同类型的组件,比如对第三方数据源的连接池(如 DBCP、HikariCP 等)进行了适配,使其能够与 Spring 容器无缝集成。
- 模板方法模式:在 Spring JDBC 等模块中,提供了如 JdbcTemplate 这样的模板类,它们封装了通用的数据访问逻辑,而具体的操作由用户提供的 SQL 来实现。
# 六. MyBatis
# 说一下MyBatis执行流程?
MyBatis 执行流程如下:
- 加载配置文件:MyBatis 的执行流程从加载配置文件开始。通常,MyBatis 的配置文件是一个 XML 文件,其中包含了数据源配置、SQL 映射配置、连接池配置等信息。
- 构建 SqlSessionFactory:在配置文件加载后,MyBatis 使用配置信息来构建 SqlSessionFactory,这是 MyBatis 的核心工厂类。SqlSessionFactory 是线程安全的,它用于创建 SqlSession 对象。
- 创建 SqlSession:应用程序通过 SqlSessionFactory 创建 SqlSession 对象。SqlSession 代表一次数据库会话,它提供了执行 SQL 操作的方法。通常情况下,每个线程都应该有自己的 SqlSession 对象。
- 执行 SQL 查询:在 SqlSession 中,开发人员可以执行 SQL 查询,这可以通过两种方式来实现:
- 使用注解加 SQL:MyBatis 提供了注解加执行 SQL 的实现方式,MyBatis 会为 Mapper 接口生成实现类的代理对象,实际执行 SQL 查询。
- 使用 XML 映射文件:开发人员可以在 XML 映射文件中定义 SQL 查询语句和映射关系。然后,通过 SqlSession 执行这些 SQL 查询,将结果映射到 Java 对象上。
- SQL 解析和执行:MyBatis 会解析 SQL 查询,执行查询操作,并获取查询结果。
- 结果映射:MyBatis 使用配置的结果映射规则,将查询结果映射到 Java 对象上。这包括将数据库列映射到 Java 对象的属性上,并处理关联关系等。
- 返回结果:查询结果被返回给应用程序,开发人员可以对结果进行进一步处理、展示或持久化。
- 关闭 SqlSession:完成数据库操作后,关闭 SqlSession 释放资源。
# **${}和#{}有什么区别?什么情况下一定要使用${}? **
${} 和 #{} 都是 MyBatis 中用来替换参数的特殊标识,其用法如下:
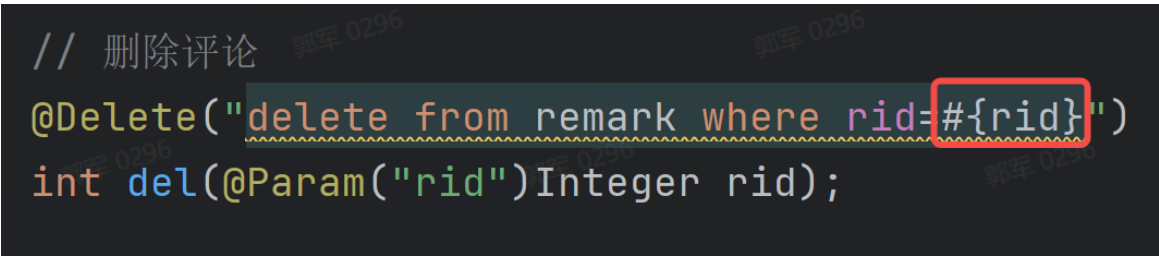
但它们二者区别很大,它们的主要区别有以下几个:
- 含义不同:${} 是直接替换(运行时已经替换成具体的执行 SQL 了),而 #{} 是预处理(运行时只是设置了占位符“?”,之后再通过声明器(statement)来替换占位符)。
- 使用场景不同:普通参数使用 #{},如果传递的是 SQL 命令或 SQL 关键字,需要使用 ${},但在使用前一定要做好安全验证。
- 安全性不同:使用 ${} 存在安全问题,如 SQL 注入,而 #{} 则不存在安全问题。
也就是说,为了防止安全问题,所以大部分场景都要使用 #{} 替换参数,但是如果传递的是 SQL 关键字,例如 order by xxx asc/desc 时(传递 asc 后 desc),一定要使用 ${} ,因为它需要在执行时就被替换成关键字,而不能使用占位符替代(占位符不用应用于 SQL 关键字,否则会报错)。
在传递 SQL 关键字时,一定要使用 ${},但使用前,一定要进行过滤和安全检查,以防止 SQL 注入。
# 什么是SQL注入?如何防止SQL注入?
SQL 注入即是指应用程序对用户输入数据的合法性没有判断或过滤不严,攻击者可以在应用程序中事先定义好的查询语句的结尾上添加额外的 SQL 语句,在管理员不知情的情况下实现非法操作,以此来实现欺骗数据库服务器执行非授权的任意查询,从而进一步得到相应的数据信息。
也就是说所谓的 SQL 注入指的是,使用某个特殊的 SQL 语句,利用 SQL 的执行特性,绕过 SQL 的安全检查,查询到本不该查询到的结果。
比如以下代码:
<select id="doLogin" resultType="com.example.demo.model.User"> select * from userinfo where username='${name}' and password='${pwd}' </select>sql 注入代码:“' or 1='1”,如下图所示:
 从上述结果可以看出,以上程序在应用程序不知情的情况下实现非法操作,以此来实现欺骗数据库服务器执行非授权的敏感数据。
从上述结果可以看出,以上程序在应用程序不知情的情况下实现非法操作,以此来实现欺骗数据库服务器执行非授权的敏感数据。如何防止SQL注入?
防止 SQL 注入常见方法有以下两个:
- 预编译语句与参数化查询:使用 PreparedStatement 可以有效防止 SQL 注入,因为它允许你先定义 SQL 语句的结构,然后将变量作为参数传入,数据库驱动程序会自动处理这些参数的安全性,确保它们不会干扰 SQL 语句的结构,如下代码所示
String sql = "SELECT * FROM users WHERE username = ? AND password = ?"; PreparedStatement pstmt = connection.prepareStatement(sql); pstmt.setString(1, userInputUsername); pstmt.setString(2, userInputPassword); ResultSet rs = pstmt.executeQuery();- 输入验证和过滤:对用户输入的信息进行验证和过滤,确保其符合预期的类型和格式。
# 说一下MyBaits中的二级缓存?
MyBaits 二级缓存是用于提高 MyBaits 查询数据库的性能,和减少数据库访问的机制。
顾名思义,MyBaits 二级缓存中总共有两个缓存机制:
- 一级缓存:SqlSession 级别的,MyBatis 自带的缓存功能,并且无法关闭。因此当有两个 SqlSession 访问相同的 SQL 时,一级缓存也不会生效,也需要查询两次数据库。在一个 service 调用两个相同的 mapper 方法时,依然是查询两次,因为它会创建两个 Sql Session 进行查询(为了提高性能)。
- 二级缓存:Mapper 级别的,只要是同一个 Mapper,无论使用多少个 SqlSession 来操作,数据都是共享的。也就是说,一个 sessionFactory 下的多个 session 之间共享的缓存,它的作用范围更大、生命周期更长,可以减少数据库查询次数,提高系统性能。但 MyBatis 的二级缓存默认是关闭的,需要使用时可手动开启。
二级缓存默认是不开启的,手动开启 MyBatis 的步骤如下:
- 在 mapper xml 中添加
标签。 - 在需要缓存的标签上添加 useCache="true"(新版本中此步骤可忽略,但为了兼容老版本,建议保留此项配置)。
完整示例实现如下:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.mybatis.demo.mapper.StudentMapper"> <cache/> <select id="getStudentCount" resultType="Integer" useCache="true"> select count(*) from student </select> </mapper>编写单元测试代码:
import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; @SpringBootTest class StudentMapperTest { @Autowired private StudentMapper studentMapper; @Test void getStudentCount() { int count = studentMapper.getStudentCount(); System.out.println("查询结果:" + count); int count2 = studentMapper.getStudentCount(); System.out.println("查询结果2:" + count2); } }执行以上单元测试的执行结果如下:
 从以上结果可以看出,两次查询虽然使用了不同的 SqlSession,但第二次查询使用了缓存,并未查询数据库。
从以上结果可以看出,两次查询虽然使用了不同的 SqlSession,但第二次查询使用了缓存,并未查询数据库。# 项ORM项目中类属性名和数据库字段名不一致会导致什么问题?它的解决方案有哪些?
在 ORM 项目中,如果类的属性名和数据库的字段名不一致会导致插入、修改时设置的这个不一致字段为 nul,查询时即使数据库有数据,那么查询到的结果也为 null。
它的常见解决方案有以下几个:
- 更改程序中的属性名,或数据库的字段名,让二者保持一致。
- 使用结果映射,使用
映射对应的字段。 - 使用 MyBatis Plus 框架中的 @TableField 注解映射二者字段,如下图所示:
 映射之后查询或其他操作都不会出现 NULL 的问题。
映射之后查询或其他操作都不会出现 NULL 的问题。 - 如果是查询操作,可以使用 as 重命名字段名,这样查询也就不会为 NULL 了。
# MyBatis中如何实现分页?它有几种实现分页的方式?
MyBaits 中实现分页有以下两种方式:
- 物理分页:物理分页是通过 SQL 查询语句,在数据库引擎层面实现的,如 MySQL 的 LIMIT 语法进行分页。
- 逻辑分页:逻辑分页是在应用程序层面进行的分页,通常是先查询出所有符合条件的数据,然后在内存中对数据进行分页操作。
① 物理分页 a.使用 limit 实现分页
物理分页可以直接在 XML 中拼加 SQL 进行分页:
<select id="getUserList" resultType="User"> select * from user limit #{limit} offset #{offset} </select>b.使用 PageHelper 插件实现分页
物理分页还可以使用 PageHelper 插件来实现,分页插件的使用文档:https://github.com/pagehelper/Mybatis-PageHelper/blob/master/wikis/zh/HowToUse.md
它的关键实现代码:
PageHelper.startPage(1, 10); List<User> list = userMapper.selectIf(1);PageHelper 实现原理分析
PageHelper 底层使用了 MyBatis 的拦截器(Interceptor)机制,在 MyBaits 进行查询时,拦截并对 SQL 语句进行动态修改(添加 limit 等分页查询操作),之后查询数据库、并对查询结果进行包装,包装成分页对象(如包含数据列表、总记录数、总页数等信息的分页对象),最后再将这个分页对象返回给客户端。
② 逻辑分页
MyBatis 自带的 RowBounds 进行分页就是逻辑分页,它是一次性查询很多数据,然后在数据中再进行检索,实现代码如下:
RowBounds rowBounds = new RowBounds(offset, limit); List<User> users = sqlSession.selectList("getUserList", null, rowBounds);其中 offset 为起始行偏移量,limit 是每页数据量,虽然设置了这两个值,但在使用 RowBounds 时,它会一次性查询多条数据,然后再在内存中进行 offset 和 limit 的筛选,最后在返回符合结果的数据。
# **MyBaits二级缓存有几种淘汰策略?如何设置缓存淘汰策略? **
MyBatis 中可用的缓存策略有以下几个:
- LRU – 最近最少使用:移除最长时间不被使用的对象。
- FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
- SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。
- WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
默认的缓存淘汰策略是 LRU。
可以通过 eviction 属性来设置淘汰策略,例如下面这样:
<cache eviction="FIFO"/># MyBatisPlus如何实现分页功能?它的底层是如何实现的?
MyBatis Plus 中实现分页功能,只需要以下两步
- 配置 MyBatis Plus 中的分页拦截器。
- 使用 Page 对象使用分页查询。 具体操作如下。
① 配置分页拦截器
@Configuration public class PageConfig { @Bean public MybatisPlusInterceptor mybatisPlusInterceptor(){ MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor(); // 将 MP 里面的分页插件设置 MP interceptor.addInnerInterceptor(new PaginationInnerInterceptor()); return interceptor; } }因为 MP 中内置了 PaginationInnerInterceptor 插件,所以可以在拦截器此处直接添加 new PaginationInnerInterceptor() 的代码。
分页插件支持的数据库有以下这些:
 更多内容,可以参考 MP 官网连接:https://baomidou.com/pages/97710a/#paginationinnerinterceptor
更多内容,可以参考 MP 官网连接:https://baomidou.com/pages/97710a/#paginationinnerinterceptor② 使用 Page 对象实现分页
@RequestMapping("/getpage") public Object getPage(Integer pageIndex){ // 分页对象 Page page = new Page(pageIndex,10); Page<User> result = userService.page(page); return result; }MyBatis Plus 分页功能的底层是如何实现的?
MyBatis Plus 分页功能底层是通过拦截器实现的,实现 MyBatis Plus 的第一步就是添加一个拦截器,这个拦截器就是用于拦截查询 SQL 的请求,拦截之后会对 SQL 语句进行动态修改(添加 limit 等分页查询操作),之后查询数据库,然后再对查询结果进行包装,包装成分页对象,最后再将分页对象返回给客户端。
# MyBatis中使用了哪些设计模式?举例说明一下
MyBatis 中使用的主要设计模式有以下几个。
1.工厂模式
工厂模式想必都比较熟悉,它是 Java 中最常用的设计模式之一。工厂模式就是提供一个工厂类,当有客户端需要调用的时候,只调用这个工厂类就可以得到自己想要的结果,从而无需关注某类的具体实现过程。这就好比你去餐馆吃饭,可以直接点菜,而不用考虑厨师是怎么做的。
工厂模式在 MyBatis 中的典型代表是 SqlSessionFactory。SqlSession 是 MyBatis 中的重要 Java 接口,可以通过该接口来执行 SQL 命令、获取映射器示例和管理事务,而 SqlSessionFactory 正是用来产生 SqlSession 对象的,所以它在 MyBatis 中是比较核心的接口之一。
2.建造者模式 建造者模式指的是将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。也就是说建造者模式是通过多个模块一步步实现了对象的构建,相同的构建过程可以创建不同的产品。
例如,组装电脑,最终的产品就是一台主机,然而不同的人对它的要求是不同的,比如设计人员需要显卡配置高的;而影片爱好者则需要硬盘足够大的(能把视频都保存起来),但对于显卡却没有太大的要求,我们的装机人员根据每个人不同的要求,组装相应电脑的过程就是建造者模式。 建造者模式在 MyBatis 中的典型代表是 SqlSessionFactoryBuilder。普通的对象都是通过 new 关键字直接创建的,但是如果创建对象需要的构造参数很多,且不能保证每个参数都是正确的或者不能一次性得到构建所需的所有参数,那么就需要将构建逻辑从对象本身抽离出来,让对象只关注功能,把构建交给构建类,这样可以简化对象的构建,也可以达到分步构建对象的目的,而 SqlSessionFactoryBuilder 的构建过程正是如此。
链式调用是建造者模式的一种常见表现形式,它使得建造者模式的代码更加简洁和易于理解。 链式调用具体实现:如何让对象支持链式调用?
3.单例模式
单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一,此模式保证某个类在运行期间,只有一个实例对外提供服务,而这个类被称为单例类。
单例模式也比较好理解,比如一个人一生当中只能有一个真实的身份证号,每个收费站的窗口都只能一辆车子一辆车子的经过,类似的场景都是属于单例模式。单例模式在 MyBatis 中的典型代表是 ErrorContext。
ErrorContext 是线程级别的的单例,每个线程中有一个此对象的单例,用于记录该线程的执行环境的错误信息。
4.适配器模式 适配器模式是指将一个不兼容的接口转换成另一个可以兼容的接口,这样就可以使那些不兼容的类可以一起工作。 例如,最早之前我们用的耳机都是圆形的,而现在大多数的耳机和电源都统一成了方形的 typec 接口,那之前的圆形耳机就不能使用了,只能买一个适配器把圆形接口转化成方形的,如下图所示:
而这个转换头就相当于程序中的适配器模式,适配器模式在 MyBatis 中的典型代表是 Log。
MyBatis 中的日志模块适配了以下多种日志类型:
- SLF4J
- Apache Commons Logging
- Log4j2
- Log4j
- JDK logging
5.代理模式
代理模式指的是给某一个对象提供一个代理对象,并由代理对象控制原对象的调用。
代理模式在生活中也比较常见,比如我们常见的超市、小卖店其实都是一个个“代理”,他们的最上游是一个个生产厂家,他们这些代理负责把厂家生产出来的产品卖出去。
代理模式在 MyBatis 中的典型代表是 MapperProxyFactory。
MapperProxyFactory 的 newInstance() 方法就是生成一个具体的代理来实现某个功能。
6.模板方法模式
模板方法模式是最常用的设计模式之一,它是指定义一个操作算法的骨架,而将一些步骤的实现延迟到子类中去实现,使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。此模式是基于继承的思想实现代码复用的。
例如,我们喝茶的一般步骤都是这样的:
- 把热水烧开
- 把茶叶放入壶中
- 等待一分钟左右
- 把茶倒入杯子中
- 喝茶
整个过程都是固定的,唯一变的就是泡入茶叶种类的不同,比如今天喝的是绿茶,明天可能喝的是红茶,那么我们就可以把流程定义为一个模板,而把茶叶的种类延伸到子类中去实现,这就是模板方法的实现思路。
模板方法在 MyBatis 中的典型代表是 BaseExecutor,在 MyBatis 中 BaseExecutor 实现了大部分 SQL 执行的逻辑。
7.装饰器模式
装饰器模式允许向一个现有的对象添加新的功能,同时又不改变其结构,这种类型的设计模式属于结构型模式,它是作为现有类的一个包装。
装饰器模式在生活中很常见,比如装修房子,我们在不改变房子结构的同时,给房子添加了很多的点缀;比如安装了天然气报警器,增加了热水器等附加的功能都属于装饰器模式。
装饰器模式在 MyBatis 中的典型代表是 Cache。
Cache 除了有数据存储和缓存的基本功能外(由 PerpetualCache 永久缓存实现),还有其他附加的 Cache 类,比如先进先出的 FifoCache、最近最少使用的 LruCache 等众多附加功能的缓存类。
# JVM
# JVM是如何运行的?
JVM 的执行流程如下:
- 程序在执行之前先要把 Java 代码转换成字节码(class 文件),JVM 首先需要把字节码通过一定的方式类加载器(ClassLoader) 把文件加载到内存中运行时数据区(Runtime Data Area)。
- 但字节码文件是 JVM 的一套指令集规范,并不能直接交给底层操作系统去执行,因此需要特定的命令解析器,也就是 JVM 的执行引擎(Execution Engine)会将字节码翻译成底层系统指令再交由 CPU 去执行。
- 在执行的过程中,也需要调用其他语言的接口,如通过调用本地库接口(Native Interface) 来实现整个程序的运行,如下图所示:
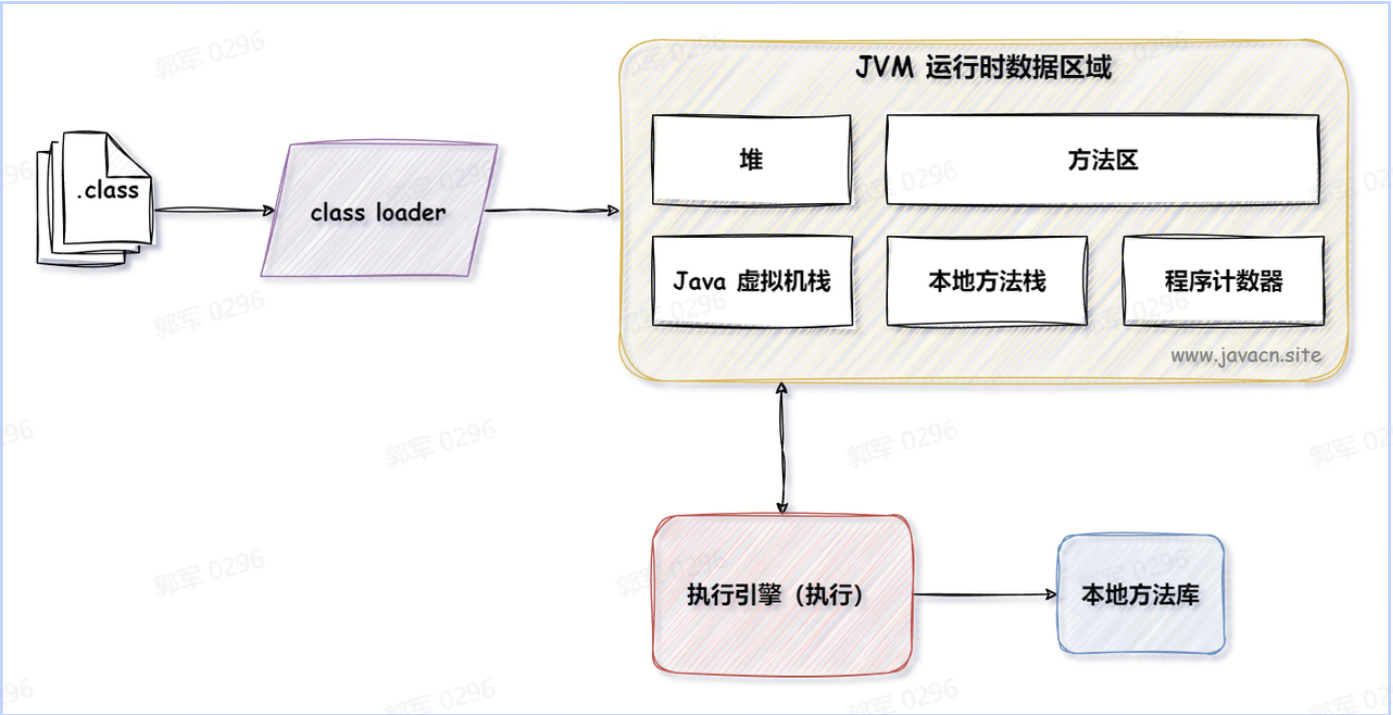 所以,整体来看, JVM 主要通过分为以下 4 个部分来执行 Java 程序的:
所以,整体来看, JVM 主要通过分为以下 4 个部分来执行 Java 程序的:
- 类加载器(ClassLoader)
- 运行时数据区(Runtime Data Area)
- 执行引擎(Execution Engine)
- 本地库接口(Native Interface)
# Java是编译性语言还是解释性语言?
编译性语言和解释性语言区别如下:
编译性语言是指在程序执行之前,先经过编译器的处理,将源代码转换为目标机器可执行的二进制机器码,然后直接执行。因此编译过程只需进行一次,生成的可执行文件可以重复运行。
- 优点:执行效率高。
- 缺点:编译时间长、跨平台能力有限。
解释性语言不需要事先编译成机器码,而是在运行时由解释器将源代码逐行解释执行。例如 JavaScript 语言就是解释性语言。
- 优点:跨平台性较好、无需编译。
- 缺点:执行效率低、不易保护源代码。
而 Java 语言既不完全属于编译性语言,又不完全属于解释性语言,Java 属于半编译语言,也叫编译-解释型语言,其执行过程包含编译和解释两个阶段。
- 编译阶段:Java 源代码(.java文件)通过 Java 编译器编译成字节码文件(.class 文件)。字节码是一种中间语言,它具有平台无关性,可以在任何支持 Java 虚拟机(JVM)的平台上运行。
- 解释阶段:当程序运行时,Java 虚拟机会加载字节码,并对其进行解释执行或即时编译(Just-In-Time Compilation, JIT)执行。现代 JVM 普遍采用 JIT 技术,会根据代码热点将频繁执行的字节码动态编译成本地机器指令以提高性能。
# 为什么需要将 java 代码编译成字节码(.class)?
Java 代码需要编译成字节码(.class文件)的原因主要有以下几点:
- 跨平台执行:将 Java 代码编译成字节码,可以使不同平台下的 Java 虚拟机(JVM)识别,从而根据平台特性,生成不同平台的二级制机器码进行执行,这样就实现了跨平台的作用。
- 代码检查:编译器在编译阶段会对代码进行类型检查,确保代码的类型安全性,让我们提前发现一些潜在的错误,例如类型不匹配、缺少方法等问题。
- 动态加载和扩展:将 Java 代码编译成字节码可以动态的扩展一些功能,例如 Lombok 插件的 @Getter 和 @Setter 方法就是在编译器进行字节码生成的。
- 高效执行:字节码是一种中间表示形式,相比于原始的源代码,可提供更高效的执行和优化。JVM 会通过即时编译等技术将字节码转换成机器码,以提高程序的执行速度。
- 代码保护:编译后的字节码是一种经过转换的形式,与原始的源代码相比,更难以直接理解。这可以提供一定程度的代码保护,使得源代码的逻辑和实现细节难以被逆向工程或恶意修改。
# 说一下JVM的内存布局?
通常所说的 JVM 内存布局,通常是指 JVM 运行时数据区(Runtime Data Area),也就是当字节码被类加载器加载之后的执行区域划分。
《Java 虚拟机规范》中将 JVM 运行时数据区域划分为以下 5 部分:
- 程序计数器(Program Counter Register):用于存储当前线程执行的字节码指令的地址,在多线程环境中,程序计数器用于实现线程切换,保证线程恢复执行时能够继续从正确的位置执行代码。
- Java 虚拟机栈(Java Virtual Machine Stacks):用于存储方法调用和局部变量(方法内部定义的变量),在方法调用和返回时,虚拟机栈用于保存方法的调用帧,包括方法的局部变量、操作数栈、方法返回地址等。
- 本地方法栈(Native Method Stack):与虚拟机栈类似,本地方法栈用于执行本地(Native)方法。
- Java 堆(Java Heap):JVM 中最大的一块内存区域,用于存储对象实例,所有的对象都在堆中分配内存。
- 方法区(Methed Area):用于存储类的元数据信息,包括类的结构、字段、方法、静态变量、常量池等。
如下图所示:

# Java虚拟机规范和Java虚拟机有什么关系?
它们一个是 JVM 规范,一个是针对规范的实现产品,具体来说:
- Java 虚拟机规范(JVM Specification)是 Sun Microsystems 公司(现为 Oracle 公司)制定的一套详细的文档,它定义了 Java 虚拟机的内部工作原理、结构、指令集、数据类型、内存区域、垃圾收集、类文件格式、加载和执行机制等具体规则,这些规则是 Java 平台实现兼容性和可移植性的基础。
- Java 虚拟机(Java Virtual Machine, JVM)则是根据上述规范实现的具体软件系统,它是一个实际运行在物理硬件上的程序,负责装载并执行 Java 字节码。任何符合 Java 虚拟机规范的 JVM 都可以正确解释和执行标准的 Java 字节码,从而确保 Java 代码的“一次编写,到处运行”的特性。
因此,Java 虚拟机规范与 Java 虚拟机的关系可以理解为规范与实现的关系。规范描述了所有 Java 虚拟机应遵循的标准和约定,而各种不同的 Java 虚拟机则是按照该规范进行设计和实现的具体产品。例如,HotSpot JVM 就是由 Oracle 开发的一款广泛使用的 Java 虚拟机的默认实现。
# 方法区、永久代和元空间有什么区别?
方法区、永久代和元空间的区别如下:
- 方法区:《Java 虚拟机规范》定义的一个内存区域,用于存储已被虚拟机加载的类信息、常量池、静态变量、即时编译器编译后的代码等数据的地方。
- 永久代:HotSpot JVM 对方法区的一种实现方式,它曾经用来存储类的元数据和字符串常量池等内容。随着 Java 版本的演进,永久代的设计暴露出了一些问题,例如空间大小固定且难以管理,容易导致如“Out of Memory”的异常问题。
- 元空间:HotSpot JVM 在 JDK 1.8 及更高版本中,对方法区新的实现方式(替代了原来的永久代)。相比于永久代,元空间的主要改进包括:
- 空间分配方式:元空间使用的是本地内存(Native Memory),而非堆内存的一部分,因此不会受到堆内存大小限制的影响。
- 动态调整:元空间的大小可以动态调整,并且默认情况下类的元数据分配只受限于可用的本地内存大小,从而避免了因预设固定大小而导致的内存溢出问题。
- 字符串常量池位置改动:在 JDK 1.7 之后,字符串常量池被移到了 Java 堆中,进一步降低了永久代或元空间的压力。
所以说,方法区是一个规范层面的概念,而永久代是早期 HotSpot JVM 对方法区的具体实现方式,现已废弃;而元空间则是后来 HotSpot 为了改进内存管理,和解决永久代带来的内存溢出问题所采用的新的实现机制。
# 为什么要使用元空间替代永久代?元空间有什么优点?
关于这个问题,官方在 JEP(JDK Enhancement Proposal,JDK 改进提案)122: Remove the Permanent Generation(移除永久代)中给出了答案,原文内容如下:
Motivation(动机) This is part of the JRockit and Hotspot convergence effort. JRockit customers do not need to configure the permanent generation (since JRockit does not have a permanent generation) and are accustomed to not configuring the permanent generation.
以上内容翻译成中文大意是:
这是 JRockit 虚拟机和 HotSpot 虚拟机融合工作的一部分。JRockit 客户不需要配置永久层代(因为 JRockit 没有永久代),所以要移除永久代。
JRockit 是 Java 官方收购的一家号称史上运行最快的 Java 虚拟机厂商,之后 Java 官方在 JDK 8 时将 JRockit 虚拟机和 HotSpot 虚拟机进行了整合。
PS:JEP 是 JDK Enhancement Proposal 的缩写,翻译成中文是 JDK 改进提案。你也可以把它理解为 JDK 的更新文档。
通过官方的描述,我们似乎找到了答案,也就是说,之所以要取消“永久代”是因为 Java 官方收购了 JRockit,之后在将 JRockit 和 HotSpot 进行整合时,因为 JRockit 中没有“永久代”,所以把永久代给移除了。
元空间有什么优点?
元空间的主要优点有以下两个。
- ① 降低 OOM
当使用永久代实现方法区时,永久代的最大容量受制于 PermSize 和 MaxPermSize 参数设置的大小,而这两个参数的大小又很难确定,因为在程序运行时需要加载多少类是很难估算的,如果这两个参数设置的过小就会频繁的触发 FullGC 和导致 OOM(Out of Memory,内存溢出)。 但是,当使用元空间替代了永久代之后,出现 OOM 的几率就被大大降低了,因为元空间使用的是本地内存,这样元空间的大小就只和本地内存的大小有关了,从而大大降低了 OOM 的问题。
- ② 降低运维成本
因为元空间使用的是本地内存,这样就无需运维人员再去专门设置和调整元空间的大小了。
# **常量池和字符串常量池有什么区别?字符串常量池是如何实现的? **
常量池(Constant Pool)和字符串常量池(String Constant Pool)是 Java 中的两个不同概念,它们的区别有以下几个方面:
- JDK 1.8 及以后的版本中,字符串常量池存储在堆上,而常量池在元空间本地内存中。
- 常量池包含更多的内容,如类、方法、字段等常量都存放在常量池中,而字符串常量池只是用于存储字符串常量对象。
Java 中常量类的定义:
// 常量类 public final class MyConstants { // 常量字段 public static final int MAX_VALUE = 100; // 字符串常量 public static final String DEFAULT_NAME = "磊哥"; }字符串常量池是如何实现的?
以 Hotspot 虚拟机来说,字符串常量池是由 C++ 的 HashMap 实现的,它的 key 是字符串的字面量,value 是字符串对象的引用,如下图所示:
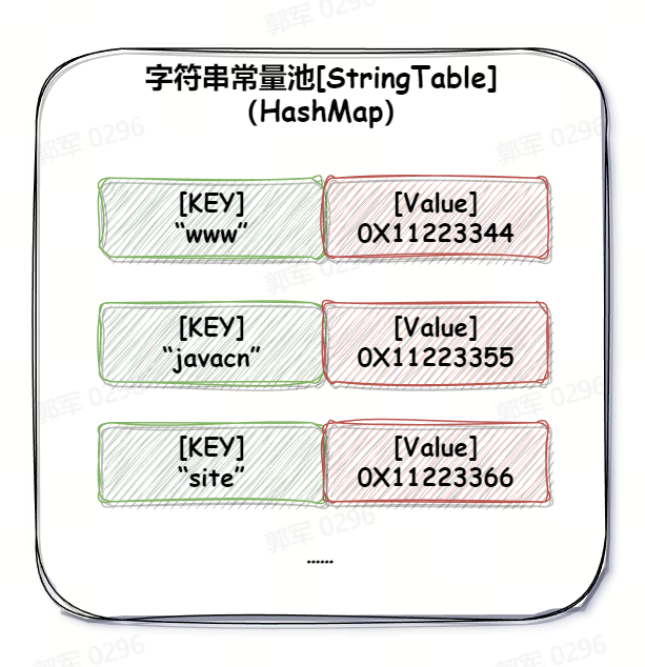
# 什么叫做堆溢出?实际工作中哪些情况会导致堆溢出?
堆溢出(Heap Overflow)通常是指堆内存中的对象过多、无法被垃圾回收所导致的内存溢出错误。
以下是一些常见的导致堆溢出的场景和原因:
- 内存泄漏:最常见的情况是内存泄漏,即对象被创建后不再被使用,但没有被释放。这会导致堆中的对象数量逐渐增加,直到堆溢出。例如 ThreadLocal 使用不当,使用完成之后未调用 remove 方法导致内存泄漏,以及忘记释放各种连接,也会导致内存泄漏,如数据库连接、网络连接和 IO 连接等。
- 无限递归创建大量对象:无限递归调用一个方法可能会导致栈溢出,但如果递归方法中创建了大量对象并持续递归,也可能导致堆溢出。
- 创建大量大对象:创建大量大对象,尤其是数组或集合,可能导致堆溢出。如果没有足够的连续内存来存储大对象,堆溢出会发生。
- 未合理设置堆大小:如果未合理设置 Java 虚拟机的堆大小参数(如 -Xmx 和 -Xms),可能导致堆溢出。
- Excel 导入和导出:如果有大的 excel 要进行导入和导出的情况下,因为其操作都是在内存中拼接和组织数据的,如果 excel 过大,很容易就会造成 Heap OOM。
# 什么叫做栈溢出?导致栈溢出的原因是啥?
栈溢出(Stack Overflow)是指在程序运行时,当栈空间中的可用内存大小被超出所能容纳的限制时,导致发生异常或错误的情况。
导致栈(Java 虚拟机栈)溢出最常见的情况就是死循环和无限递归,方法自己调自己,这样 Java 虚拟机栈就会只入栈不出栈,当到达 Java 虚拟机栈的最大数之后就会出现 StackOverflowError 异常,如下代码所示:
public class StackOOMExample { public static void main(String[] args) { main(args); } }以上程序执行结果如下:

栈溢出场景
日常工作中导致栈溢出的情况有以下这些:
- 递归调用:在递归算法中,如果递归的深度过大,每次递归都会在栈中生成一个函数调用的帧,当栈空间不足以容纳这些帧时,就会发生栈溢出。解决方法是通过优化递归算法,使用循环或迭代代替递归,或者增加栈的大小。
- 无限递归:在某些情况下,由于代码逻辑错误或循环调用,可能会导致无限递归的情况发生,从而导致栈溢出。解决方法是检查代码逻辑,确保递归或循环调用能够正常结束或有适当的终止条件。
- 大规模数据结构使用:当使用大规模的数据结构(如大数组、大集合等)时,如果栈空间不够容纳这些数据,就可能导致栈溢出。解决方法是尽量使用堆空间存储大规模数据结构,或者增加栈的大小。
- 深度嵌套函数调用:当函数调用过于深层嵌套时,每次调用都会在栈中生成一个新的函数帧,如果嵌套层级过多,就有可能导致栈溢出。解决方法是优化代码结构,减少函数的嵌套层级。
# 说一下类加载机制?Loading和Class Loading有什么区别?
类加载机制是 Java 虚拟机将类字节码加载到内存并转换为可执行类的过程,该机制总共包括以下几个步骤:
- 加载
- 验证
- 准备
- 解析
- 初始化
具体内容如下。
① 加载
加载(Loading)阶段是整个“类加载”(Class Loading)过程中的一个阶段,它和类加载 Class Loading 是不同的,一个是加载 Loading 另一个是类加载 Class Loading,所以不要把二者搞混了。
在加载 Loading 阶段,Java 虚拟机需要完成以下 3 件事:
- 通过一个类的全限定名来获取定义此类的二进制字节流。
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
- 在内存中生成一个代表这个类的 java.lang.Class 对象,作为方法区这个类的各种数据的访问入口。
② 验证
验证是连接阶段的第一步,这一阶段的目的是确保 Class 文件的字节流中包含的信息符合《Java虚拟机规范》的全部约束要求,保证这些信 息被当作代码运行后不会危害虚拟机自身的安全。
验证选项:
- 文件格式验证
- 字节码验证
- 符号引用验证...
③ 准备
准备阶段是正式为类中定义的变量(即静态变量,被 static 修饰的变量)分配内存并设置类变量初始值的阶段。
比如此时有这样一行代码:
public static int value = 123;
它是初始化 value 的 int 值为 0,而非 123。
④ 解析 解析阶段是 Java 虚拟机将常量池内的符号引用替换为直接引用的过程,也就是初始化常量的过程。
也就是说这个阶段会涉及到以下三个概念:
- 符号引用:类文件中的一种抽象引用方式,它并不涉及具体的内存地址或对象实例。符号引用包括了三个方面的信息:类和接口的全限定名、字段的名称和描述符、方法的名称和描述符。这些信息足够唯一地确定一个类、字段或者方法,但在类被加载到 JVM 之前,并没有与实际的内存布局关联。
- 直接引用:一种可以直接指向目标对象、类、字段或者方法在 JVM 内存中的物理位置的引用方式,例如指针、偏移量等。一旦有了直接引用,就可以直接访问目标实体,而无需再经过其他查找过程。
- 替换过程:当 JVM 在解析阶段需要对某个符号引用进行解析时,会根据类加载的结果生成对应的直接引用。比如,当一个类引用了另一个类的方法或字段时,解析阶段会确保被引用的目标类已经被加载,并计算出被引用方法或字段在内存中的准确位置,然后用这个位置信息替换掉原来的符号引用。
⑤ 初始化
初始化阶段,Java 虚拟机真正开始执行类中编写的 Java 程序代码,将主导权移交给应用程序。初始化阶段就是执行类构造器方法的过程,当然初始化阶段也会执行静态初始化块和静态字段的初始化赋值的操作。
# 什么是双亲委派模型?为什么要用双亲委派模型?
双亲委派模型指的是:当一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到最顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去完成加载。
自 JDK 1.2 以来,Java 一直保持着三层类加载器、双亲委派的类加载架构器,如下图所示:

其中:
- 启动类加载器:加载 JDK 中 lib 目录中 Java 的核心类库,即 $JAVA_HOME/lib 目录。
- 扩展类加载器:加载 lib/ext 目录下的类。
- 应用程序类加载器:加载我们写的应用程序。
- 自定义类加载器:根据自己的需求定制类加载器。
为什么要用双亲委派模型?
因为使用双亲委派模型,有以下几个优点:
- 避免重复加载类:比如 A 类和 B 类都有一个父类 C 类,那么当 A 启动时就会将 C 类加载起来,那么在 B 类进行加载时就不需要在重复加载 C 类了。
- 更安全:使用双亲委派模型也可以保证了 Java 的核心 API 不被篡改,如果没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 java.lang.Object 类的话,那么程序运行的时候,系统就会出现多个不同的 Object 类,而有些 Object 类又是用户自己提供的因此安全性就不能得到保证了。
# 有哪些打破双亲委派模型的场景?为什么要打破双亲委派模型?
打破双亲委派模型的场景主要有以下两个:
- Java 自带的 SPI 机制。
- Tomcat
具体内容如下。
① SPI 机制
SPI(Service Provider Interface)是 JDK 内置的一种服务提供发现机制。例如,数据库驱动就是 SPI 的典型实现。在 Java 中,数据库驱动就是一个典型的 SPI 使用场景。不同的数据库厂商都提供了自己的数据库驱动实现,这些实现都实现了同一个 JDBC 接口。JVM 在运行时可以动态加载适合的数据库驱动,使得开发者可以在不修改代码的情况下切换不同的数据库。
② Tomcat
Tomcat 也要打破了双亲委派模型,因为一个外置 Tomcat 中要部署多个应用,多个 Web 应用程序在同一个 Tomcat 实例中独立运行,而不会相互干扰或导致类冲突,所以 Tomcat 需要打破双亲委派模型来实现类隔离、热部署和解决类库版本冲突等问题。
- 类隔离:应用服务器通常需要在同一 JVM 中运行多个不同的 Web 应用程序,每个应用程序都可能依赖于不同版本的类库。为了保持这些应用程序的隔离性,Tomcat 需要使用自定义的类加载器来加载各个 Web 应用程序的类。这样可以确保每个 Web 应用程序都不会干扰其他应用程序的类加载。
- 热部署和热加载:Tomcat 支持热部署(Hot Deployment)和热加载(Hot Reloading),允许在应用程序运行时替换类文件而不需要重新启动整个应用服务器。为了实现这一功能,Tomcat 需要自己的类加载器,以便能够动态加载新的类定义。
- 类库版本冲突:有时 Web 应用程序需要使用自己的类库版本,而不是应用服务器提供的全局类库版本。这可能会导致类库版本冲突,为了解决这个问题,Tomcat 可以使用自定义的类加载器来加载应用程序的类,而不受全局类库的影响。
为什么要打破双亲委派模型?
- SPI 要打破了 Java 类加载器的双亲委派模型,主要是为了实现服务提供者框架的设计目标和灵活性。
- Tomcat 要打破了双亲委派模型,是为了让多个 Web 应用程序在同一个 Tomcat 实例中独立运行,避免相互干扰或类冲突等问题。
# 判断死亡对象的算法有哪些?
判断对象是否存活的常见的算法有以下两种:
- 引用计数算法
- 可达性分析算法
它们的介绍和优缺点如下。
① 引用计数器算法
引用计数器算法的实现思路是,给对象增加一个引用计数器,每当有一个地方引用它时,计数器就 +1;当引用失效时,计数器就 -1;任何时刻计数器为 0 的对象就是不能再被使用的,即对象已"死"。
- 引用计数法的优点:实现简单,判定效率也比较高。
- 引用计数法的缺点:是引用计数法无法解决对象的循环引用问题。
② 可达性分析算法
可达性分析算法是通过一系列称为"GC Roots"的对象作为起始点,从这些节点开始向下搜索,搜索走过的路径称之为"引用链",当一个对象到 GC Roots 没有任何的引用链相连时(从 GC Roots 到这个对象不可达)时,证明此对象是不可用的,也就是死亡对象。
 对象 Object5-Object7 之间虽然彼此还有关联,但是它们到 GC Roots 是不可达的,因此它们会被判定为可回收对象。
对象 Object5-Object7 之间虽然彼此还有关联,但是它们到 GC Roots 是不可达的,因此它们会被判定为可回收对象。目前主流的 Java 虚拟机使用的都是可达性分析算法来判断死亡对象的。
# 什么对象可以作为GC Roots?为什么它们能作为GC Roots?
在 Java 语言中,可作为 GC Roots 的对象有以下几种:
- Java 虚拟机栈(栈帧中的本地变量表)中引用的对象。
- 本地方法栈中(Native 方法)引用的对象。
- 方法区中类静态属性引用的对象。
- 方法区中常量引用的对象。
其中,Java 虚拟机栈和本地方法栈中的引用对象,是目前线程正在执行时用的对象,所以它们不能被回收,因此它们可以作为 GC Roots。而方法区中的静态属性和常量对象与类本身相关联,而类已经被加载到程序中了,所以类属于系统的一部分了,因此类所关联的静态属性和常量也就是系统的一部分了,所以它们可以作为 GC Roots。
# Java中的引用类型有哪些?这些引用类型对应的使用场景有哪些?为什么要有这么多的引用类型?
Java 将“引用”分为:强引用(Strong Reference)、软引用(Soft Reference)、弱引用(Weak Reference)和虚引用(Phantom Reference)四种,这四种引用的强度依次递减,具体内容如下:
强引用:强引用指的是在程序代码之中普遍存在的,类似于"Object obj = new Object()"这类的引用,只要强引用还存在,垃圾回收器永远不会回收掉被引用的对象实例。
- 使用场景:日常开发中使用 new XXX() 创建的所有对象都是强引用。
软引用:软引用是用来描述一些还有用但是不是必须的对象。对于软引用关联着的对象,在系统将要发生内存溢出之前,会把这些对象列入回收范围之中进行第二次回收。如果这次回收还是没有足够的内存,才会抛出内存溢出异常。在 JDK1.2 之后,提供了 SoftReference 类来实现软引用。
- 使用场景:软引用通常用来实现内存敏感的缓存,如果还有空闲内存,就可以暂时保留缓存,当内存不足时清理掉,这样就保证了使用缓存的同时,不会耗尽内存。
弱引用:弱引用也是用来描述非必需对象的,它的强度要弱于软引用。被弱引用关联的对象只能生存到下一次垃圾回收发生之前。当垃圾回收器开始进行工作时,无论当前内容是否够用,都会回收掉只被弱引用关联的对象。在 JDK1.2 之后提供了 WeakReference 类来实现弱引用。
- 使用场景:维护一种非强制性的映射关系,如果试图获取时对象还在,就使用它,否则重新实例化。例如 ThreadLocal 中的 ThreadLocalMap 使用的就是弱引用,来它来尽量避免内存泄漏。
虚引用:虚引用也被称为幽灵引用或者幻影引用,你不能通过它访问对象。幻象引用仅仅是提供了一种确保对象被 finalize 以后,做某些事情的机制。
- 使用场景:有人使用虚引用监控对象的创建和销毁。
为什么要有这么多的引用类型?
这些引用类型为 Java 程序提供了一种更加精细的内存管理手段,使得开发者可以根据应用程序的具体需求来调整对象生命周期,特别是在处理大量数据缓存、资源管理和防止内存泄漏等场景时显得尤为重要。
# Java中的垃圾回收算法有哪些?它们各自有哪些优缺点?
Java 中常见垃圾回收算法有以下几个:
标记-清除算法:"标记-清除"算法是最基础的收集算法。算法分为"标记"和"清除"两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象,如下图所示:
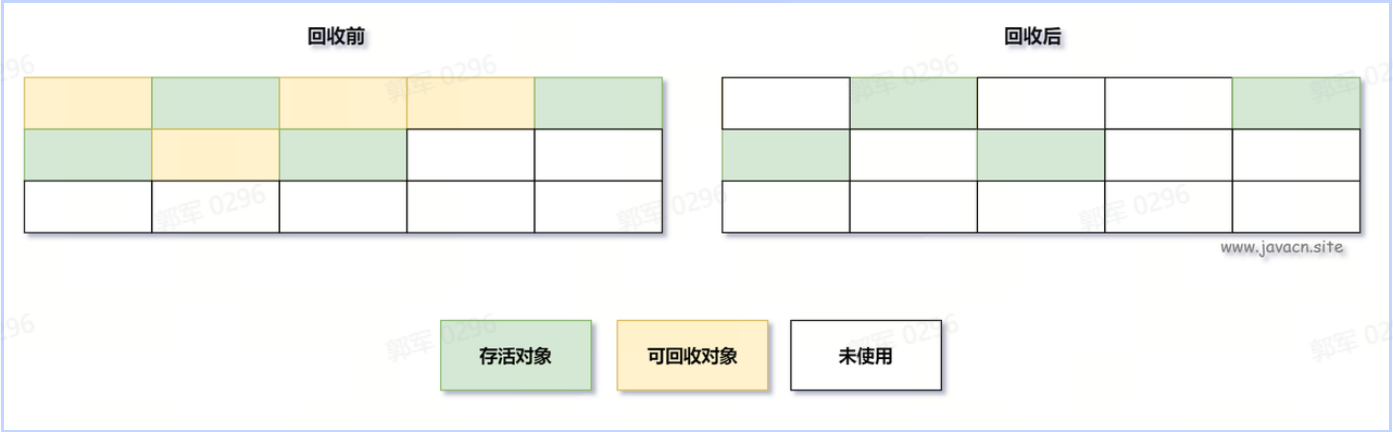
- 优点:实现简单、且执行效率相对高效。
- 缺点:会产生内存碎片问题,在标记清除后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行中需要分配较大对象时,无法找到足够连续内存而不得不提前触发另一次垃圾收集。
标记-整理算法:标记-整理算法也是分为两个阶段“标记”和“整理”,其中标记仍与标记-清除算法的“标记”过程实现是一致的,但后续步骤不是直接对可回收对象进行清理,而是让所有存活对象都向一端移动,然后直接清理掉端边界以外的内存,如下图所示:
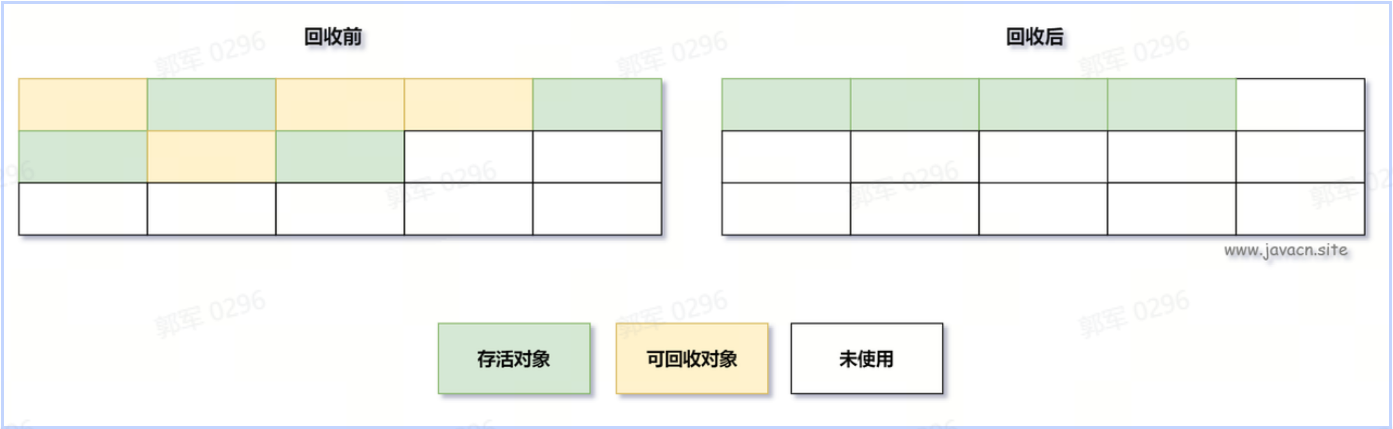
- 优点:无内存碎片问题。
- 缺点:执行效率比较低。
复制算法:"复制"算法是为了解决"标记-整理"的效率问题,将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这块内存需要进行垃圾回收时,会将此区域还存活着的对象复制到另一块上面, 然后再把已经使用过的内存区域一次清理掉。这样做的好处是每次都是对整个半区进行内存回收,内存分配时也就不需要考虑内存碎片等复杂情况,只需要移动堆顶指针,按顺序分配即可。此算法实现简单,运行高效。
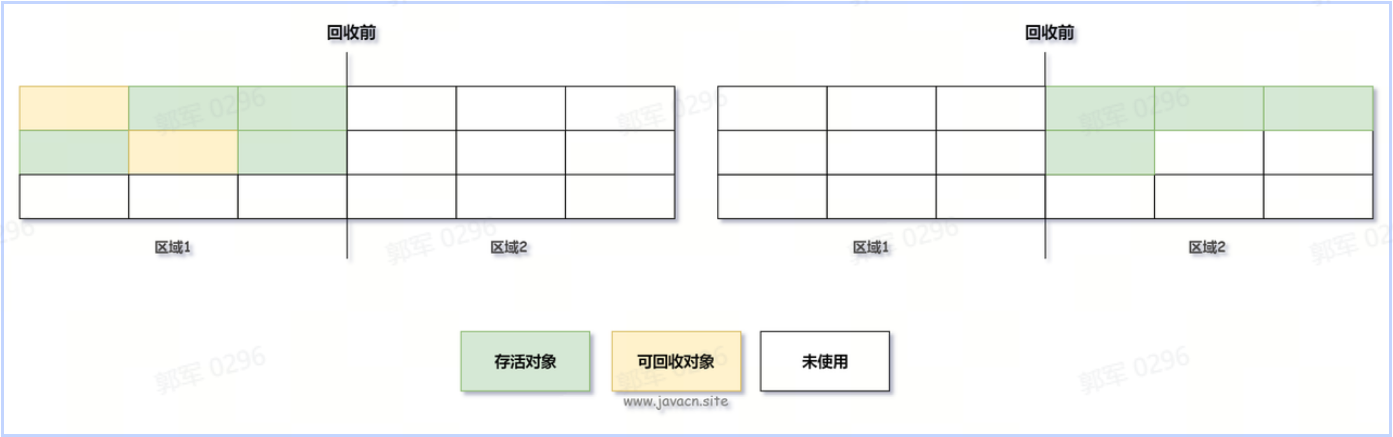
- 优点:执行效率高。
- 缺点:空间利用率比较低。
分代算法:分代算法是通过区域划分,实现不同区域和不同的垃圾回收策略,从而实现更好的垃圾回收。这就好比中国的一国两制方针一样,对于不同的情况和地域设置更符合当地的规则,从而实现更好的管理,这就时分代算法的设计思想。
- 优点:分而治之,不同场景使用不同算法,整体性能更高,且空间利用率较好。
- 缺点:实现复杂度比较高。
# JVM中的常见垃圾回收器有哪些?
VM 常见的垃圾回收器有以下几个:
- Serial/Serial Old:单线程垃圾回收器。
- ParNew:多线程的垃圾回收器(Serial 多线程版本)。
- Parallel Scavenge/Parallel Old:吞吐量优先的垃圾回收器【JDK8 默认的垃圾回收器】。
- CMS:最小等待时间优先的垃圾收集器。
- G1:可控垃圾回收时间的垃圾收集器【JDK 9~JDK 21 HotSpot 默认的垃圾回收器】
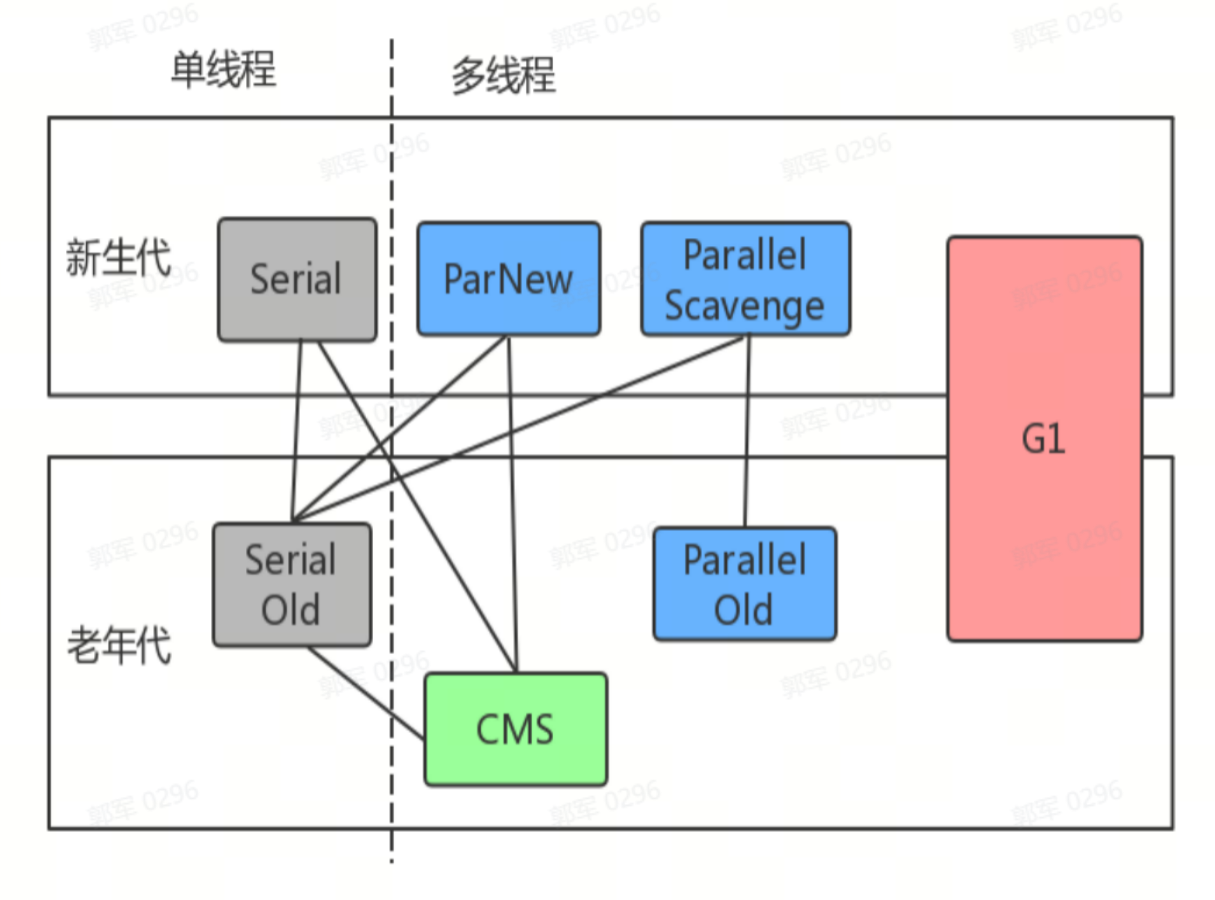
# CMS垃圾回收器有什么优缺点?它使用了什么算法?
CMS(Concurrent Mark Sweep,并发标记清理)回收器是一种以获取最短回收停顿时间为目标的收集器。目前很大一部分的 Java 应用集中在互联网站或者 B/S 系统的服务端上,这类应用尤其重视服务的响应速度,希望系统停顿时间最短,以给用户带来较好的体验,CMS 收集器就非常符合这类应用的需求。
优缺点分析
CMS 优点如下:
- 低延迟。
- 并发收集。
CMS 缺点如下:
- 产生内存碎片:因为 CMS 使用的是“标记-清除”算法,所以会产生内存碎片。
- CPU 资源敏感:因为垃圾回收时虽然不会 STW,但会占用用户线程的 CPU 资源,如果用户线程本身的 CPU 资源已经很吃紧了,那么此时再使用 CMS 无疑是雪上加爽。
# CMS如何解决内存碎片问题?它能使用标记-整理算法吗?为什么?
CMS 并不能直接解决内存碎片的问题,因为 CMS 使用的标记-清除算法。但是当内存碎片比较多时(连续内存不不足以申请大对象时),CMS 会借助 Serial Old 垃圾收集器执行内存碎片的回收工作,因为 Serial Old 使用的是标记-整理算法,所以内存碎片问题就得到了解决。
CMS能使用标记-整理算法吗?为什么?
CMS 不能使用标记-整理算法,这是因为 CMS 最后一个阶段是并发清除阶段,此阶段 CMS 垃圾回收会和用户线程并发执行,如果使用并发-整理算法需要移动内存位置,而此时用户线程正在执行,所以不能使用并发-整理算法,如下图所示:
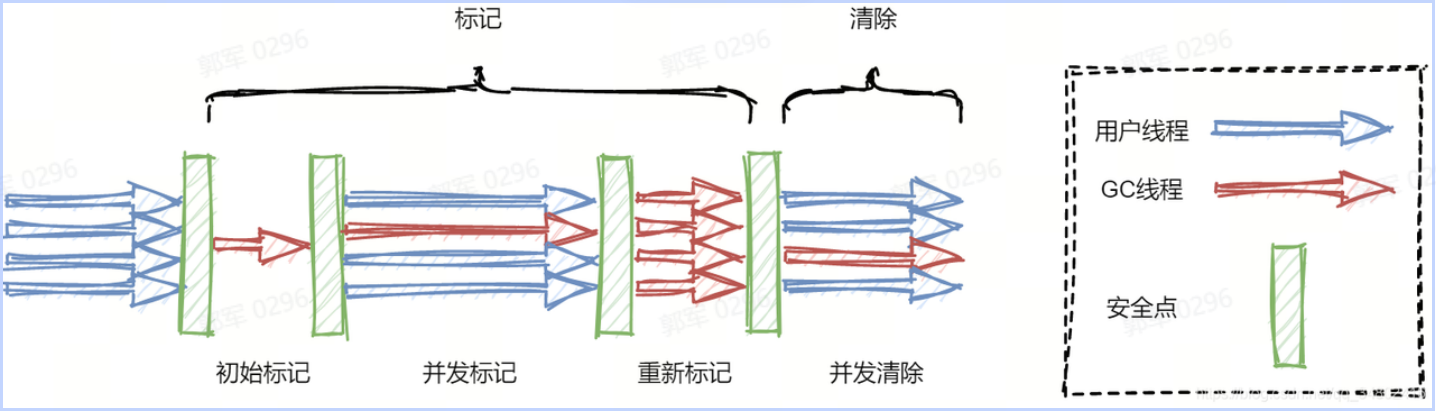
# 说一下CMS执行流程?它需要全局停顿(STW)几次?
CMS 执行流程总共分为以下 4 个阶段:
- 初始标记(STW):GC Roots 能直接关联到的对象,执行速度很快。
- 并发标记(和用户线程并发执行):GC Roots 直接关联的对象继续往下(一直)遍历和标记,耗时会长比较长。
- 重新标记(STW):对上一步并发标记阶段,因为用户线程执行而导致变动的对象进行修正标记。
- 并发清除(和用户线程并发执行):使用并发-清除算法将垃圾对象进行清除。
如下图所示:
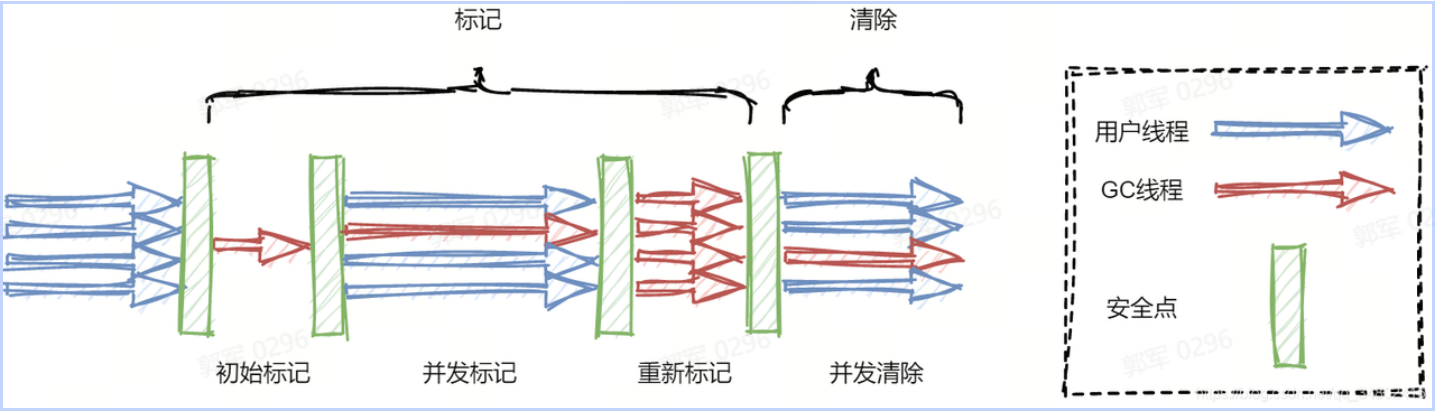
CMS 需要全局停顿(STW)几次?
CMS 只有在初始标记和重新标记的时候需要全局停顿(STW),因此它在垃圾回收时,只有 2 次全局停顿。
# Old GC和Full GC有什么区别?JVM中的垃圾回收类型还有哪些?
Old GC 是老年代垃圾回收,而 Full GC 是全局垃圾回收,它们的区别如下:
- Old GC(老年代垃圾回收):Old GC 也被称为 Major GC,它主要针对的是老年代内存区域进行垃圾回收。当老年代内存空间不足,或者从新生代晋升的对象过多导致老年代无法容纳时,会发生 Old GC。Old GC 的发生频率低于新生代 GC,但是其执行时间通常比新生代 GC 长得多。
- Full GC(全局垃圾回收或完全垃圾回收):Full GC 是对整个堆内存(包括年轻代和老年代)、方法区进行全面的垃圾回收。发生 Full GC 的情况较为复杂,例如:老年代空间不足、元空间不足、System.gc() 显式调用(不推荐)、CMS 并发标记失败后 fallback 到 Serial Old 收集器等。Full GC 的开销非常大,因为它涉及到了 JVM 几乎所有的内存区域,因此应尽量避免不必要的 Full GC,以减少系统停顿时间。
除了 Old GC 和 Full GC 之外,还有新生代垃圾回收 Minor GC,它的具体内容如下:
- Minor GC(新生代垃圾回收):Minor GC 是针对新生代内存区域的垃圾回收。新生代内存区域通常被划分为 Eden 区、Survivor0 和 Survivor1 区。当 Eden 区空间不足时,或者 Survivor 区满但无法容纳更多的对象时,会触发 Minor GC,Minor GC 相对频繁且执行速度较快。
所以说:Full GC = Minor GC + Major GC + 方法区 GC。
# JVM有哪些优化手段?说说JIT和逃逸分析?
JVM 优化手段主要有以下几个:
- JIT(Just-In-Time,即时编译):是一种在程序运行时将部分热点代码编译成机器代码的技术,以提高程序的执行性能的机制。
- 逃逸分析:用于确定对象动态作用域是否超过当前方法或线程,通过逃逸分析,编译器可以决定一个对象的作用范围,从而进行相应的优化,但确定对象没有逃逸时,可以进行以下优化:
- 栈上分配:如果编译器可以确定一个对象不会逃逸出方法,它可以将对象分配在栈上而不是堆上。在栈上分配的对象在方法返回后就会自动销毁,不需要进行垃圾回收,提高了程序的执行效率。
- 锁消除:如果对象只在单线程中使用,那么同步锁可能会被消除,提高程序性能。
- 标量替换:将原本需要分配在堆上的对象拆解成若干个基础数据类型存储在栈上,进一步减少堆空间的使用。
- 字符串池(String Pool)优化:JVM 通过共享字符串常量,重用字符串对象,以减少内存占用和提升字符串操作的性能。
JIT和热点代码
JIT 优点包括以下几个:
- 性能优化:由于编译成本地机器代码,程序的执行速度通常比解释性执行或预编译的代码要快得多。
- 平台无关性:JIT 编译器可以根据不同的硬件平台生成不同的机器代码,使得相同的程序可以在不同的计算机上运行,而无需重新编写。
什么是热点代码?
在 HotSpot 虚拟机中,热点代码(Hot Code)是指那些被频繁执行的代码。
热点代码的执行次数在不同的 JDK 版本和不同的 JVM 中是不同的,例如,它在 JDK 21 Client 模式下为 1500 次,Server 模式下为 10000 次,这个值可以通过 JVM 参数设置。
通常来说,热点代码的识别基于以下两种策略:
- 方法调用次数:当一个方法被调用一定次数后,会被视为热点代码并触发即时编译。这个次数在不同 JDK 版本中可能有所变化,并且可以通过 JVM 参数 -XX:CompileThreshold 进行设置。
- 回边计数:对于循环体等热点区域,通过统计从循环体返回到循环条件检查点的次数(即回边次数),达到一定次数也会触发即时编译。同样,这个阈值也可以通过 JVM 参数 -XX:OnStackReplacePercentage 进行设置。回边计数器有一个计算公式【回边计数器阈值=方法调用计数器阈值 * (OnStackReplacePercentage - InterpreterProfilePercentage)】,通过计算,在 JDK 21 Server 模式下,虚拟机回边计数器的阈值为 10700【10000*(140-33)】。
可以使用 java -XX:+PrintFlagsFinal -version 命令查看 JVM 默认配置。
栈上分配 VS 标量替换
栈上分配和标量替换是编译器的两种优化技术,它们虽然有一些相似之处,但并不完全相同。
- 栈上分配(Stack Allocation):一种优化技术,它将对象分配在栈上而不是堆上。这种技术适用于编译器可以确定对象不会逃逸出方法,并且对象的生命周期在方法内部结束的情况。通过在栈上分配对象,可以避免在堆上进行内存分配和垃圾回收的开销,从而提高程序的性能和内存使用效率。
- 标量替换(Scalar Replacement):与栈上分配类似,也是一种优化技术。它将一个复杂对象拆分成独立的成员变量,使其成为基本类型或基本类型数组的局部变量。这种技术适用于编译器可以确定对象的成员变量不会逃逸的情况。标量替换可以提供更细粒度的控制,使得编译器可以对独立的成员变量进行更精细的优化,例如寄存器分配和代码优化。
也就是说栈上分配,只是将对象从堆上分配到栈上了;而标量替换是更进一步的优化技术,将对象拆解成基本类型分配到栈上了。
锁消除代码演示
锁消除(Lock Elimination)也叫做同步消除,是一种编译器优化技术,它可以消除对于变量的不必要的锁定操作。锁消除的目的是减少锁的开销,提高程序的性能。
例如以下代码:
public void method() { Object lock = new Object(); synchronized(lock){ System.out.println("www.javacn.site"); } }而锁消除之后的代码如下:
public void method(){ System.out.println("www.javacn.site"); }标量替换代码演示
未优化前的代码如下:
private static class Point { private int x; private int y; } public static void main(String[] args) { Point point = createPoint(10, 20); int sum = point.x + point.y; System.out.println("Sum: " + sum); } private static Point createPoint(int x, int y) { Point point = new Point(); point.x = x; point.y = y; return point; }标量替换优化后的代码如下:
public static void main(String[] args) { int x = 10; int y = 20; int sum = x + y; System.out.println("Sum: " + sum); }通过逃逸分析的优化能够减少垃圾回收的压力、减少内存分配和释放带来的性能损耗,并且有可能减少对锁的依赖,以及实现标量替换等,从而整体上提升了应用程序的运行效率。
# G1是如何分区的?
G1 总共有以下 4 块区域:
- Eden(伊甸园区):新创建对象都会放在此区域。
- Survivor(存活区):eden 经过 GC 之后存活的对象就会移动到此区域。
- Old(老年代):经过 n 次 GC 之后还存活的对象就会放到此区域。
- Humongous(巨型区):用来存放大对象的,大对象会直接存放到此区域,当一个对象的大小超过 Region 的一半时(50%),则该对象定义为大对象。
如下图所示:
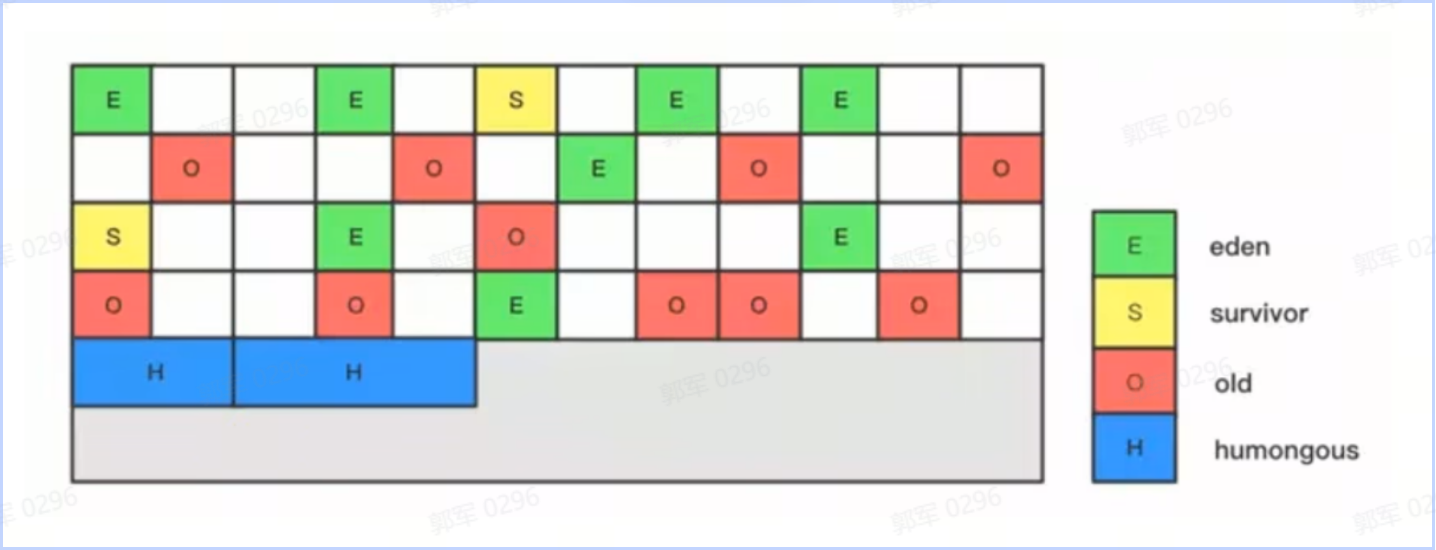
# G1和CMS有什么区别?
G1(Garbage-First)垃圾收集器和 CMS(Concurrent Mark Sweep)垃圾收集器都是 HotSpot 虚拟机中的最常用的垃圾收集器,它们的主要区别如下:
设计目标不同:
- G1 垃圾收集器的设计目标是为了解决大内存系统上长时间 STW(Stop-The-World)停顿的问题,并且提供了可预测的停顿时间模型。
- CMS 垃圾收集器同样致力于减少垃圾回收时的停顿时间,但其主要关注点在于尽可能缩短老年代 GC 的停顿时间。
垃圾收集器分类不同:
- G1 将整个堆划分为多个大小相等的 Region,每个 Region 可以属于 Eden、Survivor 或老年代。它是整体垃圾收集器(新生代+老年代)。
- CMS 是分代垃圾收集器,它属于老年代的垃圾收集器。
垃圾回收流程不同:
- G1 的垃圾回收包括初始标记、并发标记、最终标记、清理以及混合回收阶段。它采用全局标记-局部回收的方式,每次 GC 只回收一部分 Region(被称为回收集),并在回收过程中尽量避免全堆扫描。
- CMS 的垃圾回收过程包括初始标记、并发标记、重新标记和并发清除四个阶段。它主要关注对年轻代的并发收集,而对老年代的并发标记和清除可能导致浮动垃圾产生。
停顿预测与控制不同:
- G1 允许用户设置一个期望的最大暂停时间(MaxGCPauseMillis),并尽力满足这个要求。在进行垃圾回收时,G1 会优先回收收益高的 Region,即垃圾多的 Region,因此得名“Garbage-First”。
- CMS 虽然也努力减少停顿时间,但并未提供明确的停顿时间预测和控制功能。
内存碎片和使用垃圾回收算法不同:
- G1 从整体上看是基于“标记-整理”算法实现的,从局部看是基于“标记-复制”算法实现的,所以 G1 没有内存碎片的问题。
- CMS 使用的是标记-清除算法实现的,所以它存在内存碎片的问题。
综上所述,G1 垃圾收集器相比于 CMS,不仅延续了降低停顿时间的目标,还引入了更灵活的堆管理方式以及对停顿时间的预测和控制能力,从而更适合现代大型复杂应用的需求。从 JDK 9 开始,G1 成为了默认的垃圾收集器,并逐步取代了 CMS 的位置。
# 网络模块
# 什么是TCP/IP五层模型?它们的作用是啥?基于TCP/IP实现的应用(层协议)有哪些?
TCP/IP 五层模型,从上层往下层分别是:
- 应用层:应用程序本身,应用层的作用是负责应用程序间的数据通讯的。不同的网络应用需要不同的应用层协议,比如电子邮件传输 SMTP 协议、文件传输 FTP 协议、网络远程访问 Telnet 协议等等。
- 传输层:传输层的主要作用是负责两台主机间(从源地址到目的地)的数据传输的。如传输控制协议 (TCP),能够确保数据可靠的从源主机发送到目标主机。
- 网络层:网络层的作用是负责网络上的地址管理和路由选择的。在数据通讯时,可以选择很多条路径(抵达目的地的),比如从西安到北京,可以选择先从西安 -> 太原 -> 北京,也可以选择从西安 -> 郑州 -> 石家庄 -> 北京,还可以选择从西安 -> 延安 -> 呼和浩特 -> 张家口 -> 北京,究竟选择那一条路呢?这就是网络层负责的。
- 数据链路层:数据链路层的作用是负责设备之间的数据帧的传送和识别的。数据在传输时需要经过多个设备进行数据传输,而数据链路层就是负责相邻设备间的数据传输和识别的。数据链路层可以完全消除网络层和物理层之间的不同,将数据在链路层进行有效的识别和传输。
- 物理层:物理层的作用是负责将数据转换成信号,再将信号转换为数据的。转换方法因通讯媒体不同而不同,所以没有特定的协议。
如下图所示:
使用TCP/IP实现的应用有哪些?
网络上的大部分通讯协议都是基于 TCP/IP 模型实现的,例如以下这些常见的应用层(上层)协议:
- HTTP(Hypertext Transfer Protocol):一种用于传输超文本的协议,常用于 Web 应用程序的通信。
- HTTPS(HTTP Secure):基于 TLS/SSL 安全协议对 HTTP 进行加密和身份验证,用于保护 Web 通信的安全性。
- FTP(File Transfer Protocol):用于在网络上传输文件的协议,提供文件上传、下载、删除等功能。
- SMTP(Simple Mail Transfer Protocol):用于电子邮件传输的协议,负责发送电子邮件到邮件服务器。
- SSH (Secure Shell): 提供了安全远程登录和其他安全网络服务的协议。
# 说一下DNS的执行流程?
DNS(Domain Name System,域名解析系统)用于将域名转换为 IP 地址,以便设备访问互联网资源。
因为在网络中,访问服务是依靠 IP 进行查找和定位的,因此使用 URL 访问的第一步,是先要得到服务器端的 IP 地址,而得到服务器的 IP 地址需要使用 DNS(Domain Name System,域名系统)域名解析,DNS 域名解析就是通过 URL 找到与之相对应的 IP 地址。
为什么不直接访问 IP 地址来请求服务器? 答:使用 IP 地址也能直接访问程序,但由于 IP 地址很长,不方便记忆,而 URL 地址好记很多,所以会使用 URL 来替代 IP 地址,而 URL 就像 IP 地址的别名一样,用它可以定位到相应的 IP 地址。
DNS 解析流程
DNS 域名解析的流程如下:
- 客户端发送域名解析请求:当用户在浏览器中输入一个域名时,浏览器首先查找本地缓存,看是否有该域名对应的 IP 地址记录。
- 系统缓存查询:如果浏览器本地缓存未命中,则操作系统会检查其自身的 DNS 缓存,看看是否已经存储了该域名的解析结果。
- 本地 DNS 缓存查找(本地网络运营商):操作系统缓存也未命中时,客户端向本地 DNS 服务器发送 DNS 查询请求。本地 DNS 解析器首先检查自己的缓存,看是否已经有了与域名对应的 IP 地址。如果有,解析过程直接结束,直接返回 IP 地址给客户端。
- 本地 DNS 服务器查询:如果本地 DNS 缓存中没有相关记录,解析器会向根域名服务器发送请求,询问它们掌握该域名服务器的 IP 地址。
- 根域名服务器指向顶级域名服务器:根域名服务器将返回顶级域名服务器(比如 .com、.net 等)的 IP 地址给本地 DNS 服务器。
- 顶级域名服务器查询:本地 DNS 服务器继续向顶级域名服务器发送请求,询问该域名服务器是否知道目标域名对应的 IP 地址。
- 顶级域名服务器指向权威域名服务器:如果顶级域名服务器得到了目标域名对应的权限域名服务器(Authoritative Name Server)的 IP 地址,它会将该 IP 地址返回给本地 DNS 服务器。
- 权威域名服务器查询:本地 DNS 服务器再次向权限域名服务器发送请求,询问该域名对应的 IP 地址。
- 权威域名服务器回复:权限域名服务器将目标域名对应的 IP 地址返回给本地 DNS 服务器。
- 本地 DNS 服务器缓存记录:本地 DNS 服务器将该记录添加到自己的缓存中,以备下次查询。
- 本地 DNS 服务器回复客户端:本地 DNS 服务器将目标域名对应的 IP 地址返回给客户端。
- 客户端发起连接:客户端通过获得的 IP 地址建立与目标主机的连接,开始进行数据传输。
通过这样的 DNS 解析流程,客户端能够获取到域名对应的 IP 地址,从而在网络上找到目标主机并进行连接。DNS 的解析过程中涉及到多个层次的域名服务器协同工作,以提供高效的域名解析服务。
根域名服务器、顶级域名服务器和权威域名服务器有什么区别?
答:根域名服务器在整个 DNS 体系中起着导航作用,帮助其他 DNS 服务器找到正确路径;顶级域名服务器针对某一类顶级域名进行管理;而权威域名服务器则具体负责某个域名区域内的详细信息解析工作,它们的关系如图所示:
# 在浏览器中输入URL地址之后会执行哪些流程?
URL(Uniform Resource Locator,统一资源定位符)是互联网上用来标识资源的地址。URL 执行流程是指从用户在浏览器中输入一个URL,到页面内容最终呈现在用户面前的整个过程,它执行流程如下:
- 用户输入 URL:用户在浏览器地址栏中键入或粘贴一个 URL,如 https://www.javacn.site。
- DNS 解析:浏览器首先检查本地 DNS 缓存是否有该域名对应的 IP 地址。如果没有,则向本地 DNS 服务器发送 DNS 查询请求。本地 DNS 服务器如果不知道该域名对应的 IP 地址,将依次询问根域名服务器、顶级域名服务器、权威 DNS 服务器,并获取目标网站服务器的 IP 地址。
- TCP 连接:获取到目标服务器的 IP 地址后,浏览器建立与该服务器的 TCP 连接,默认使用 HTTP 协议的 80 端口或 HTTPS 协议的 443 端口。
- 发起 HTTP 请求:通过已建立的 TCP 连接,浏览器构造并发送 HTTP 请求报文给服务器。在这个例子中,请求方法可能是 GET,请求头包含 Host(主机名)、User-Agent(浏览器信息)等字段。
- 服务器处理请求:服务器接收到请求后,根据请求内容调用相应的服务程序进行处理。如果是静态文件请求,直接读取文件并返回;如果是动态请求,可能会触发后端应用逻辑处理,比如查询数据库,生成 HTML 页面等。
- 响应数据传输:服务器完成处理后,构建 HTTP 响应报文,其中包括状态码(如 200 表示成功)、响应头(Content-Type、Set-Cookie 等)和响应体(网页内容)。然后将这个响应报文通过 TCP 连接发回给浏览器。
- 渲染页面:浏览器接收到响应报文后,解析响应头并根据 Content-Type 决定如何处理响应体。如果是 HTML 文档,则开始解析 HTML 代码,并下载其中引用的 CSS 样式表、JavaScript 脚本、图片等资源。浏览器逐步渲染页面元素,直至页面完全加载完毕并展示在用户眼前。
- 连接关闭:在 HTTP/1.x 协议中,一般情况下每个请求结束后都会关闭 TCP 连接(除非启用了 Keep-Alive 特性)。而在 HTTP/2 及后续版本中,通常会保持长连接以复用同一 TCP 通道发送多个请求,提高效率。
# GET请求和POST请求有什么区别?POST请求更安全吗?
GET 请求和 POST 请求都是 HTTP 协议中最常见的两种请求方法,但它们它们存在以下几点区别:
- 数据传递方式不同:GET 请求是将参数放在 URL 地址中的,并以键值对的形式发送给服务器端,如: https://www.javacn.site?param1=value1¶m2=value2,因此,GET 请求的数据会在 URL 中可见,且在浏览器历史记录中可见;POST 请求将参数放在请求体(body)中进行传输,以键值对或者其他复杂的数据格式(如 JSON 格式)发送给服务器。
- 参数长度限制不同:GET 请求的参数是通过 URL 传递的,而 URL 的长度是有限制的,通常为 2k,当然浏览器厂商不同、版本不同这个限制的大小值可能也不同,但相同的是它们都会对 URL 的大小进行限制;而 POST 请求参数是存放在请求正文(request body)中的,所以没有大小限制。
- 回退和刷新不同:GET 请求可以直接进行回退和刷新,不会对用户和程序产生任何影响;而 POST 请求如果直接回滚和刷新将会把数据再次提交。
- 缓存不同:GET 请求一般会被缓存(浏览器行为),比如常见的 CSS、JS、HTML 请求等都会被缓存;而 POST 请求默认是不进行缓存的。
- 使用场景不同:GET 请求适合用于获取资源的信息,比如查看网页、获取图片等查询操作;POST 请求适合用于向服务器提交数据并产生副作用的操作,比如提交表单、上传文件等数据提交操作。
POST请求比GET请求更安全吗?
答:严格意义上来说 POST 和 GET 只是属于不同的请求类型,没有所谓的谁安全谁不安全这一说,我们通常所说的 POST 更安全主要体现在:GET 请求是将请求的参数放在 URL 上传递的,所以不借助任何工具都能看到明文的传输参数,而 POST 通常是将参数放在 body 请求体中传输的,所以从视觉方面来说,好像 POST 更安全一些。
但稍微懂一些抓包和劫持的技术,无论是 GET 请求还是 POST 请求,只要是 HTTP 协议,都是不安全的,所以严格意义上来说,只能说 POST 隐私性相对于 GET 来说要好一点点而已,安全性方面并没有本质上的区别。
# 301和302有什么区别?为什么不建议使用302?
301 和 302 都是用于请求重定向的状态码,所谓的请求重定向是指访问某个 URL 时,会自动跳转到另一个 URL。
但是它们,一个表示请求的资源已经被永久性(301)移动到了另一个位置,而 302 只是临时性的移动到了另一个位置,客户端应该通过重定向到新的位置来获取资源。
它们主要区别如下:
- 行为不同:当服务器返回 301 状态码时,表示请求的资源已经永久性地移动到了新的位置;当服务器返回 302 状态码时,表示请求的资源暂时性地移动到了新的位置。
- 后续操作不同:客户端在收到 301 响应后,后续应该更新书签或链接,将原来的 URL 替换为新的 URL,并且以后的请求都应该直接使用新的 URL 来获取资源;客户端在收到 302 响应后,后续应该继续使用原来的 URL 来请求资源,而不是直接使用新的 URL。
- 搜索引擎处理不同:搜索引擎通常会将 301 重定向视为对新 URL 的引用,将之前的 URL 的搜索排名改为新的 URL;搜索引擎通常不会将 302 重定向视为对新 URL 的引用,不会将之前的 URL 的搜索排名传递给新的 URL。
为什么不建议使用 302?
302 状态码本身并没有直接的危害,但在某些情况下可能会引发一些问题和安全隐患:
- SEO 问题:如果网站频繁使用 302 重定向,搜索引擎可能会对网站的排名和索引产生负面影响。由于 302 表示临时重定向,搜索引擎会将原始 URL 与重定向目标 URL 视为不同的页面,造成链接的分散和重复索引。
- 用户体验问题:302 重定向可能导致页面加载速度变慢,对用户体验产生负面影响。每次发生重定向,都会增加一次请求和响应的网络开销,延迟页面的加载时间。
- 安全性问题:恶意攻击者可以利用 302 重定向进行网络钓鱼攻击或重定向劫持。他们可能会伪造 302 重定向,使用户被重定向到恶意站点,诱导用户泄露敏感信息或下载恶意软件。
# 请求转发和请求重定向有什么区别?举个例子通俗易懂的说明一下
请求转发(Forward)和请求重定向(Redirect)虽然都是 HTTP 服务器,处理客户端请求时进行(页面)跳转的实现方式,但是二者有以下 5 点不同:
- 定义不同。
- 跳转方不同。
- 数据共享不同。
- 最终 URL 地址不同。
- 代码实现不同。
具体内容如下。
① 定义不同
请求转发(Forward):发生在服务端程序内部,当服务器端收到一个客户端的请求之后,会先将请求,转发给目标地址,再将目标地址返回的结果转发给客户端。而客户端对于这一切毫无感知的,这就好比,张三(客户端)找李四(服务器端)借钱,而李四没钱,于是李四又去王五那借钱,并把钱借给了张三,整个过程中张三只借了一次款,剩下的事情都是李四完成的,这就是请求转发。
请求重定向(Redirect):请求重定向指的是服务器端接收到客户端的请求之后,会给客户端返回了一个临时响应头,这个临时响应头中记录了,客户端需要再次发送请求(重定向)的 URL 地址,客户端再收到了地址之后,会将请求发送到新的地址上,这就是请求重定向。这就好像张三(客户端)找李四(服务器端)借钱,李四没钱,于是李四就告诉张三,“我没钱,你去王五那借“,于是张三又去王五家借到了钱,这就是请求重定向。
② 请求方不同
从上面请求转发和请求重定向的定义,我们可以看出:请求转发是服务器端的行为,服务器端代替客户端发送请求,并将结果返回给客户端;而请求重定向是客户端的行为,它们的交互流程,如下图所示:
③ 数据共享不同
请求转发是服务器端实现的,所以整个执行流程中,客户端(浏览器端)只需要发送一次请求,因此整个交互过程中使用的都是同一个 Request 请求对象和一个 Response 响应对象,所以整个请求过程中,请求和返回的数据是共享的;而请求重定向客户端发送两次完全不同的请求,所以两次请求中的数据是不同的。
④ 最终 URL 地址不同
请求转发是服务器端代为请求,再将结果返回给客户端的,所以整个请求的过程中 URL 地址是不变的;而请求重定向是服务器端告诉客户端,“你去另一个地访问去”,所以浏览器会重新再发送一次请求,因此客户端最终显示的 URL 也为最终跳转的地址,而非刚开始请求的地址,所以 URL 地址发生了改变。
⑤ 代码实现不同
在 SpringBoot 中,请求转发的实现代码如下:
@RequestMapping("/fw") public void forward(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { request.getRequestDispatcher("/index.html").forward(request, response); }而请求重定向的实现代码如下:
@RequestMapping("/rt") public void redirect(HttpServletRequest request, HttpServletResponse response) throws IOException { response.sendRedirect("/index.html"); }请求转发和请求重定向遵循的是“字越少,事越大”的原则,“请求转发”的字比较少,它需要代客户端执行跳转;而“请求重定向”字比较多,它啥也不干,只是告诉客户端“你去别的地儿访问”就行了,这就是理解这两个概念的关键。它们的区别主要体现在 5 个点:定义不同、请求方不同、数据共享不同、最终 URL 地址不同、代码实现不同。
举例说明
以借钱为例子:
- 请求转发是张三(客户端)找李四(服务器端)借钱,而李四没钱,于是李四又去王五那借钱,并把钱借给了张三,整个过程中张三只借了一次款,剩下的事情都是李四完成的,这就是请求转发。
- 请求重定向是张三(客户端)找李四(服务器端)借钱,李四没钱,于是李四就告诉张三,“我没钱,你去王五那借“,于是张三又去王五家借到了钱,这就是请求重定向。
# 为什么要使用HTTPS?HTTP存在什么问题?
HTTP 在互联网通信中起着至关重要的作用,但它存在一些安全性和隐私性问题,所以需要使用 HTTPS 来增强网络通信的安全。
HTTP 存在以下主要问题:
- 数据明文传输:HTTP 默认情况下是以明文形式传输数据的,这意味着任何在网络路径上的中间节点(如路由器、代理服务器或黑客)都能够捕获和查看用户发送的所有信息,包括但不限于用户名、密码、信用卡号等敏感信息。
- 缺乏完整性验证:由于 HTTP 不提供数据完整性的校验机制,恶意第三方可以轻易地篡改传输中的数据内容,而接收方无法察觉。
- 身份验证缺失:使用 HTTP 时,不验证通讯方的真实身份,可能会遭到伪装。也就是所谓的“中间人攻击”,即攻击者冒充合法服务器,截取并篡改通信内容。
因此,为了确保数据的安全性和完整性,以及验证通信双方的身份,引入了 HTTPS。
HTTPS 具备以下优点:
- 加密:对客户端与服务器之间的通信内容进行加密,防止数据被窃取和监听。
- 认证:通过证书颁发机构(CA)签发的数字证书来验证服务器的身份,保证用户与正确的服务器建立连接。
- 完整性:通过消息认证码(MAC)或者散列函数对数据进行完整性校验,防止数据在传输过程中被篡改。
# 什么是中间人攻击?如何解决中间人攻击?
中间人攻击指的是,正常情况下本该是客户端和服务端直接进行交互的,但此处冲出来一个“坏人”(中间人),它包含在客户端和服务器端之间,用于盗取和篡改双方通讯的内容,如下图所示:
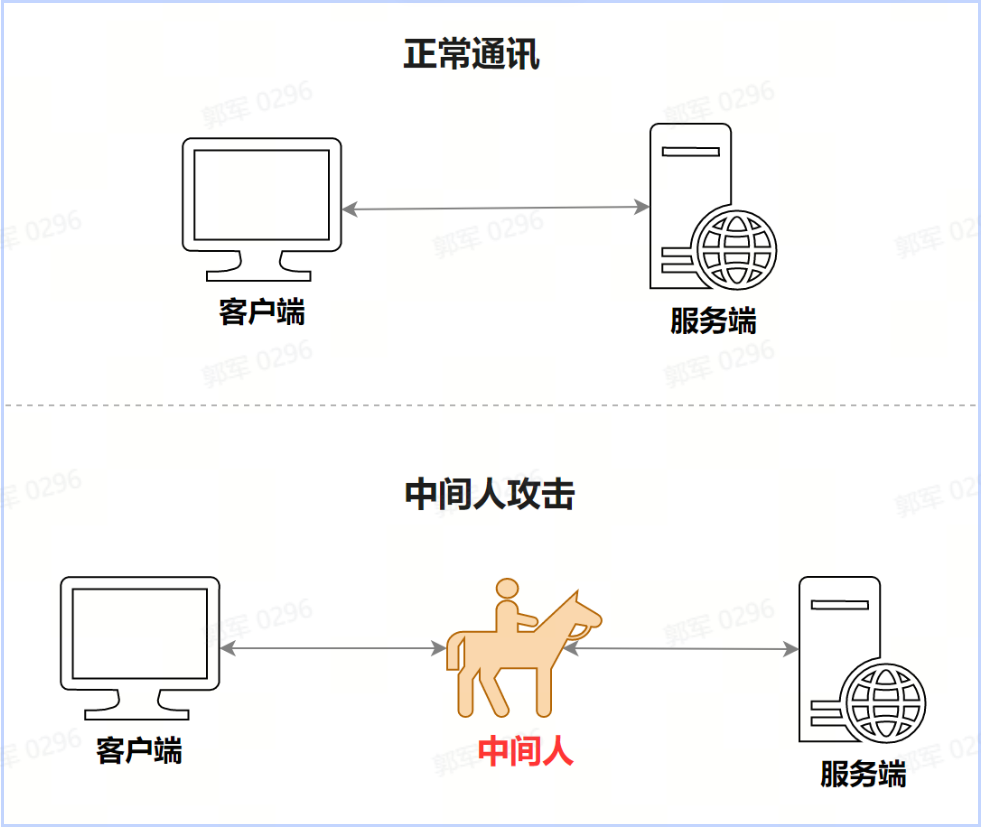
所以说,中间人攻击主要有两个问题:
- 身份认证问题。
- 数据篡改问题。
如何解决中间人攻击?
使用 HTTPS 就可以完美的解决中间人攻击,HTTPS 使用以下两种手段来解决中间人攻击的问题:
- 解决身份认证问题:使用 CA 数字证书。
- 解决数据篡改问题:使用加密通讯。
① CA 数字证书
HTTPS 解决信任问题采用的是数字证书的解决方案,也就是服务器在创建之初,会先向一个大家都认可的第三方平台申请一个可靠的数字证书,然后在客户端访问(服务器端)时,服务器端会先给客户端一个数字证书,以证明自己是一个可靠的服务器端,而非“中间人”。
此时浏览器会负责校验和核对数字证书的有效性,如果数字证书有问题,那么客户端会立即停止通讯,如果没问题才会执行后续的流程,如下图所示:
有了数字证书之后,就可以验证服务器端的真实身份了,这样就解决了“中间人攻击”的问题,也解决了伪装的问题。
② 加密通讯
使用加密通讯之后,第一次通讯的秘钥只有在真正的服务器端保存,所以即使有中间人拦截了信息,因为是密文且自己没有秘钥,那么也是破解不了的,这也解决了中间人攻击的问题。
# 说一下HTTPS执行流程?
HTTPS(Hypertext Transfer Protocol Secure)是一种在 HTTP 协议基础上通过 SSL/TLS 协议提供加密处理和身份认证的网络协议,用于确保通信内容的安全性。
HTTPS 执行流程如下:
客户端请求连接:用户在浏览器中输入 HTTPS 网址并发起连接请求。浏览器验证 URL 合法性,并确定是 HTTPS 请求。
服务器响应并返回 CA 证书:
- 服务器接收到请求后,返回其数字证书(由权威 CA 颁发),其中包含了服务器的身份信息以及公钥。
- 浏览器验证服务器证书的有效性,包括检查证书是否过期、是否由受信任的 CA 签发、域名是否匹配等。
密钥协商与握手阶段:
- 如果证书有效,浏览器生成一个随机数作为会话密钥(对称密钥)的一部分。
- 客户端使用服务器证书中的公钥加密这个会话密钥和其他一些参数(如加密套件、随机数等),然后发送给服务器。
- 这个过程可能涉及到多种握手模式,例如 RSA、DH/ECDH 密钥交换算法等。
共享会话密钥:
- 服务器接收到加密后的信息后,用私钥解密得到会话密钥。
- 此时,客户端和服务端都拥有了同一份会话密钥,但该密钥在网络传输过程中并未明文出现。
数据传输阶段:
- 使用协商好的会话密钥,双方开始使用 TLS/SSL 协议进行对称加密的数据传输。
- 所有的应用层数据(比如 HTTP 请求和响应消息体)都会被这个会话密钥加密,从而保证了数据的机密性和完整性。
完整性校验:在数据传输期间,还会使用哈希算法及消息认证码(MAC)来确保数据未被篡改。
关闭连接:当通信完成后,通过 TLS/SSL 的“四次挥手”或者其他机制安全地结束会话,清理相关资源。
主要流程如下图所示:

什么是加密套件?
加密套件(Cipher Suite)在 HTTPS 中是指一组特定的加密算法组合,它定义了客户端和服务器之间进行安全通信时所使用的各种加密、密钥交换以及消息认证方法。
一个加密套件通常包含以下部分:
- 密钥交换算法(Key Exchange Algorithm):用于协商会话密钥,如 RSA、DH(Diffie-Hellman)、ECDH(Elliptic Curve Diffie-Hellman)等。
- 对称加密算法(Symmetric Encryption Algorithm):用于实际数据传输阶段的加解密,例如 AES(Advanced Encryption Standard)、3DES(Triple Data Encryption Standard)等。
- 消息认证码(Message Authentication Code, MAC)或散列函数:确保数据完整性,如 HMAC-SHA256。
# TCP为什么要三次握手?二次或四次握手行不行?
TCP 三次握手主要是为了保证双方能正常通讯,因为 TCP 发送方和接收方都是全双工的,所以它要保证在通讯之前,双方的发送和接收能力都没问题。
全双工(Full-Duplex)是指数据通信双方能够同时进行收发操作的一种传输模式。在全双工通信中,通信的每一端都能够独立地发送和接收数据,就像双向车道一样,数据可以在两个方向上同时流动,互不影响。
这就好比,打电话,通讯双方都要保证自己能话筒(传递声音)和耳机(接收声音)都是正常的才行,这样才能进行有效的交流,通常打电话时,都是这样开头的:
- 我:喂,能听到我说话吗?
- 对方:能听到你说话,你能听到我说话吗?
- 我:能听到你说话,那我们就来聊正事吧。
TCP 三次握手也是相同的道理,三次握手证明的能力详情如下:

所以,TCP 通讯至少要 3 次握手才行,所以 2 次握手是不行的,而 4 次握手是可以的,但是没有必要(因为 3 次握手已经足够了)。
# TCP丢失的消息会一直重传吗?说一下TCP的超时重传策略是啥?
# 什么是TCP粘包问题?如何解决?
# TCP为什么要四次挥手?说一下四次挥手的流程?
# TCP四次挥手为什么要等两个MSL(最大生存时间)?
# TCP和UDP有什么区别?